







转载自:https://blog.csdn.net/weixin_26945061/article/details/113451692
故障描述
1.1发生背景
很久很久以前,有一天,我在HBase中新建了一张表 “XXX: XXX _EXCEPTION_LIST_INFO”,同时HBase在处理大量更新操作。然后在DROP掉表XXX: XXX_EXCEPTION_LIST_INFO时,HBase Master就宕机。
之后通过CM重新启动后HBase服务,服务重启后发生如下两个错误,导致HBase集群无法正常恢复:(1)HMaster节点自动Active失败;(2)大量Region出现offline和RIT。
1.2现象描述
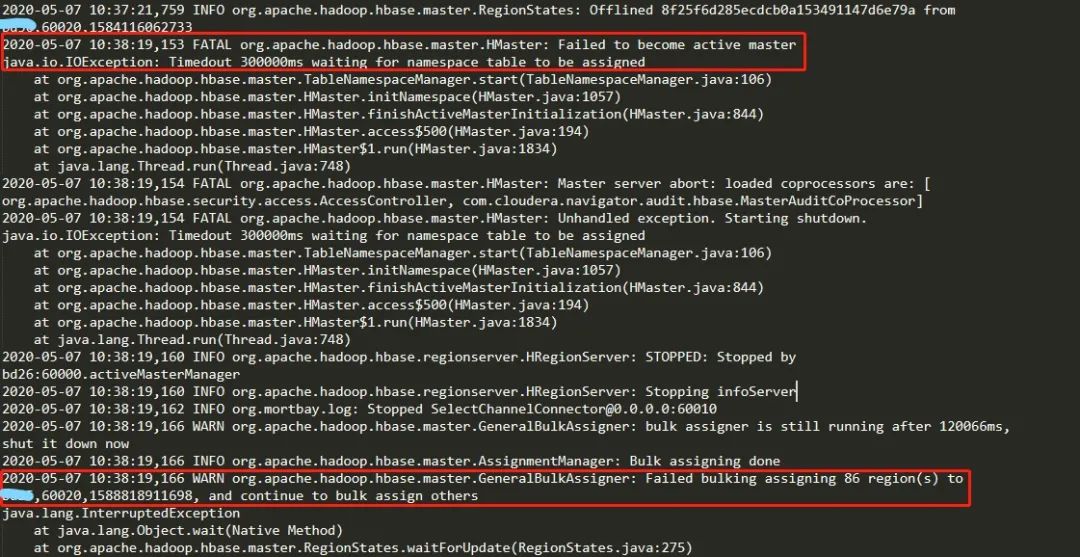
HA HMaster节点启动了,过一段时间Active HBase Master节点自动失败(大概3~5分钟)。因为集群采用了HA高可用,因此Standby HBase Master节点自动切换为Active。再过差不多相同时间,该节点也自动失败。
查看Master节点的日志报错如下
Failed to become active master java.io.IOException: Timedout 300000ms waiting for namespace table to be assigned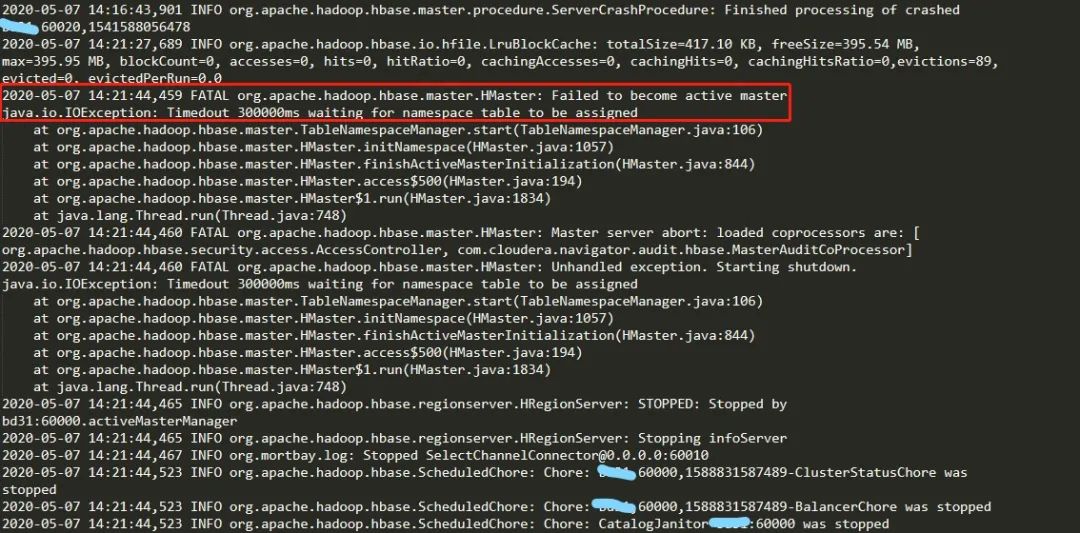
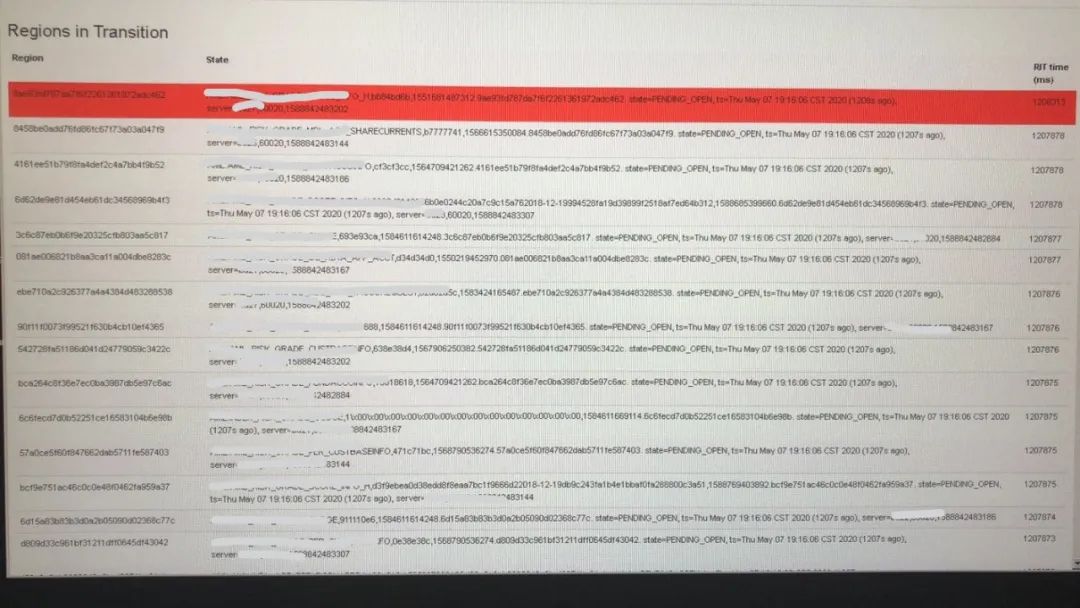
Master Web UI上显示处于RIT的Region
Master状态页告警信息:
Found regions staying in transition state for a duration longer than the configured threshold in HBase.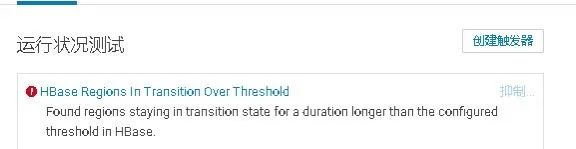
故障分析处理
1.Master的日志报错:Timeout 300000ms waiting for namespace table to be assigned.表示namespace表未分配,并且超过设置的时间阈值。在HBase的设计中,Master启动时首先分配meta表,然后再分配其它表。系统表hbase:namespace和其它用户表分配时同等对待,并没有先分配系统表再分配用户表,如果一个集群region非常多,默认300000ms(5分钟)还分配不到namespace表,此时需要修改hbase.master.namespace.init.timeout超时时间。
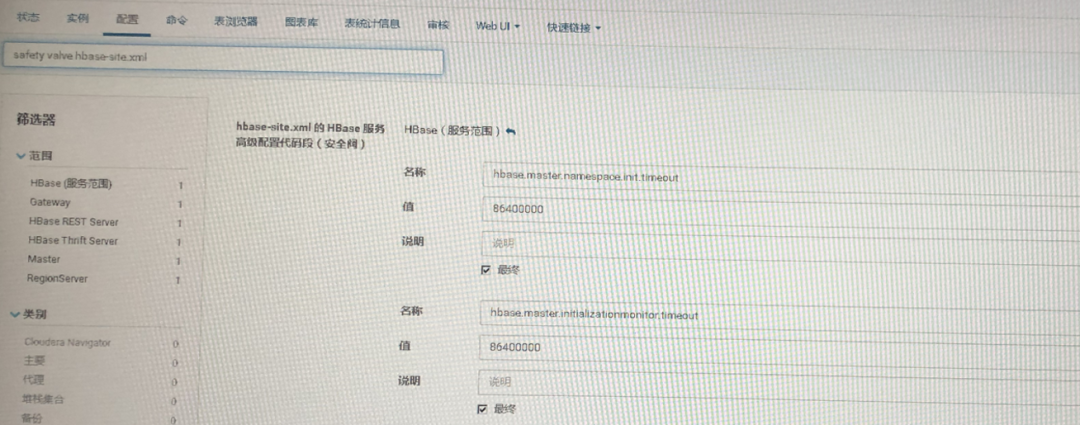
2.根据此时情况,通过CM在“hbase-site.xml的HBase服务高级配置代码段(安全阀)”中增加以下配置:
<property>
<name>hbase.master.namespace.init.timeoutname>
<value>86400000</value>
</property>
<property>
<name>hbase.master.initializationmonitor.timeout</name>
<value>86400000</value>
</property>
即增加namespace表分配超时时间为1天。
修改完成之后重启HBase服务,这里选择滚动重启HBase时RegionServer无法重启,所以选择完成重启HBase服务。
3.重启完成后,Master依然告警:Found regions staying in transition state for a duration longer than the configured threshold in HBase.,但服务并未宕掉,Master告警提示的原因是在HBase Master启动时,检测到有Region长时间处于RIT状态(超过阈值)。
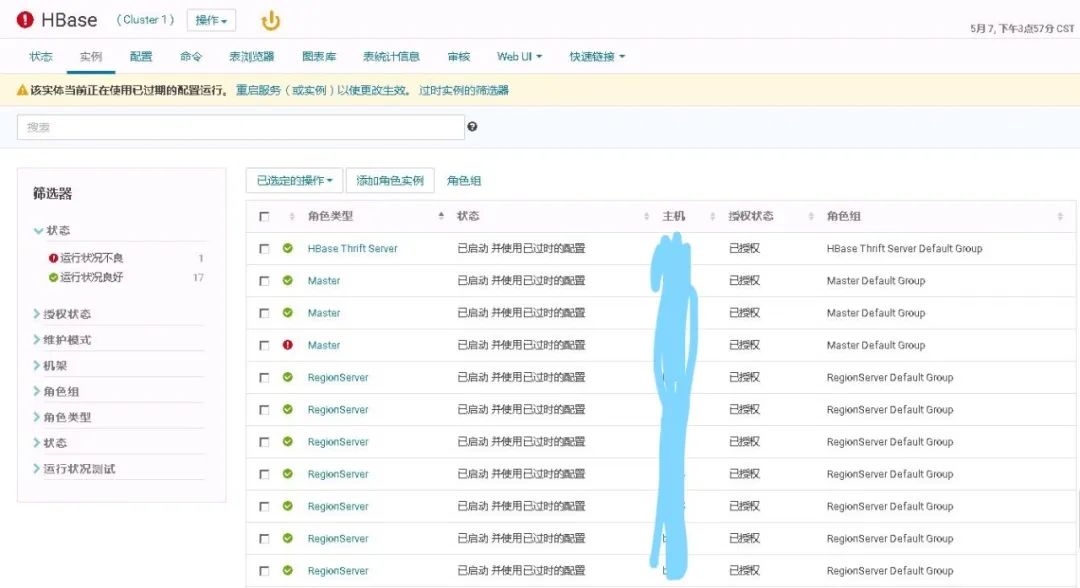
查看Master日志如下:
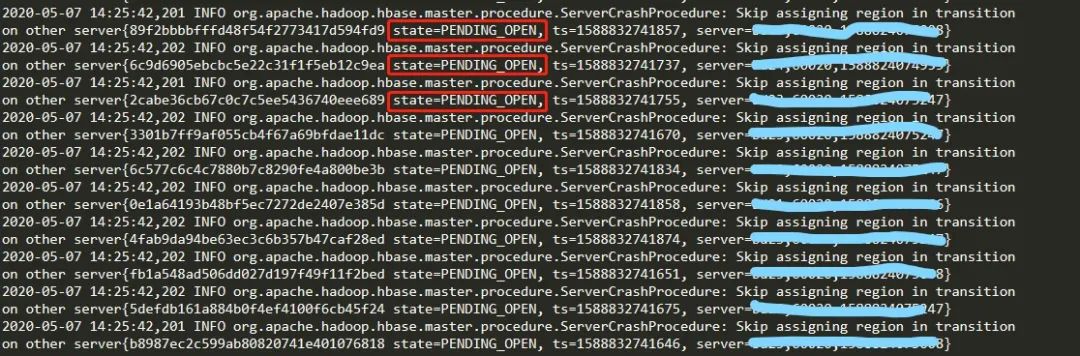
大量Region处于PENDING_OPEN状态,Master检测到RIT,
查看Zookeeper中的/hbase/region-in-transition,也可以看到大量的Region。

说明:每次HBase Master对Region的一个OPEN或一个CLOSE操作都会向Master 的RIT列表中插入一条记录,因为Master对Region的操作要保持原子性。Region的 OPEN和 CLOSE是通过HBase Master和 RegionServer 协助来完成的。为了满足这些操作的协调、回滚、一致性,HBase Master采用了 RIT 机制并结合Zookeeper 中znode状态来保证操作的安全和一致性。
Region有以下几种状态:
- OFFLINE:region is in an offline state
- PENDING_OPEN:sent rpc to server to open but has not begun
- OPENING:server has begun to open but not yet done
- OPEN:server opened region and updated meta
- PENDING_CLOSE:sent rpc to server to close but has not begun
- CLOSING:server has begun to close but not yet done
- CLOSED:server closed region and updated meta
- SPLITTING:server started split of a region
- SPLIT:server completed split of a region
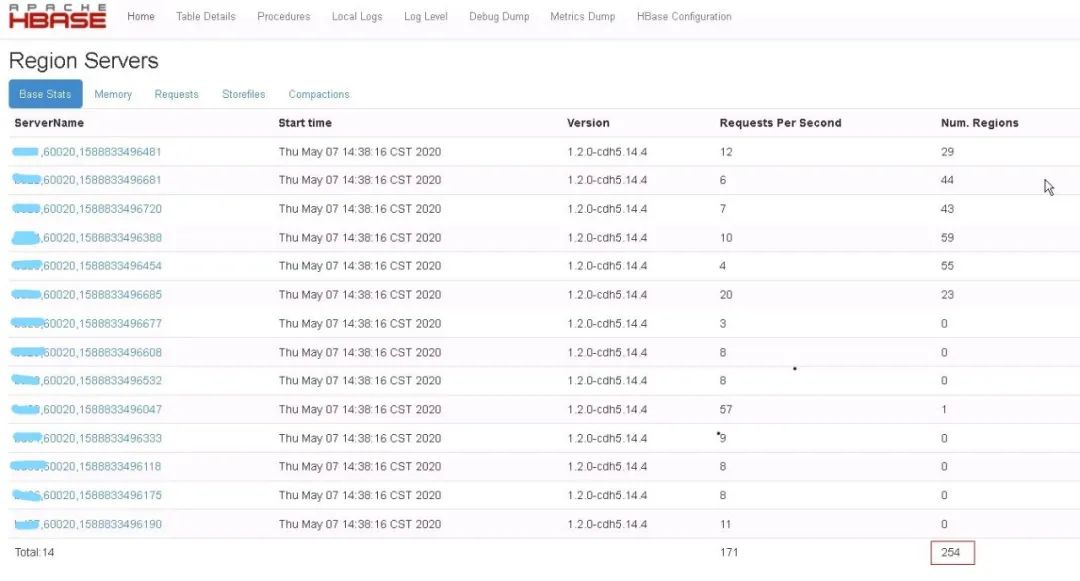
在注册为active的Master Web UI上查看已上线的Region数如下:
4.经确认HBase未使用replication后,选择重建Znode的方式进行测试:
a.停止HBase服务
b.使用hbase zkcli命令进入ZK客户端
c.执行rmr /hbase清除/hbase
d.重启HBase服务,此时/hbase会重新生成
5.但是重启完之后问题依然存在,再次查看Master日志发现如下信息:
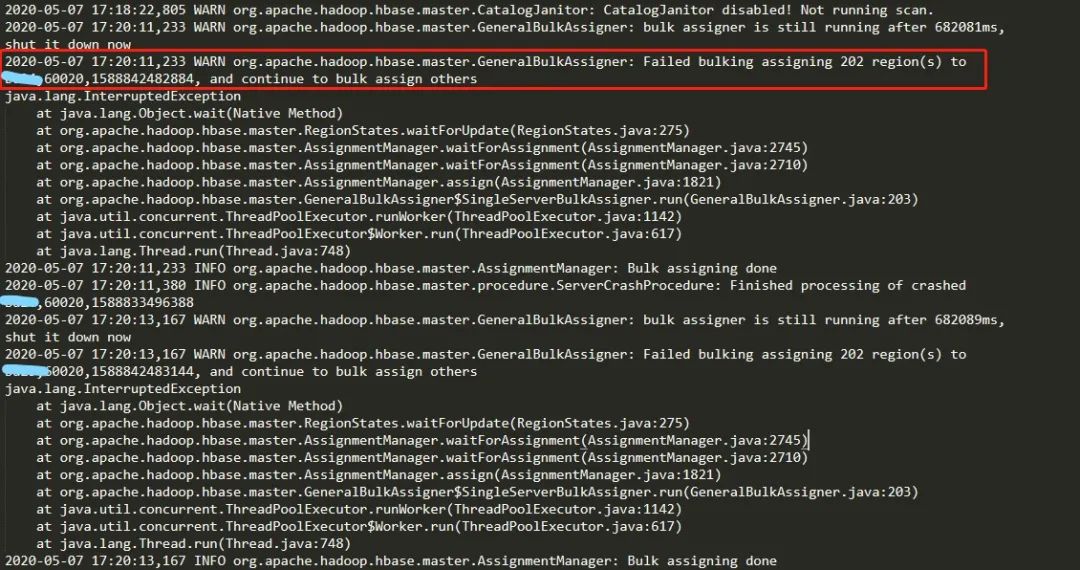
6.查看RegionServer的日志,可以看到频繁出现以下错误:
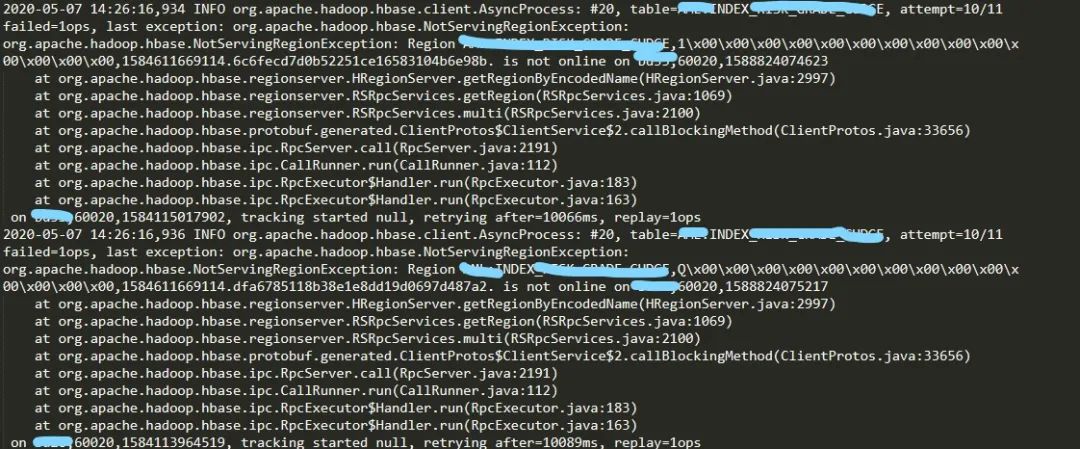
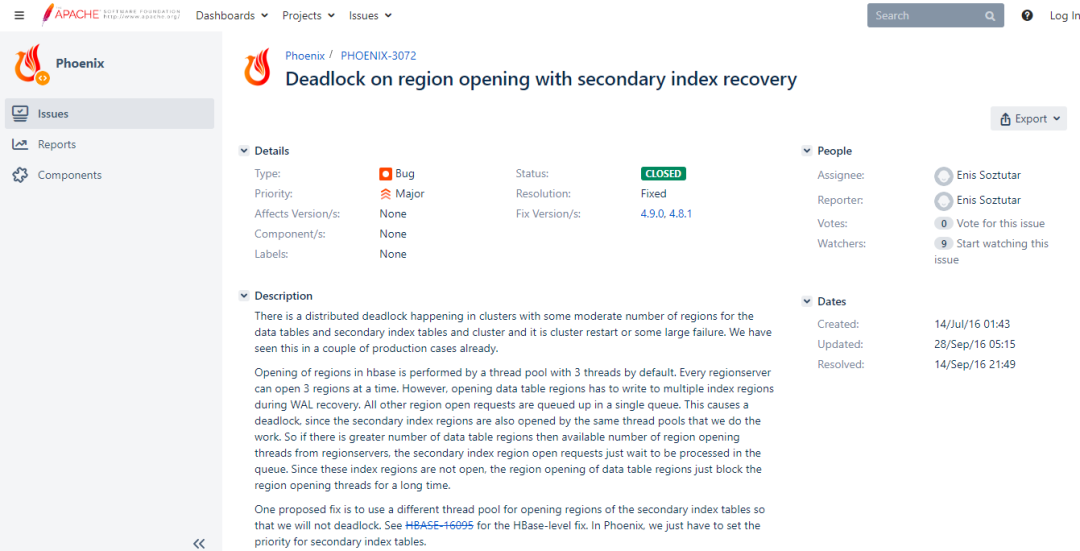
由上可以看出索引表的Region is not online,查看RegionServer Web UI发现RPC线程一直处于Initializing Region的Replaying edits阶段,并且在等待一个小时时间后依然未完成。因此分析原因为Phoenix索引表的Region不能online,导致数据表的Region构建进程卡住,但是这些构建进程占用了openregion线程(默认3个),导致索引表不能正常openregion,产生死锁。
因此需要调整hbase.regionserver.executor.openregion.threads参数以增加openregion线程数。
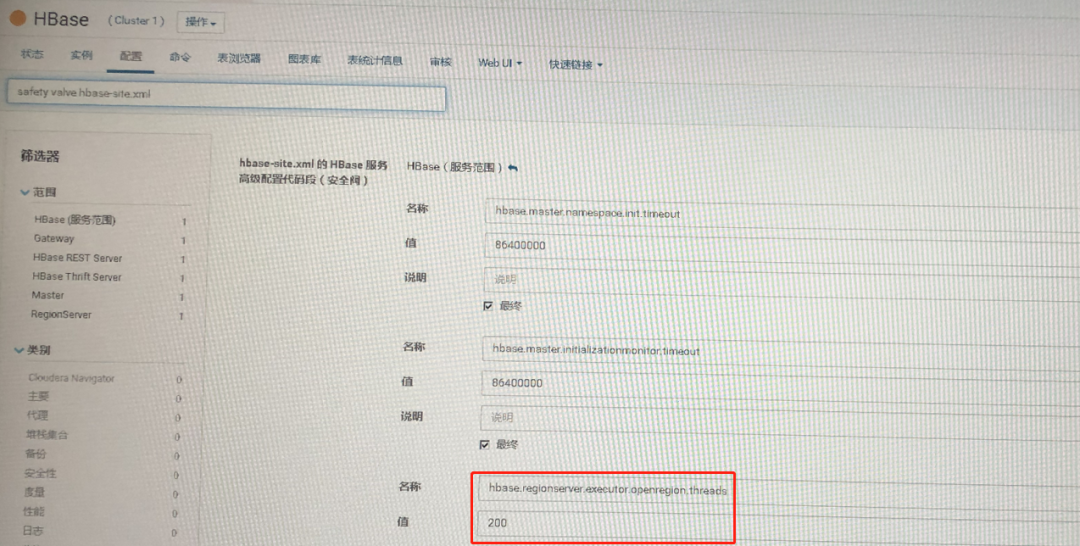
7.通过CM在“hbase-site.xml的HBase服务高级配置代码段(安全阀)”中增加以下配置:
<property>
<name>hbase.regionserver.executor.openregion.threads</name>
<value>200</value>
</property>
即增加Region分配线程数至200个,然后再次重启HBase服务
重启HBase服务, HBase Master仍有告警信息,但在Active Master Web UI上可以看到上线的Region数量在增加,同时RIT中的Region数量在减少。稍等片刻后HBase服务恢复正常。
经测试HBase可以正常提供服务,数据无丢失。
处理结论
1.HBase Master在启动时会首先分配meta表的Region,然后再分配其它表。namespace表和user表分配时同等对待,并没有先分配系统表再分配用户表,如果一个集群Region非常多,默认300000ms(5分钟)有可能还分配不到namespace表,此时抛出异常:Failed to become active master java.io.IOException: Timedout 300000ms waiting for namespace table to be assigned。此时需要调整参数hbase.master.namespace.init.timeout增加超时时间。2.分布式死锁发生在使用Phoenix(4.14.1)构建二级索引,并且数据表、二级索引表的Region数量适中的集群中。当RegionServer打开Phoenix数据表的一个Region时,它将为该Region执行WAL重播,并重新构建二级索引表,而数据表的Region分配依赖于二级索引表。默认情况下每个RS上只有一个线程池,包含三个openregion线程。而二级索引表和数据表共用同一个线程池。因此,当Phoenix数据表的Region的这些重建进程占用了openregion线程时,二级索引表就只能进入队列等候,其Region就不能online。这就是死锁发生的原因。
解决方式可以在hbase-site.xml中修改以下参数:
1)设置hbase.master.startup.retainassign为false(默认为true)
2)增加hbase.regionserver.executor.openregion.threads 的值(默认为3),然后重启集群解决。
如果还是出现同样问题,可以调优以下分配管理器参数,以匹配Region的数量,从而加快分配速度:
hbase.assignment.threads.max:线程池大小,默认值30
hbase.master.namespace.init.timeout:默认值300000ms
hbase.master.wait.on.regionservers.mintostart:向HMaster汇报的RegionServer的数量最小启动值,默认值1
hbase.bulk.assignment.threshold.regions:Region数量超过阈值(默认值7),使用bulk assign
hbase.bulk.assignment.threshold.servers :Server数量超过阈值(默认值3),使用bulk assign
参考链接:
https://issues.apache.org/jira/browse/PHOENIX-3072
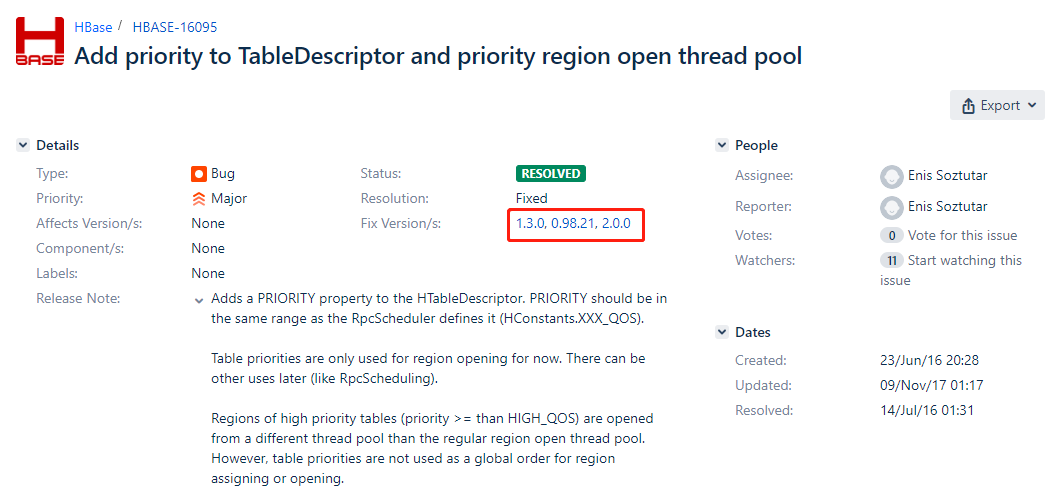
https://issues.apache.org/jira/browse/HBASE-16095

https://docs.cloudera.com/documentation/enterprise/release-notes/topics/cdh_rn_phoenix_ki.html#concept_xdx_1wq_dq















 861
861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









