







在EF(Entity Framework)中引入了查询规约 它是配合“仓储模式”查询使用的 实际上仓储模式是用于优化数据库压力的 在很多的时候由于开发人员的问题它所带来的益处比较微妙
那么为什么需要使用规约模式 它主要是用于把复杂查询的问题进行切割细化 随意的组合其查询部分 比如传统的SQL语句 则是一种典型的规约的书面形式
规约故名思意是一种约束性质的东西 但显然规约更多是与查询相关 我时常在想如果不用规约那么我需要实现一个复杂的查询 那个代码我应该如何去续写?我发现真的会有些困难 但是可以确定的只要写好在同等情况下会较之规约模式所生产结果效率更加高效
但 值得一提的在于规约模式依赖与“栈与递归”的方式 即每次“SatisfiedBy”归纳时会递归向上调用整合查询 同时规约模式应最好使用代码缓存 这在于规约模式本身的特性 即每次调用一个规约方法存根(Stub)则生产一个有效的实例对象
不过在“UIA/MSAA”窗体自动化技术内 也引入了规约模式 比如在UIA中检索符合条件的“AutomationElement”你可以使用多个不同的“Condition” 如“AndCondition、OrCondition、PropertyCondition”规约模式可以最大化的提高查询的灵活性与易用性
但频繁的分配对象会造成严重的内存碎片问题 降低应用分配内存的效率 这是不可取的 通常应提供代码缓存 固态部分 应静态此对象实例
仓储模式相对于传统的数据层(DAL/DAO)有很多优势 我举个小例子在传统的数据层中对于数据库的“变更/查询”是立即的 那么假设有三次变动
1、更新行(A)
2、删除行(A)
3、添加行(A)
在传统的数据层则会连续执行三次 但如果是仓储模式由于不是立即执行 它具备单独的“工作单元 / WorkOfUnit”与“工作仓储单元 / WorkOfUnitRepository”二者
即在工作单元“Commit / SaveChanges”前 任何对仓储中的行的改变行为只是逻辑上的表现 比如在EF中会专门标注行的状态(EntityState)
上述三个行为实际上真正被同步到数据库中 只有“更新行”但这个更新的数据则是以“添加行”覆盖的内容为主 这有什么好处?为此大费周章的去构建这个仓储?
显然从上述的举例中你明确知道仓储模式是为了尽可能的减少了对数据库操作的读写压力 数据库需要承载的读写量越来越庞大时 仓储模式是优化的一种手段
当然仓储与规约这一块的水很深 今儿怕是一下写下去停不下来 恐怕会牵扯到更多内容 比如CQRS(命令查询职责分离) 或称CQRS导论 当然既然牵扯到了这里就无法避开DDD领域仓储(领域驱动设计)
不过本文的目标是关于“规约模式与表达式树” 所以这些内容不在本文讨论范围 对于上述提到的有兴趣可参考相关的书籍 但建议开发人员的水平达到初高级(不指所谓的初、中、高级)
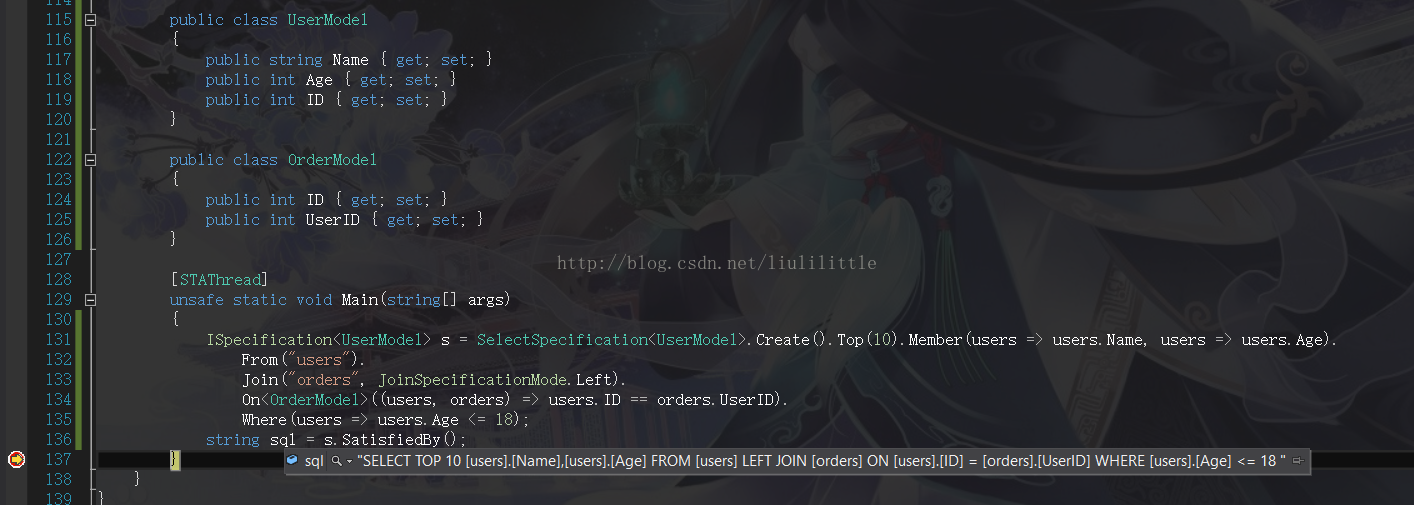
从上文中你看到了一种典型的查询规约 它在归纳的过程中把将其整合成一条有效的“SQL语句”用于查询物理数据库内的数据 但显然这部分只是对整个仓储设计的一小部分而已
一个优秀的数据仓储设计会保证对规约的内存查询与物理查询两部分相结合 最大化两者的优势当然数据整合是一个相对难处理的问题
值得一提的是规约模式是如何工作的呢?上面已经提到了是通过“栈与递归”的方式 但规约分两个部分一查询默认组成的存根函数(工厂方法) 二具体组成实现的部分
namespace STDLOGIC_SERVER.Data.Specifications
{
using System;
using System.Linq.Expressions;
public interface ISpecification<T>
{
string SatisfiedBy();
ISpecification<T> Join(string table, JoinSpecificationMode mode);
ISpecification<T> On<E>(Expression<Func<T, E, bool>> express);
ISpecification<T> OrderBy<E>(Expression<Func<E, object>> express, bool descending);
ISpecification<T> Where(Expression<Func<T, bool>> express);
ISpecification<T> Top(int? count);
ISpecification<T> From(string table);
ISpecification<T> Count<E>(Expression<Func<E, object>> express, string alias);
ISpecification<T> Member(params Expression<Func<T, object>>[] express);
}
}
namespace STDLOGIC_SERVER.Data.Specifications
{
using System;
using System.Collections;
using System.Collections.Generic;
using System.Linq.Expressions;
public abstract class Specification<T> : ISpecification<T>
{
public abstract string SatisfiedBy();
public ISpecification<T> Join(string table, JoinSpecificationMode mode)
{
return new JoinSpecification<T>(this, table, mode);
}
public ISpecification<T> OrderBy<E>(Expression<Func<E, object>> express, bool descending)
{
return new OrderBySpecification<T, E>(this, express, descending);
}
public ISpecification<T> Where(Expression<Func<T, bool>> express)
{
return new WhereSpecification<T>(this, express);
}
public ISpecification<T> Top(int? count)
{
return new TopSpecification<T>(this, count);
}
public ISpecification<T> From(string table)
{
return new FromSpecification<T>(this, table);
}
public ISpecification<T> On<E>(Expression<Func<T, E, bool>> express)
{
return new OnSpecification<T, E>(this, express);
}
public ISpecification<T> Member(params Expression<Func<T, object>>[] express)
{
return new MemberSpecification<T>(this, express);
}
public ISpecification<T> Count<E>(Expression<Func<E, object>> express, string alias)
{
return new CountSpecification<T, E>(this, express, alias);
}
}
}
namespace STDLOGIC_SERVER.Data.Specifications
{
using System;
using System.Linq.Expressions;
public sealed class MemberSpecification<T> : Specification<T>
{
private ISpecification<T> _ecx = null;
private Expression<Func<T, object>>[] _exp = null;
public MemberSpecification(ISpecification<T> left, Expression<Func<T, object>>[] express)
{
_ecx = left;
_exp = express;
}
public override string SatisfiedBy()
{
string sql = _ecx.SatisfiedBy();
if (_exp == null || _exp.Length <= 0)
{
sql += "* ";
}
else
{
int len = _exp.Length - 1;
for (int i = 0; i <= len; i++)
{
sql += ExpressionSpecification.SatisfiedBy(_exp[i]);
sql += (i < len) ? ',' : ' ';
}
}
return sql;
}
}
}在.NET/3.5时引入了一种新的机制 即表达式树 它可以动态分解Lambda表达式的代码结构 也可以动态的编译不同的代码表达式 我们称之术语“元数据表达式”
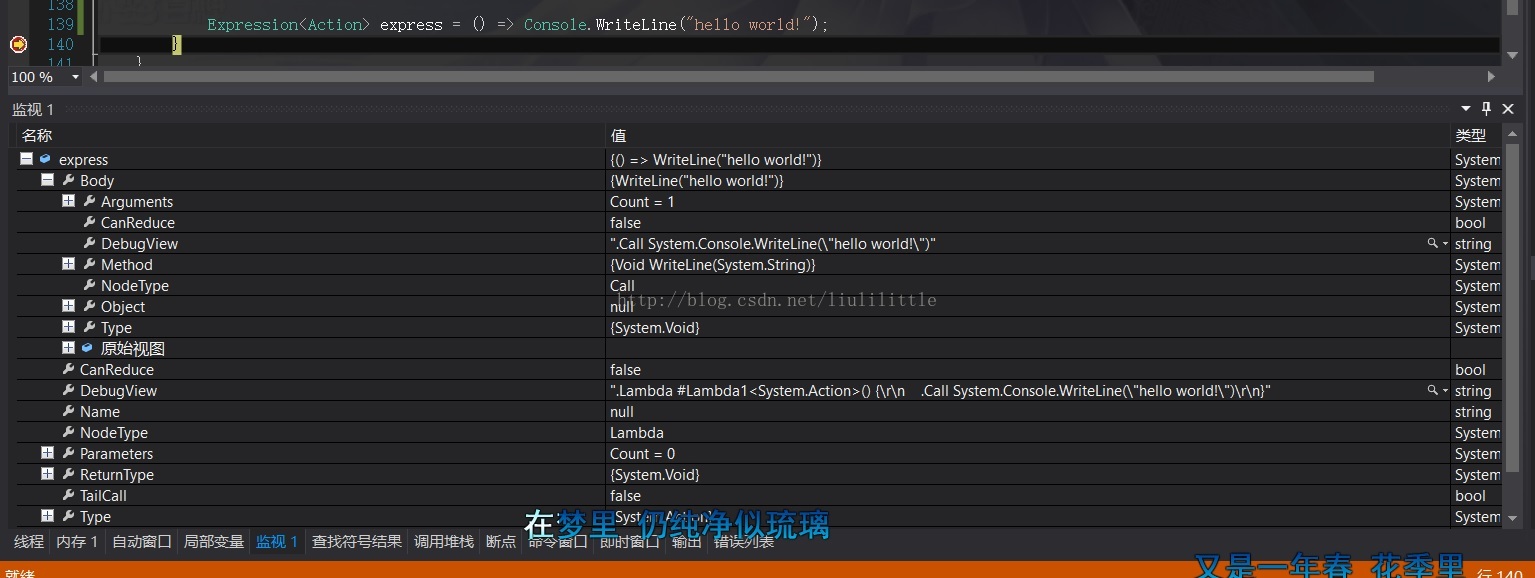
上述是一串简单的调用表达式 打出一个值(“hello world!”)看上去似乎很容易 但这里值得一提的是 编译器在遇到上述情况时会自动将其代码转换成“Expression Tree” 即编译器遇见“Expression<>”类型时
Expression<Action> express = Expression.Lambda<Action>(Expression.Call(typeof(Console).
GetMethod("WriteLine", new Type[] { typeof(string) }),
Expression.Constant("hello world!")));
express.Compile()();Expression<Action> express = () => Console.WriteLine("hello world!");.Call System.Console.WriteLine("hello world!")
}
调用控制台打出一行“hello world!”内容 从整体上看它很容易 实际上我觉得学习表达式树你应该先从“hello world!”开始 这是完全不同于一般性编程的方式 它的目的是用于高度的动态编程与执行效率 但是编译表达式树的效率并不是那么的高效 你无可避免的需要去做编译缓存
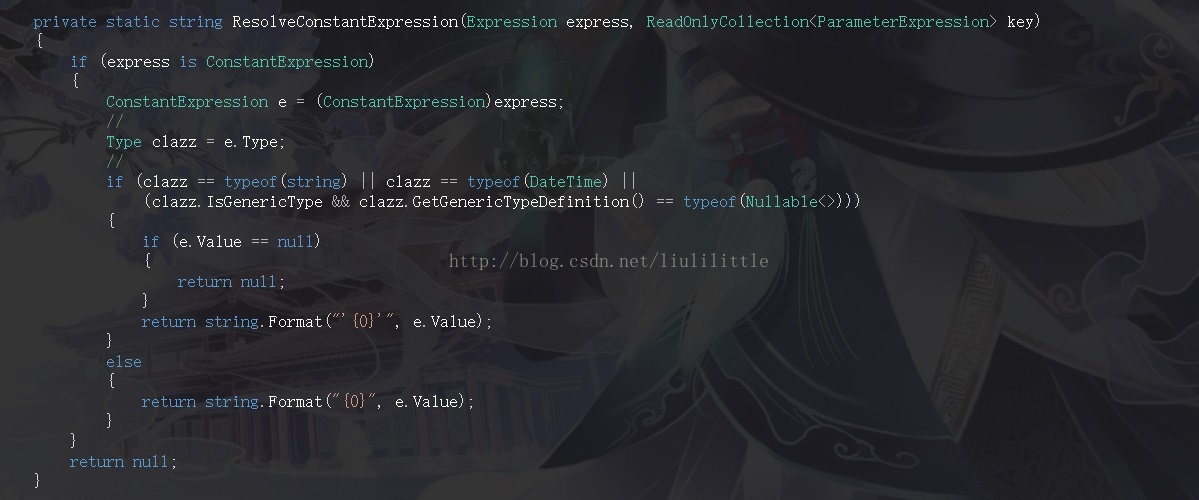
比如上图的解析常量的表达式也比较简单 但是不同的表达式之间所需要去关注的东西都有所不同 但是大体的方向并没有被改变
对于“Expression”而言“Type”属性始终表示当然表达式的类型“CanReduce”始终缺省为FALSE 即可否归纳表达式节点
如果是TRUE的方式则代表可以调用“Reduce”函数返回一个简要形式
当然还有一个所有表达式都具备的属性“Type”这个在不同类型的表达式中 所反映的情况都是不同的 我举得个例子在函数调用表达式中 它表示其返回值类型 但如果是常量、属性表达式则代表其定义类型 这有一些小小的区别
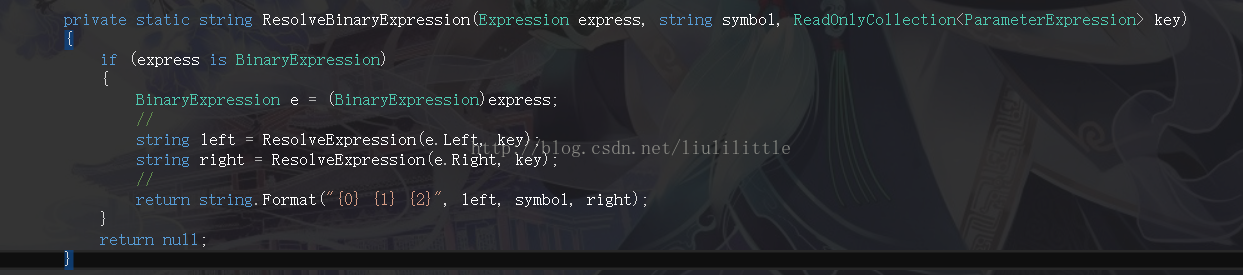
对于“=、!=、<、<=、>、>=”这类逻辑表达式而言 它们都会使用“BinaryExpression”表达式类型表示 这个表达式故名思意代表二进制操作的 对于上述表达式都是逻辑表达式 换成“0,1” 那么这里就没有什么不好理解的了 比如在C/C++中你可以使用“if(1)、while(1)”这类逻辑语句
当然刨根究底对于CLR而言逻辑值是如何工作的 我举得形象的例子咋IL中设置一个逻辑成员的值 比如设置为TRUE 在IL中它使用一个四字节的整数 1 拷贝到目标成员中
.method private hidebysig static void Main(string[] args) cil managed
{
.entrypoint
.custom instance void [mscorlib]System.STAThreadAttribute::.ctor() = ( 01 00 00 00 )
// 代码大小 4 (0x4)
.maxstack 1
.locals init ([0] bool x)
IL_0000: nop
IL_0001: ldc.i4.1
IL_0002: stloc.0
IL_0003: ret
} // end of method MainApplication::Main
你可以从这里获取本文中所示表达式树的更多内容 http://pan.baidu.com/s/1b0uv2u














 369
369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









