







http://blog.csdn.net/zjiang1994/article/details/52779537
注意:经多人告知,慕课网的页面结构已经变了,所以说该案例实际上已经不能达到抓取目的。但是关于scrapy爬虫框架整体的使用方式和流程目前还是正确的,可以进行参考。
scrapy爬虫框架入门实例
关于如何安装scrapy框架,可以参考这篇文章
scrapy安装方法
初识scrapy框架,写个简单的例子帮助理解。
强调一下,这里使用的是Python3.6

例子的目标就是抓取慕课网的课程信息
流程分析
抓取内容
例子要抓取这个网页http://www.imooc.com/course/list
要抓取的内容是全部的课程名称,课程图片,课程人数,课程简介,课程URL
这样的:
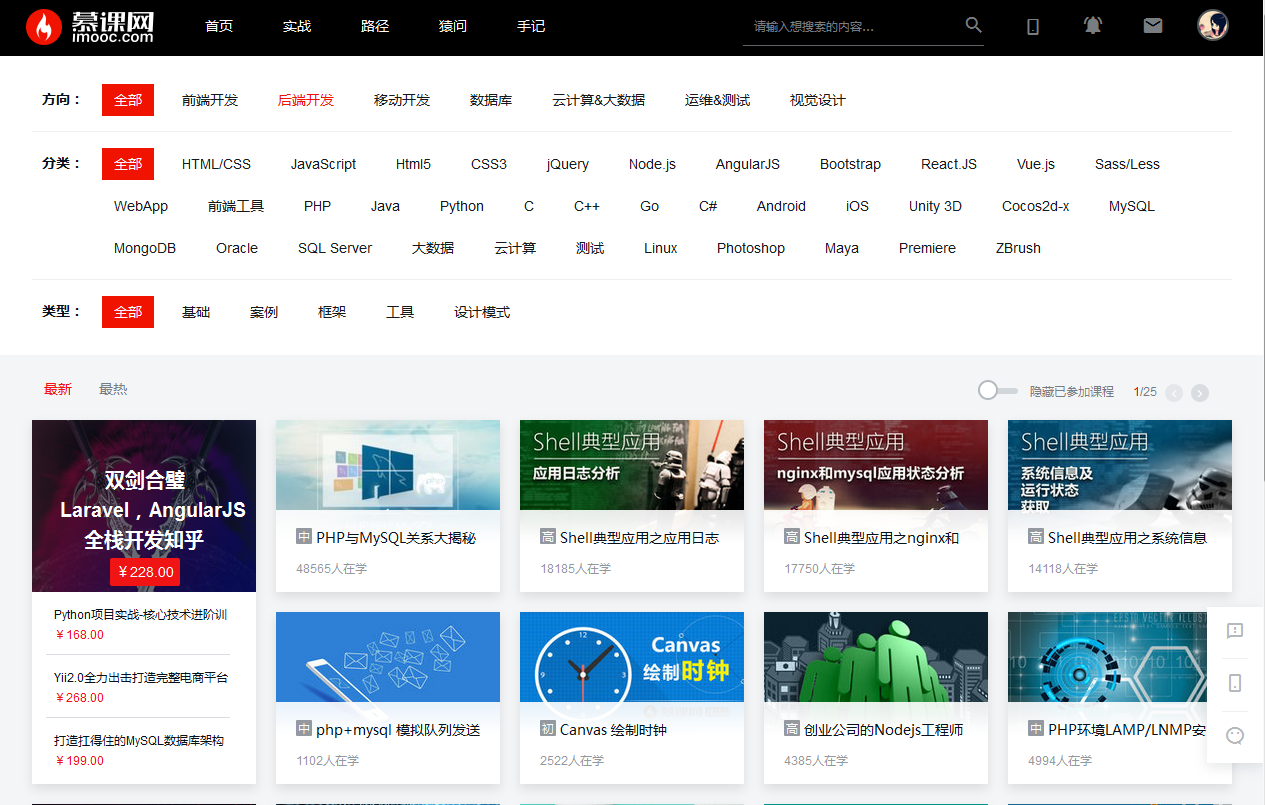
我们要抓取的是这一部分
或者说抓取其中的每一个课程div
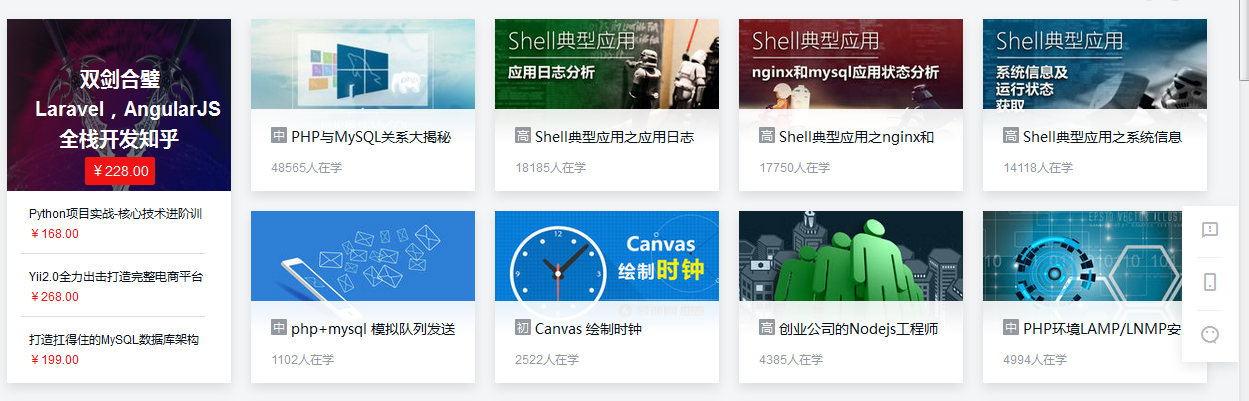
- 1
- 2
通过浏览器的调试工具我们可以看到它们的结构。

所以如果div已经获得的话通过如下获得信息
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
同时,为了抓取全部课程我们还要抓取跟进URL~
这里就不在演示了。
工作流程
Scrapy框架抓取的基本流程是这样(随便画了一下,不要纠结)
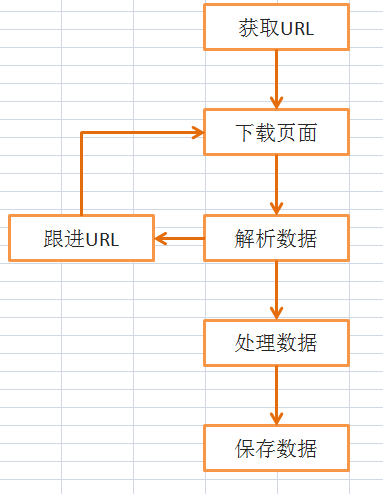
当然了,还有一些中间件等等,这里是入门例子,所以不涉及。
工程建立
在控制台模式下进入你要建立工程的文件夹执行如下命令创建工程
- 1
这里的scrapytest是工程名框架会自动在当前目录下创建一个同名的文件夹,工程文件就在里边。
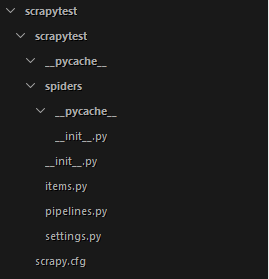
目录分析
目录结构如下图。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
创建一个爬虫
下面按步骤讲解如何编写一个简单的爬虫。
创建爬虫文件
我们要编写爬虫,首先是创建一个Spider
我们在scrapytest/spiders/目录下创建一个文件MySpider.py
文件包含一个MySpider类,它必须继承scrapy.Spider类。
同时它必须定义一下三个属性:
-name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。
-start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
-parse() 是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
创建完成后MySpider.py的代码如下
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
定义爬取项目
创建完了Spider文件,先不急着编写爬取代码
我们先定义一个容器保存要爬取的数据。
这样我们就用到了Item
为了定义常用的输出数据,Scrapy提供了Item类。Item对象是种简单的容器,保存了爬取到得数据。 其提供了 类似于词典(dictionary-like)的API以及用于声明可用字段的简单语法。
我们在工程目录下可以看到一个items文件,我们可以更改这个文件或者创建一个新的文件来定义我们的item。
这里,我们在同一层创建一个新的item文件CourseItems.py
CourseItems.py的代码如下
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
根据如上的代码,我们创建了一个名为courseItem的容器,用来保存、抓取的信息,
title->课程标题, url->课程url, image_url->课程标题图片, introduction->课程描述, student->学习人数
在创建完item文件后我们可以通过类似于词典(dictionary-like)的API以及用于声明可用字段的简单语法。
常用方法如下
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
编写Spider代码
定义了item后我们就能进行爬取部分的工作了。
为了简单清晰,我们先抓取一个页面中的信息。
首先我们编写爬取代码
我们在上文说过,爬取的部分在MySpider类的parse()方法中进行。
parse()方法负责处理response并返回处理的数据以及(/或)跟进的URL。
该方法及其他的Request回调函数必须返回一个包含 Request 及(或) Item 的可迭代的对象。
我们在之前创建的MySpider.py中编写如下代码。
注意和上边MySpider.py的区别
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
注:这里用到了xpath方式来获取页面信息,这里不做过多介绍,可以参考网上的xpath教程来自己学习。
在parse()方法中response参数返回一个下载好的网页信息,我们然后通过xpath来寻找我们需要的信息。
在scrapy框架中,可以使用多种选择器来寻找信息,这里使用的是xpath,同时我们也可以使用BeautifulSoup,lxml等扩展来选择,而且框架本身还提供了一套自己的机制来帮助用户获取信息,就是Selectors。
因为本文只是为了入门所以不做过多解释。
在执行完以上步骤之后,我们可以运行一下爬虫,看看是否出错。
在命令行下进入工程文件夹,然后运行
- 1
如果操作正确会显示如下信息。
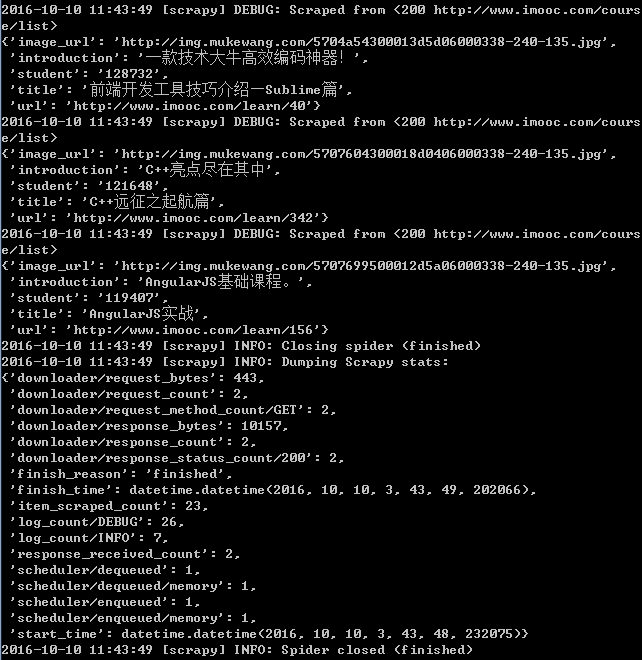
上面信息表示,我们已经获取了信息,接下来我们开始进行信息的储存。
使用Pipeline处理数据
当我们成功获取信息后,要进行信息的验证、储存等工作,这里以储存为例。
当Item在Spider中被收集之后,它将会被传递到Pipeline,一些组件会按照一定的顺序执行对Item的处理。
Pipeline经常进行一下一些操作:
清理HTML数据
验证爬取的数据(检查item包含某些字段)
查重(并丢弃)
将爬取结果保存到数据库中
这里只进行简单的将数据储存在json文件的操作。
首先在scrapytest/目录下建立一个文件MyPipelines.py
MyPipelines.py代码如下
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
要使用Pipeline,首先要注册Pipeline
找到settings.py文件,这个文件时爬虫的配置文件
在其中添加
- 1
- 2
- 3
上面的代码用于注册Pipeline,其中scrapytest.MyPipelines.MyPipeline为你要注册的类,右侧的’1’为该Pipeline的优先级,范围1~1000,越小越先执行。
进行完以上操作,我们的一个最基本的爬取操作就完成了
这时我们再运行
- 1
就可以在项目根目录下发现data.json文件,里面存储着爬取的课程信息。
如下图:

这样一个简单的爬虫就完成了。
扩展完善
上面的代码只进行了比较简单的爬取,并没有完成爬取慕课网全部课程的目标。
下面进行一些简单的扩展完成我们的目标。
url跟进
在上面我们介绍了如何进行简单的单页面爬取,但是我们可以发现慕课网的课程是分布在去多个页面的,所以为了完整的爬取信息课程信息,我们需要进行url跟进。
为了完成这个目标需要对MySpider.py文件进行如下更改
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
修改成功后就可以自动进行url跟进了。
下载图片
在上文我们爬取了慕课网全部的课程信息,但是每个课程的标题图片我们只获得了url并没有下载下了,这里我们进行图片下载的编写。
首先我们在CourseItems.py文件中添加如下属性
- 1
- 2
因为我们要下载图片,所以需要用这个属性用来保存下载地址。
接下来我们需要创建一个Pipeline用来下载图片。
这里我们创建一个ImgPipelines.py
代码如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
这里我们使用的是Scrapy提供的ImagesPipeline,这个pipeline专门进行图片的下载,
这里、主要用到两个方法:get_media_requests() 和item_completed()
get_media_requests(item, info)方法是通过抓取的图片url来返回一个Request,这个Request将对图片进行下载。
在下载请求完成后(下载成功或失败)就会调用item_completed()方法。
item_completed(results, items, info)
方法在下载请求完成后执行.
参数results包含三个项目
- 1
- 2
- 3
- 4
该方法需要返回item供后续操作。
编写完ImgPipelines后照例需要注册一下
- 1
- 2
- 3
- 4
注意这里的顺序,因为我要先下载图片再获得图片的路径,所以应该先处理ImgPipeline再处理MyPipeline,所以说ImgPipeline的数字小一些。
同时,因为是下载图片这里需要注册一下保存地址,还是在settings.py文件
- 1
IMAGES_STORE规定了保存地址,地址自己随意。
这样在运行爬虫就会下载图片了,就像这样
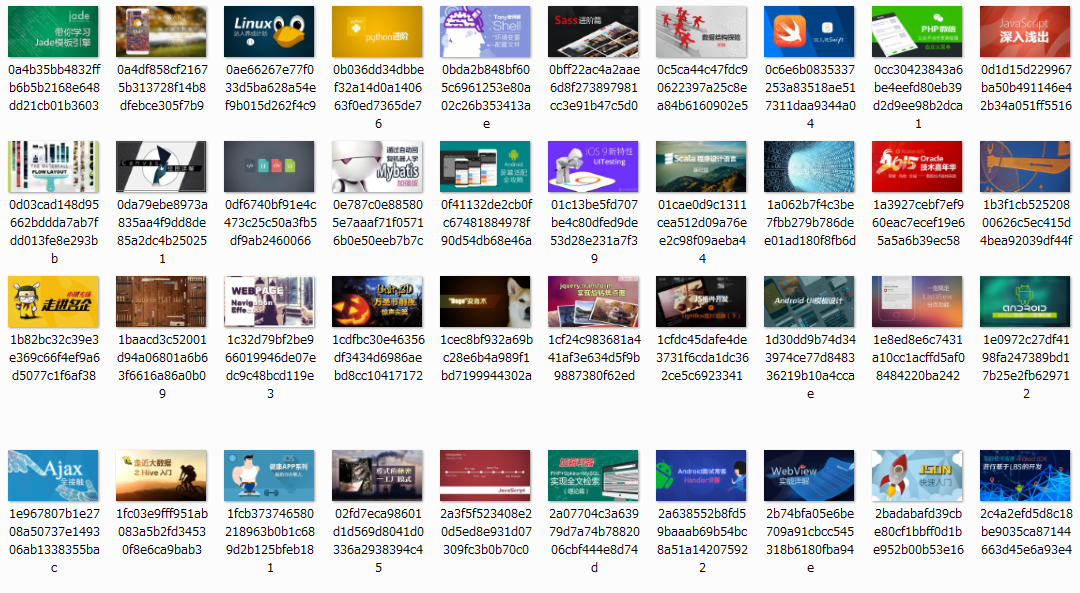
同时注意了,因为要进行下载任务,所以说电脑不好的同学很有可能内存溢出,所以不推荐在pipeline中执行下载等任务,可以在后期处理。如果非要处理的话可以更改CONCURRENT_ITEMS参数减少并发处理item的数量来降低系统开销。
CONCURRENT_ITEMS属性默认为100,就是同时处理100个item可以适当降低,实在不行就是1
总结
把多余的文件删除后的目录结构
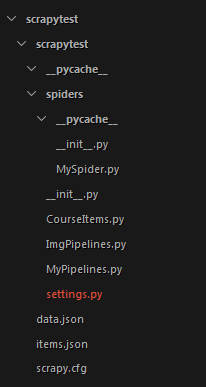
上面的处理结束后我们就成功的抓取了慕课网的全部课程信息了。
以上就是我的Scrapy入门小例子了。如果有看到的希望指出不足。

附上我的代码:scrapy抓取实例















 1649
1649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









