









该论文提出了基于最大互信息(Maximum Mutual Information—MMI)的期望计算思想。
传统的生成模型计算方式是:target = argmax(logP(T|S)),即在source给定的条件下,寻找出最大概率的target。
这样的计算方式所带来的问题是会生成一般性的,具有大概率事件的target,失去了target的多样性。
由互信息公式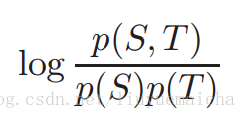
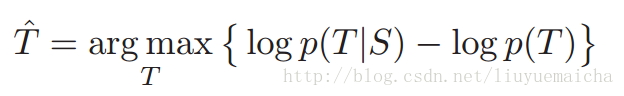
该论文基于MMI思想,提出了新的target计算方式,即:
target = argmax{logP(T|S) - logP(T))} ===加入权重系数===》:
(公式1)target = argmax{logP(T|S) - r*logP(T)} (r为超参数,可理解r*logP(T)为对target生成概率的惩罚值)
公式(1)经过Bayes公式的变形可转化为:
(公式2)target = argmax{(1-r)*logP(T|S) + r*logP(S|T))}
(推导:)

MMI训练中的问题,将MMI运用到Seq2Seq模型中想法很好,但需要得到超参数r,我们不可能通过不断地尝试,每次都重新训练一个模型,那样太耗时了。所以建议只是在Decode时使用MMI。
公式(1)中,在MMI的运用实践中,加入惩罚因素r*logP(T)确实可以使回复变得多样性,但也趋向于生成不符合语法的句子(该问题使用MMI-anti表示)。实验中可以发现,第一个token的生成相比后面token的生成更依赖前一序列,在第一个token生成中加入惩罚值,可以提高生成的多样性,而如果在后续token中加入惩罚因素,生成的序列越长,就越容易导致生成sequence语法的不通畅。所以将之前固定的惩罚因子替换为随着序列生成递减的因子g(k)。
如果使用公式(2),在logP(S|T)部分中,需要在Target序列生成前计算P(S|T),而T的空间范围非常大(即需要找出生成T的所有可能),所以计算起来异常复杂耗时。这样的话,可以使用一般的Seq2Seq模型预先生成前N-best的序列集,作为T的选择空间。














 2122
2122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









