




 本文探讨了搜索引擎的发展历程,从分类、检索到基于用户意图的个性化搜索。搜索引擎的基本结构包括网络爬虫、索引存储、检索模型等。电商搜索与普通搜索不同在于数据来源的清洁度和对用户分析的重视。文章还介绍了Elasticsearch(ES)的分布式原理,以及搜索模块如网络爬虫、索引构建和查询处理的工作细节。同时,强调了搜索引擎的存储系统、意图识别和反作弊分析的重要性。
本文探讨了搜索引擎的发展历程,从分类、检索到基于用户意图的个性化搜索。搜索引擎的基本结构包括网络爬虫、索引存储、检索模型等。电商搜索与普通搜索不同在于数据来源的清洁度和对用户分析的重视。文章还介绍了Elasticsearch(ES)的分布式原理,以及搜索模块如网络爬虫、索引构建和查询处理的工作细节。同时,强调了搜索引擎的存储系统、意图识别和反作弊分析的重要性。
init
background
搜索与推荐是我现在主要的工作内容, 随着时间的推移, 自己慢慢对搜索有了一个大概的理解, 但是这个理解并不深刻, 还需要持续的加强。
Content
什么是搜索引擎? 搜索引擎怎么发展的?
搜索是互联网的入口,是为数不多的以技术为驱动的技术产品。想要快速找到自己想要的东西,必须得经过搜索引擎。从最开始的分类开始,虽然保证了质量但是搜索出来的内容只限于自己收录的,而互联网每天产生那么多内容,这样根本不行。之后出来了检索一派的,大致就是根据自己的内容去匹配相关内容,但是质量难以保证。之后基于pagerank算法,对引用较多的网站提升排名,从而实现了质量的提升,但是不少人通过这种方式进行作弊,所以质量还是有待提升。而目前也就是第三代搜索引擎通过分析用户过去的信息,形成千人千面的搜索引擎。
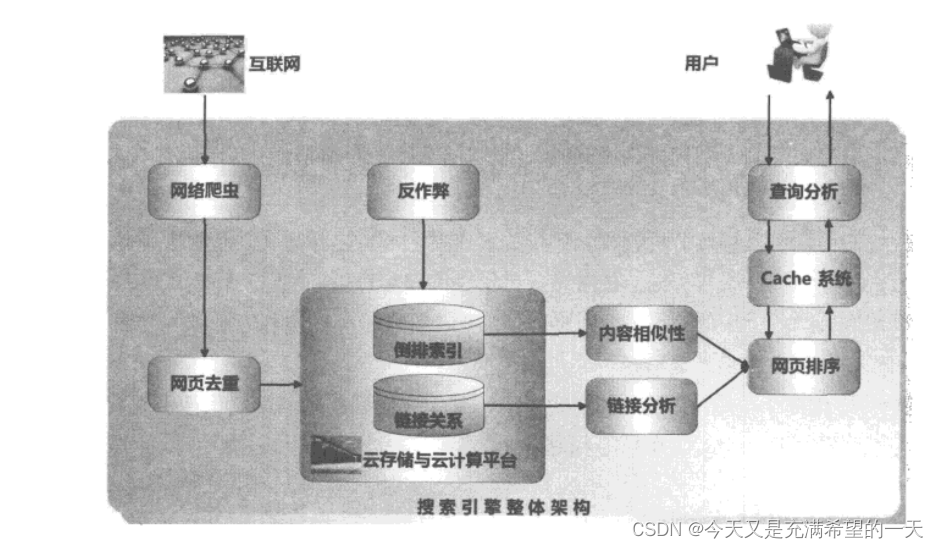
搜索引擎的基本结构是什么样的?
- 一般就是网络爬虫从网络中将数据爬到,解析相关的数据进行去重后存储,将数据内容按照倒排索引存储好,还有网络的相关性也要存储,
而这些都是存储到hadoop等存储引擎上的。当用户发送请求过来,需要对查询词查询其真正的意图,然后根据用户的意图命中缓存,如果命中不了就要从排序模块中获得最相关的内容,再去存储引擎中的详情接口中去取数据。
电商搜索和普通搜索的区别?都有哪些搜索引擎?各个应用的地方?
-
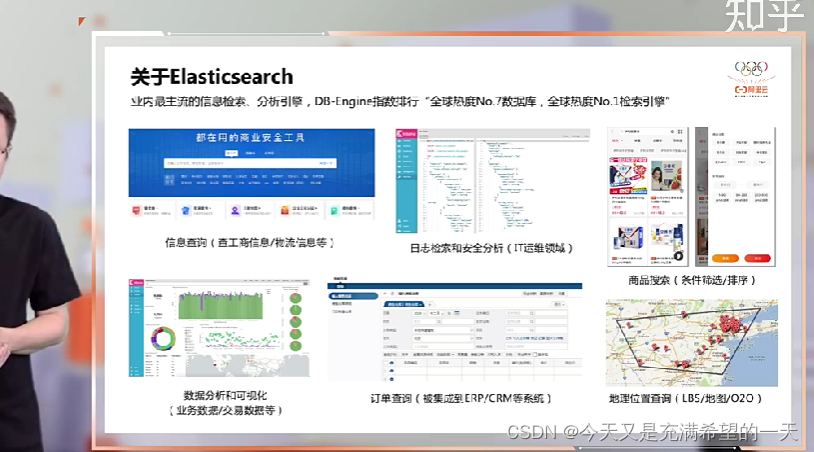
电商的搜索和普通的搜索引擎有一些很大的区别就是数据来源, 电商的数据来源是非常干净的, 不需要太多清洗的。 因此没有爬虫等模块。 但是电商在对用户进行分析和召回上会做大量的工作。 首先我们要知道所有的搜索引擎其实都是基于luence那一套, 而es是将luence给分布式化了, 这种任务单一的模块, 是太容易被开源社区给推成一个中间件。 但是es只是对于中大型公司的, 社区并没有那么多财力和精力去把这个东西给做成超大型。 因此很多搜索团队会使用C++自己做一套搜索, 数据接入自己的数据生成索引, 然后基于luence那一套再添加一些算法生成倒排索引召回, 以及各种模块, 再结合分布式搞成一套分布式搜索系统, 达到非常快的一个速度。
-
应用点
-
es 一般用于查日志和订单和中小企业搜索需求。
-
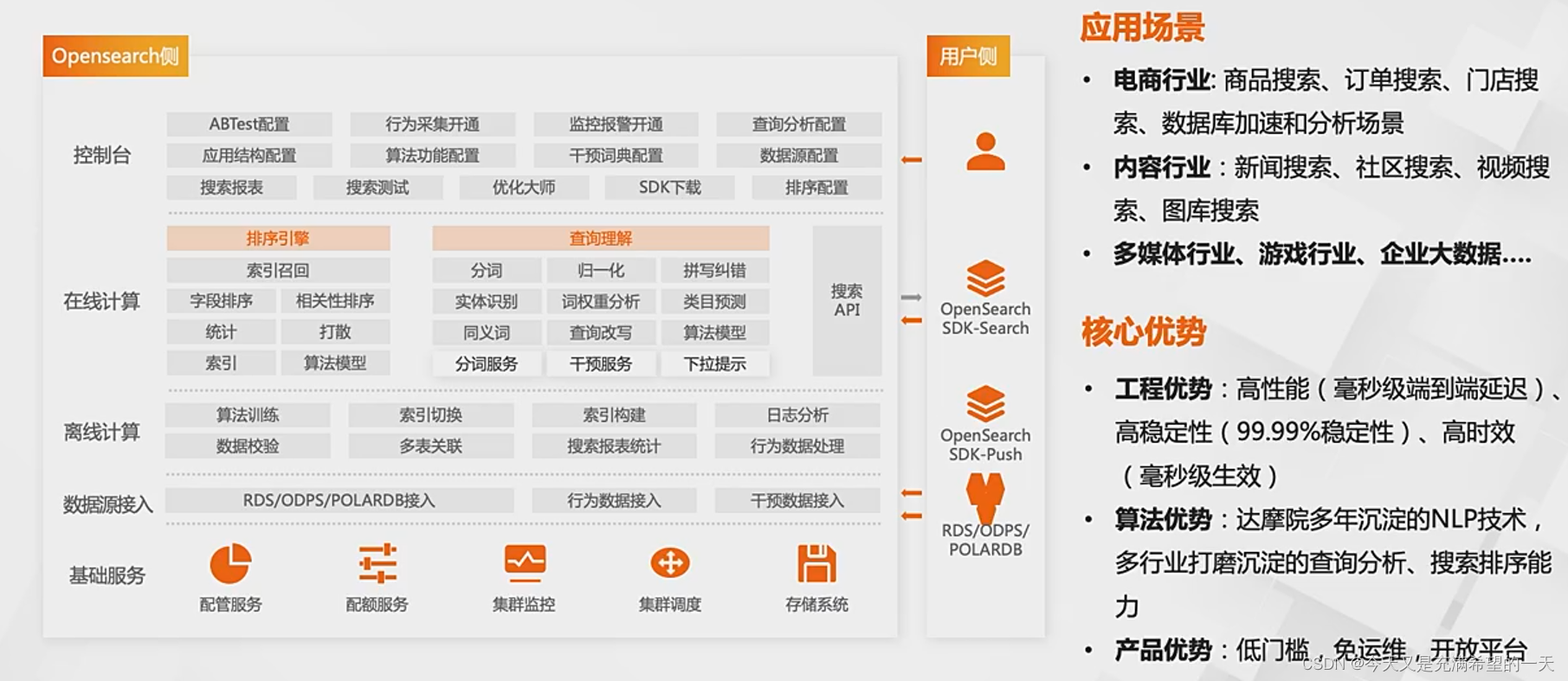
阿里等内部使用的C++搜索在稳定性和实效性上高,而且有很多已经在商品等领域弄好的模型和排序, 并且配套了各种干预和意图识别功能, 一般的中小公司完全可以用它, 如果自己没有资金自研的话。
搜索各个模块的主要工作
1. 网络爬虫
主要有深度优先追历等方式,定点定时爬取固定的内容,但是目前由于很多网站是不想让爬取的,做了反爬机制,这部分需要注意,垂直领域数据是根据用户的设置的。不是通过爬虫搞的。
2. 索引基础
-
索引就是提供快速搜索内容的关键字。正排索引是类似b+树,根据内容快速的检索到内容。而对于文档这种用户根据关键字进行搜索,匹配文档的需求,需要进行倒排索引也就是以关键字为核心去表示文档。例如我们几句话,用单词作为倒排索引的话:文档id、单词出现次数、和位置共同组合倒排索引而这个倒排索引所采用的具体存储结构有很多。
-
单词词典就是所有文档出现的单词统计,一般词典要非常的全。一般词典存储的结构就是哈希冲突链表、b+树,
倒排列表就是一个单词,后面存储单词对应文档的索引项,非常多,一般采用差值排列,可以更好的对数据进行压缩。 -
建立索引是通过好几种方式,一种是两遍文档迪历方法、第一一遍统计一个单词出现的文档数量,从而获取最终约内存大小),、第二遍统计每个文档中出现的次数,“这样最终落地到磁盘当中就是建立索引的过程,此外这样
做的内存占用比较大,一股还有归并的方式,
此外还有一个问题就是如何建立动态索引,前面我们建立的都是静态的存储在顶盘,我们需要额外创建一个实时索引存储在内存,还有一个删除表的文档表、这样一次用户的查询过来、我们先去的索引和临时索引中合并,结果
然后去删除表中过滤, 就可以做到实时的检索。 -
索引更新策略: 对于实时的临时索引,怎么更新是一个问题,如果内存满了怎么办?有好多种,
最简单的就是新文档达到一定的数量之后和老文档进行合并,统一后再查。复杂的先跳过。 -
查询处理:具体用户一个查询过来,一般就是将用户的查询词对应的倒排列表加载到内存中,然后通过词频率等参数计算这个文档的得分,输入到一个k纬度的优先队列进行维护只保存前k个文档。 而很多时候对于用户的多个词、需要命中多个词纳交集,在子算的过程中可以进行加速,例如将之前的数据进行切。切割多个块进行加速,每次只需要解压一个索引差值表、读取里面的文档id进行求交集.
-
多字段索引:文档中标题和正文的关键读不一样, 可以分开建立索引, 给出不用的权重。
-
短语查询:对于你懂得和懂你的这种词检索, 需要在索引表中的位置信息, 不然很难通过单词来检索出具体的内容。
-
分布式部署:一般都是按照文档分布式部署, 便于扩展, 很少按照词典, 那样风险比较高, 服务崩溃那一个单词就查不到了。
检索压缩
-
对于词典数据和索引列表一般都是会进行压缩的。对于词典数据我们可以存储地址而不是具体内容,因为很多单
词的大小不一致,我们只存地址,额外用一个地方单独存储数据。对于索引列表中的数据,我们可以使用一元编码加二元编码组合的方式对词频率进行压缩,因为词频率差距非常大。 -
文档聚类
文档聚类大致就是通过将相似的文档尽量docid弄到一起,提高压缩率。 -
静态索引裁剪
静态索引栽剪就是对索引进行裁剪,在实际算排序分数时候会用到。让一些对排序不重要的索引下掉。
检索模型
这个是搜索的核心,其目的主要对用户媸索的内容匹配出最需要的内容,但是最需要的内容已经通过意图识别找到了,因此不再德里的讨论范围内我们默认在这个模块我们已经知道了用户的真正甥索词,要知道具体的内容了。这时候需要用几种算法来计算这也是搜索的核心,
检索模型
- 布尔检索 : 需要用户提供与或非的数值,直接对文档进行匹配,但是这种只要找到内容或者找不到内容,不能得到一些分数排序,只能命中或者不命中,
- 向量空间 : 主要就是将单词和文档弄成向量矩阵,然后将自己的搜索词也弄成单饲纬度的矩阵,取点积最大的。至于向量矩阵中具体特征值的权重特征值取多少有很多算法,最简单的就是词频单词在所有文档区分程度
得到就是权重。 - 概率模型:通过贝叶斯公式, BM2.5 做。
- 语言模型:HMM等这些基础的语言检索模型。
- 机器学习模型 : 像之前的概率模型和语言模型都是算法工程师精心调整的, 参数比较少, 可解释性强。 但是机器学习算法是让算法填充数据, 模型来进行学习的。 一般就是给文档设置特征和结果, 让算法进行训练。 但是这种不可控性还是有点的。
- 评价指标 : 精确度就是相关的文档占你搜出来内容的多少, 召回率是相关文档占所有存储相关文档的多少。 一般关注精确率, 召回率不好计算。 具体评估的时候有p@10 和map这几个指标。 map就是看自己的多次搜索出来内容位置和理想的位置差距。
存储系统
- 作者介绍了搜索需要存储很多非结构化的数据, 而且必须分布式的, 因此介绍了搜索的数据存储部分结构。
- 云存储的需求
弱一致性, 故障无影响, 可扩充, 读多写少。 - 数据的模型和理论基础
一般就是要让数据库满足cap 和acid, 然后还要数据模型可以key_value 存储底层原理更方便。 - 常见的解决方案
google提出了一套解决方案, gsf等搭建的。 而雅虎资助开源社区也搞了一套hadoop, 其中hdfs做存储,hbase作为数据操作, zookeeper作为服务管理等。
这里内容也比较复杂, 有很多, 我们就重点看hadoop就行, 了解其怎么管理处理用户的上游表的。
意图识别
- 就是在这里通过纠错, 用模型查询用户的真正意图, 往往还会结合用户的过去信息等, 还有复杂的模型。
反作弊分析和网页去重和链接分析
这是网站搜索的重点考虑隐私, 但是和垂直搜索没有关系, 所以先略过。
理解es底层原理
感悟
感觉搜索真的是经久不衰的行业, 是可以越老越吃香的, 其背后的那一套内容非常固定, 而且非常以技术为核心。 首先其搜索模型和意图识别中会有很多搜索相关的数学和机器学习内容, 存储部分还有很多高并发相关的内容, 数据相关又有很多工作, 因此真的是非常难搞懂的一个模块, 不过这东西有好有坏, 坏处就是太杂了, 难以聚焦到一个点。
workflow
ConfigureEnvironmentForES()
get ssh;
> ssh-keygen
> cat /root/.ssh/id_rsa.pub
setting ssh into your GitHub;
ConfigureDemoForES()
Reference()
- java搭建电商搜索https://blog.csdn.net/liupeng19970119/article/details/125404967?spm=1001.2014.3001.5501
- 这就是搜索引擎
- 电商搜索全链路(一):Overview - kaiyuan的文章 - 知乎
https://zhuanlan.zhihu.com/p/511231953 - 阿里巴巴复杂搜索系统的可靠性优化之路 - 阿里云云栖号的文章 - 知乎
https://zhuanlan.zhihu.com/p/59588995 - 10年+,阿里沉淀出怎样的搜索引擎? - 阿里云云栖号的文章 - 知乎
https://zhuanlan.zhihu.com/p/83869214 - 开放搜索重磅发布开源兼容版 - 智能开放搜索的视频 - 知乎
https://www.zhihu.com/zvideo/1425839683897630720
version log()
- 整合之前的内容全部组装到一起,现在感觉能用了。2022年11月12日18:51:45

















 1384
1384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









