






文章目录
上一篇我们学习了线性回归
机器学习从零开始系列连载(一)——纯Python手写线性回归模型
本文开始介绍逻辑回归

逻辑回归假设样本服从伯努利分布,利用极大似然估计,运用梯度下降法进行求解,从而达到将样本二分类的目的。
逻辑回归
监督学习,解决二分类问题。
分类的本质:在空间中找到一个决策边界来完成分类的决策
逻辑回归:线性回归可以预测连续值,但是不能解决分类问题,我们需要根据预测的结果判定其属于正类还是负类。所以逻辑回归就是将线性回归的(−∞,+∞)
(−∞,+∞)结果,通过sigmoid函数映射到(0,1)之间

优缺点
优点:实现简单,易于理解,计算代价不高,速度快,存储资源低
缺点:容易欠拟合,分类精度不高,一般只能处理两分类问题,必须借助softmax才能实现多分类问题,且前提是必须线性可分。
虽然逻辑回归能够用于分类,不过其本质还是线性回归。它仅在线性回归的基础上,在特征到结果的映射中加入了一层sigmoid函数(非线性)映射,即先把特征线性求和,然后使用sigmoid函数来预测。
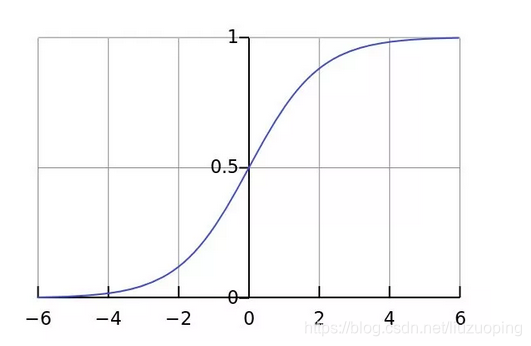
这主要是由于线性回归在整个实数域内敏感度一致,而分类范围,需要在[0,1]之内。而逻辑回归就是一种减小预测范围,将预测值限定为[0,1]间的一种回归模型,其回归方程与回归曲线如下图所示。逻辑曲线在z=0时,十分敏感,在z>>0或z<<0处,都不敏感,将预测值限定为(0,1)。
LR在线性回归的实数范围输出值上施加sigmoid函数将值收敛到0~1范围, 其目标函数也因此从差平方和函数变为对数损失函数, 以提供最优化所需导数(sigmoid函数是softmax函数的二元特例, 其导数均为函数值的f*(1-f)形式)。请注意, LR往往是解决二元0/1分类问题的, 只是它和线性回归耦合太紧, 不自觉也冠了个回归的名字(马甲无处不在). 若要求多元分类,就要把sigmoid换成大名鼎鼎的softmax了。
首先逻辑回归和线性回归首先都是广义的线性回归,其次经典线性模型的优化目标函数是最小二乘,而逻辑回归则是似然函数,另外线性回归在整个实数域范围内进行预测,敏感度一致,而分类范围,需要在[0,1]。逻辑回归就是一种减小预测范围,将预测值限定为[0,1]间的一种回归模型,因而对于这类问题来说,逻辑回归的鲁棒性比线性回归的要好。
逻辑回归的模型本质上是一个线性回归模型,逻辑回归都是以线性回归为理论支持的。但线性回归模型无法做到sigmoid的非线性形式,sigmoid可以轻松处理0/1分类问题。
sigmoid 函数
相较于线性回归的因变量 y 为连续值,逻辑回归的因变量则是一个 0/1 的二分类值,这就需要我们建立一种映射将原先的实值转化为 0/1 值。这时候就要请出我们熟悉的 sigmoid 函数了:
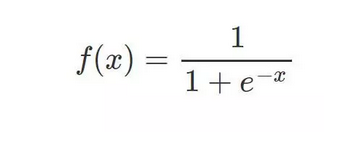
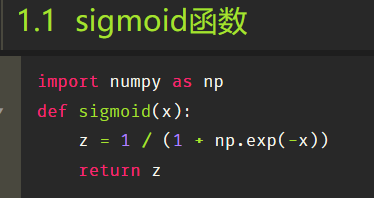
Python定义一个 sigmoid 函数:
其函数图形如下:
 sigmoid 函数还有一个很好的特性就是其求导计算等于下式
sigmoid 函数还有一个很好的特性就是其求导计算等于下式
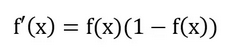
这给我们后续求交叉熵损失的梯度时提供了很大便利。
逻辑回归模型的数学推导
由 sigmoid 函数可知逻辑回归模型的基本形式为:
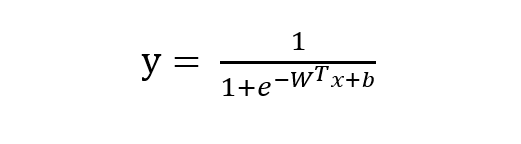
稍微对上式做一下转换:
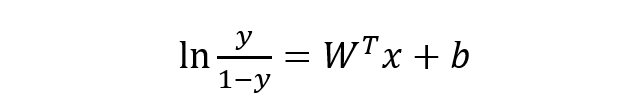
下面将 y 视为类后验概率 p(y = 1 | x),则上式可以写为:
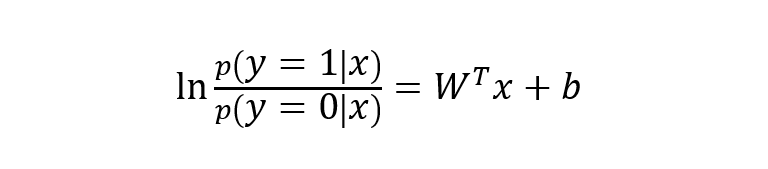
将上式进行简单综合,可写成如下形式:
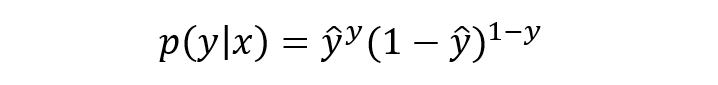
写成对数形式就是我们熟知的交叉熵损失函数了,这也是交叉熵损失的推导由来:
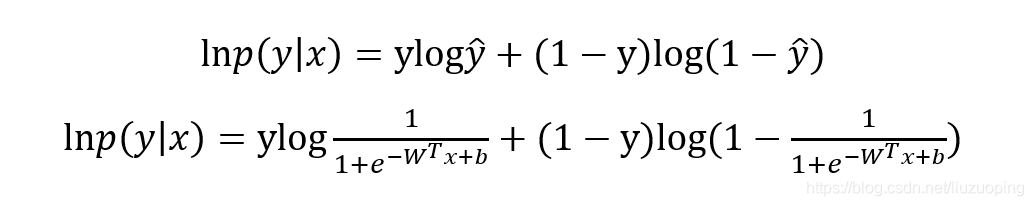 最优化上式子本质上就是我们统计上所说的求其极大似然估计,可基于上式分别关于 W 和b 求其偏导可得:
最优化上式子本质上就是我们统计上所说的求其极大似然估计,可基于上式分别关于 W 和b 求其偏导可得:
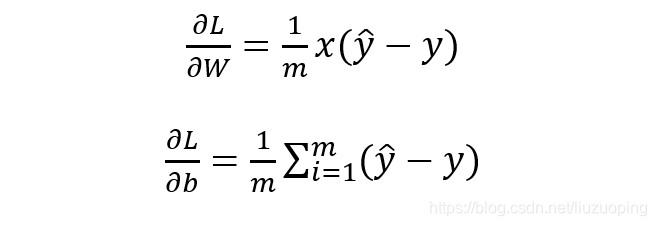
基于 W 和 b 的梯度进行权值更新即可求导参数的最优值,使得损失函数最小化,也即求得参数的极大似然估计。
Python 实现逻辑回归
和线性模型一样,要写一个完整的逻辑回归模型我们需要:sigmoid函数、模型主体、参数初始化、基于梯度下降的参数更新训练、数据测试与可视化展示
定义模型参数初始化函数:

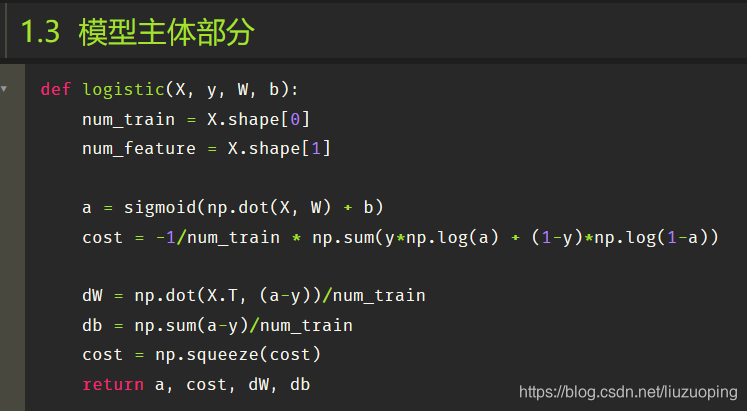
模型主体部分
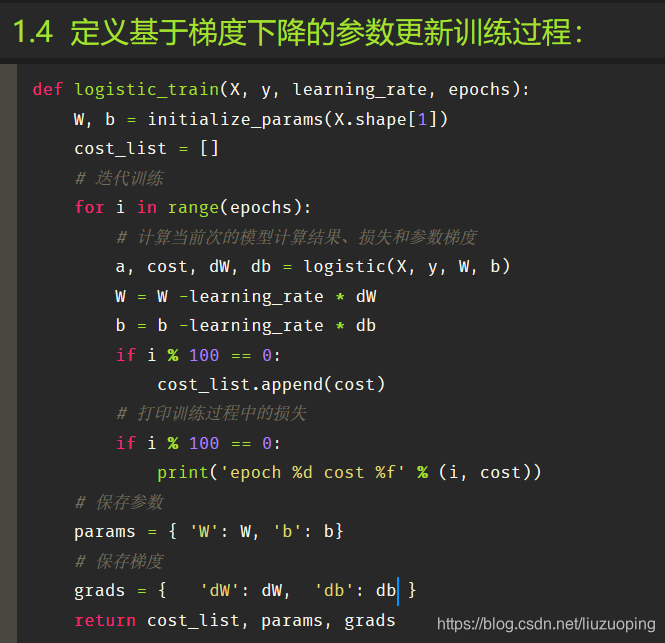
定义基于梯度下降的参数更新训练过程:
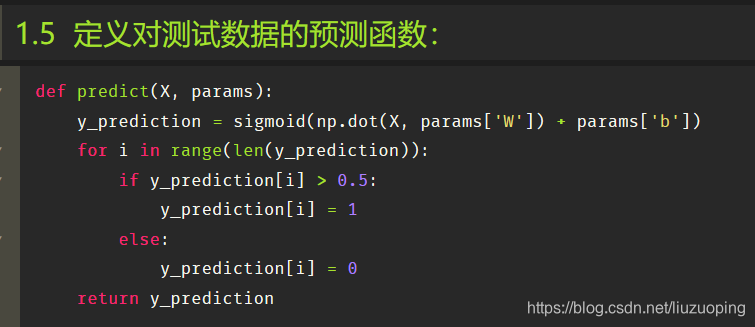
定义对测试数据的预测函数:
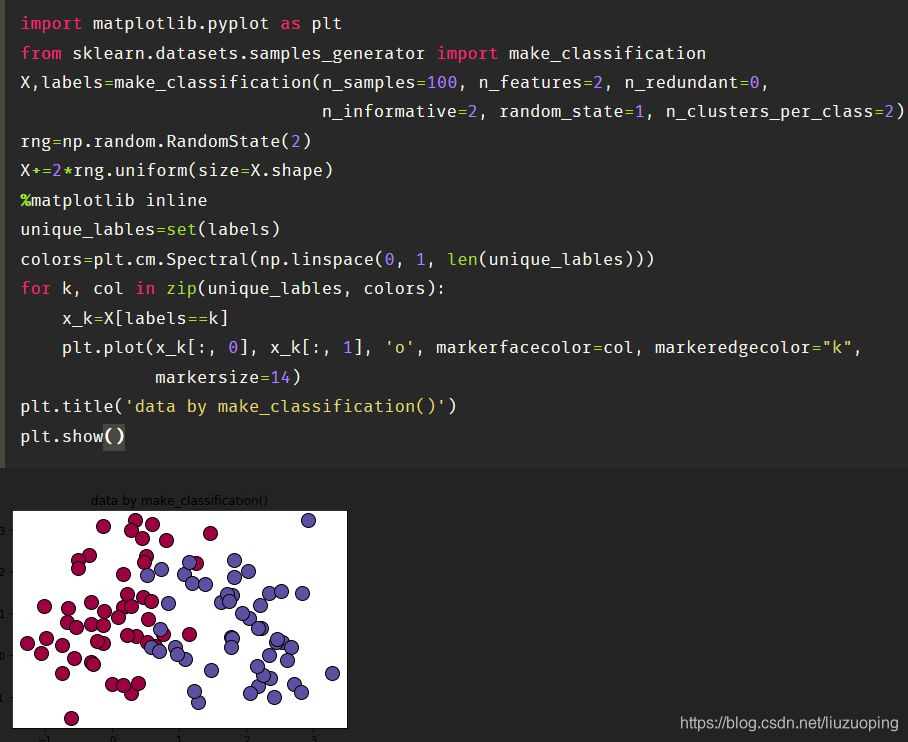
模型训练和测试:
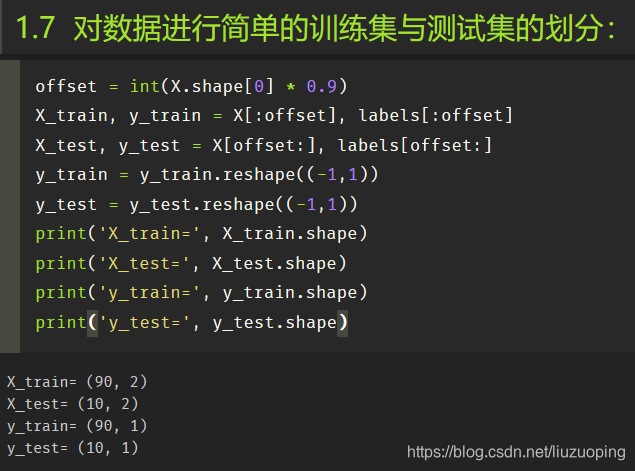
对数据进行简单的训练集与测试集的划分:
对训练集进行训练并对测试集数据进行预测:
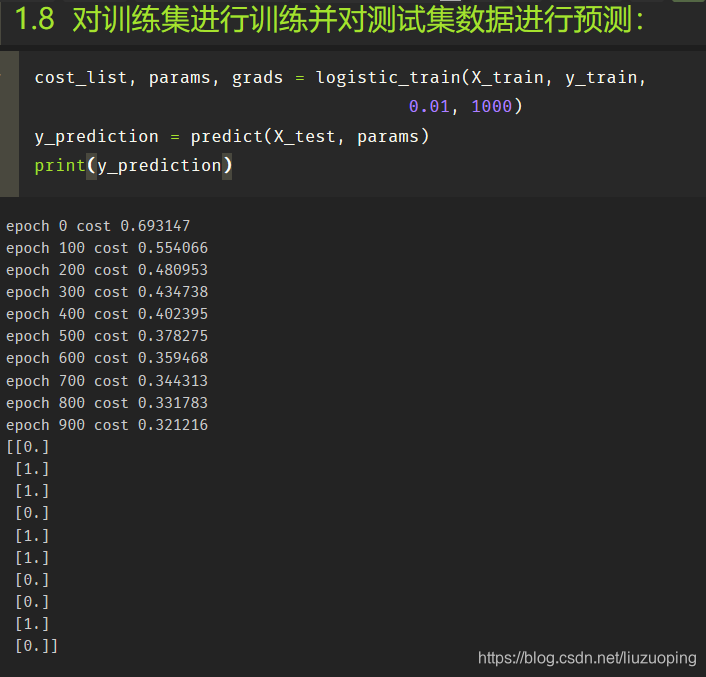
对训练集和测试集的准确率进行评估:
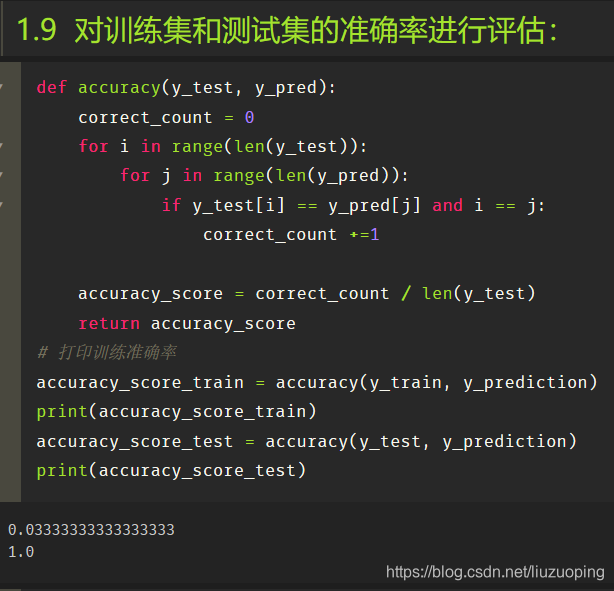
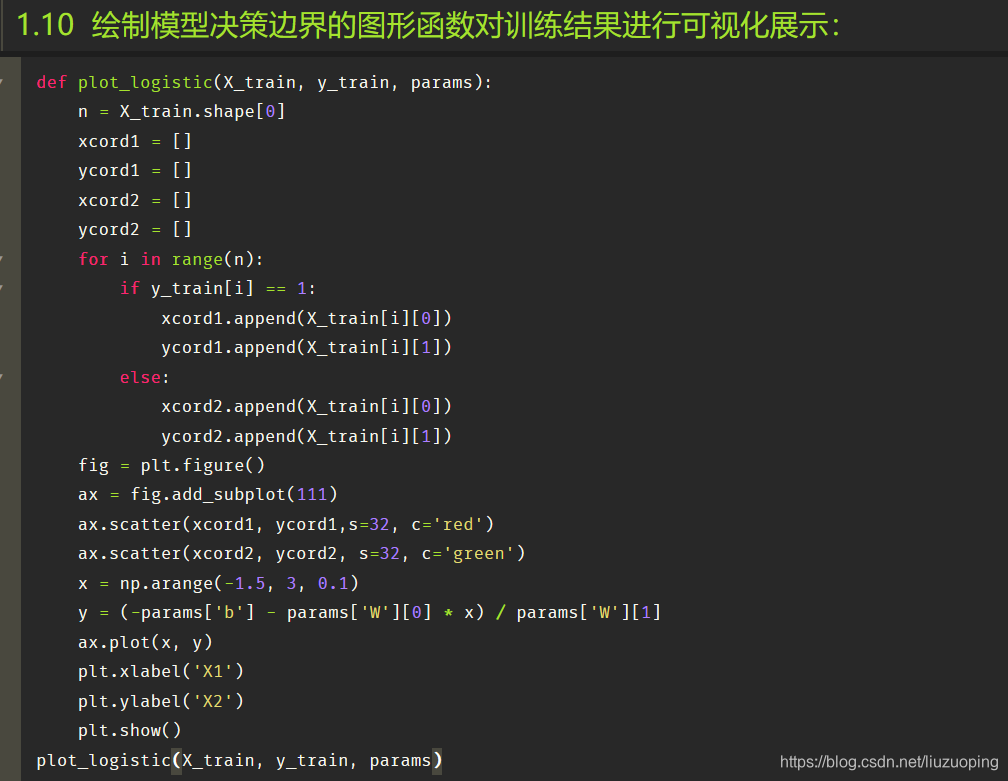
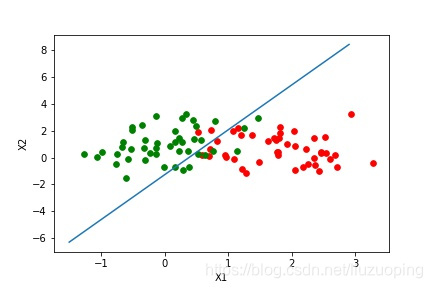
绘制模型决策边界的图形函数对训练结果进行可视化展示:
使用一个 python 类进行逻辑回归封装:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_classification
class logistic_regression():
def __init__(self):
pass
def sigmoid(self, x):
z = 1 / (1 + np.exp(-x))
return z
def initialize_params(self, dims):
W = np.zeros((dims, 1))
b = 0
return W, b
def logistic(self, X, y, W, b):
num_train = X.shape[0]
num_feature = X.shape[1]
a = self.sigmoid(np.dot(X, W) + b)
cost = -1 / num_train * np.sum(y * np.log(a) + (1 - y) * np.log(1 - a))
dW = np.dot(X.T, (a - y)) / num_train
db = np.sum(a - y) / num_train
cost = np.squeeze(cost)
return a, cost, dW, db
def logistic_train(self, X, y, learning_rate, epochs):
W, b = self.initialize_params(X.shape[1])
cost_list = []
for i in range(epochs):
a, cost, dW, db = self.logistic(X, y, W, b)
W = W - learning_rate * dW
b = b - learning_rate * db
if i % 100 == 0:
cost_list.append(cost)
if i % 100 == 0:
print('epoch %d cost %f' % (i, cost))
params = {
'W': W,
'b': b
}
grads = {
'dW': dW,
'db': db
}
return cost_list, params, grads
def predict(self, X, params):
y_prediction = self.sigmoid(np.dot(X, params['W']) + params['b'])
for i in range(len(y_prediction)):
if y_prediction[i] > 0.5:
y_prediction[i] = 1
else:
y_prediction[i] = 0
return y_prediction
def accuracy(self, y_test, y_pred):
correct_count = 0
for i in range(len(y_test)):
for j in range(len(y_pred)):
if y_test[i] == y_pred[j] and i == j:
correct_count += 1
accuracy_score = correct_count / len(y_test)
return accuracy_score
def create_data(self):
X, labels = make_classification(n_samples=100, n_features=2, n_redundant=0, n_informative=2, random_state=1, n_clusters_per_class=2)
labels = labels.reshape((-1, 1))
offset = int(X.shape[0] * 0.9)
X_train, y_train = X[:offset], labels[:offset]
X_test, y_test = X[offset:], labels[offset:]
return X_train, y_train, X_test, y_test
def plot_logistic(self, X_train, y_train, params):
n = X_train.shape[0]
xcord1 = []
ycord1 = []
xcord2 = []
ycord2 = []
for i in range(n):
if y_train[i] == 1:
xcord1.append(X_train[i][0])
ycord1.append(X_train[i][1])
else:
xcord2.append(X_train[i][0])
ycord2.append(X_train[i][1])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=32, c='red')
ax.scatter(xcord2, ycord2, s=32, c='green')
x = np.arange(-1.5, 3, 0.1)
y = (-params['b'] - params['W'][0] * x) / params['W'][1]
ax.plot(x, y)
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
if __name__ == "__main__":
model = logistic_regression()
X_train, y_train, X_test, y_test = model.create_data()
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
cost_list, params, grads = model.logistic_train(X_train, y_train, 0.01, 1000)
print(params)
y_train_pred = model.predict(X_train, params)
accuracy_score_train = model.accuracy(y_train, y_train_pred)
print('train accuracy is:', accuracy_score_train)
y_test_pred = model.predict(X_test, params)
accuracy_score_test = model.accuracy(y_test, y_test_pred)
print('test accuracy is:', accuracy_score_test)
model.plot_logistic(X_train, y_train, params)
运行结果:
(90, 2) (90, 1) (10, 2) (10, 1)
epoch 0 cost 0.693147
epoch 100 cost 0.521480
epoch 200 cost 0.416359
epoch 300 cost 0.347951
epoch 400 cost 0.300680
epoch 500 cost 0.266327
epoch 600 cost 0.240328
epoch 700 cost 0.220002
epoch 800 cost 0.203687
epoch 900 cost 0.190306
{'W': array([[ 2.04608084],
[-0.03964634]]), 'b': 0.12335926234285084}
train accuracy is: 0.9666666666666667
test accuracy is: 1.0
Process finished with exit code 0
LR和SVM的联系与区别
1、LR和SVM都可以处理分类问题,且一般都用于处理线性二分类问题(在改进的情况下可以处理多分类问题)
2、两个方法都可以增加不同的正则化项,如l1、l2等等。所以在很多实验中,两种算法的结果是很接近的。
区别:
1、LR是参数模型,SVM是非参数模型。
2、从目标函数来看,区别在于逻辑回归采用的是logistical loss,SVM采用的是hinge loss,这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
3、SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。
4、逻辑回归相对来说模型更简单,好理解,特别是大规模线性分类时比较方便。而SVM的理解和优化相对来说复杂一些,SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算。
5、logic 能做的 svm能做,但可能在准确率上有问题,svm能做的logic有的做不了。
怎么样,看完了是不是又get了新技能

下一篇我们学习KNN~
我本人是魔都某工科211小硕一枚
有一起交流学习的小伙伴可以加我wx
















 794
794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









