







什么是强化学习
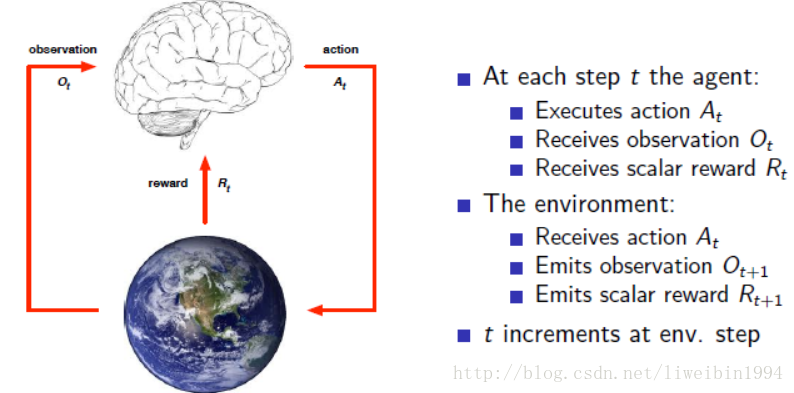
强化学习是想让一个智能体(agent)在不同的环境状态(state)下,学会选择那个使得奖赏(reward)最大的动作(action)。
上图即是一个强化学习的示意图。Agent可以看作是一个机器人,这个机器人在t时刻,通过观测(例如通过各种sensors来观测世界)环境得到agent自己所在的state(状态),接下来agent根据policy(策略)进行一些运算(思考,决策)之后,做出了一个action(动作)。这个action就会作用在Environment中,使得agent在environment中转移到一个新的状态state,并且在转移时获得一个即时的reward(奖赏)值(转移到不同的状态reward值不一定一样),这样Agent又可以通过在新state来选择一个动作。这样就可以累积很多reward值( R0,R1,...,Rt,...,RT R 0 , R 1 , . . . , R t , . . . , R T )。agent的目标是希望在达到终点的时候获得的累积reward最大。
按照上面所讲,其实强化学习就是一个agent与environment的交互过程,交互的过程是有一定的目的,就是为了获得尽可能多的reward。一个强化学习系统有以下四个主要的组成元素:policy(策略);reward(奖赏);value function(值函数);environment model(环境模型)。
policy
policy指的是agent选择动作的策略,agent就是根据这个策略来选择动作的。这里的策略不是指在某个具体的state(状态)下如何选择动作,而是从全局的角度。我们可以把policy看成一个关于状态s的函数f。这个函数的输入是状态s(需要把状态描述成可以输入的形式),输出则是一个动作。
在强化学习中,我们的目标就是要学习出了policy,用这个policy来选择动作可以使得我们最终获得的reward最大。
Reward
reward定义了强化学习问题的目的。它告诉agent你这个动作是好还是坏。
agent在t时刻执行一个动作之后可以获得一个 Rt R t ,它表明在这一步agent做得怎么样。从 0,1,...,t−1,t 0 , 1 , . . . , t − 1 , t 执行的一系列动作可以得到 R0,R1,...,Rt−1,Rt R 0 , R 1 , . . . , R t − 1 , R t 。agent的目的就是要使得这些R累积起来最大。这就是奖励最大化。
强化学习是基于奖励假设的(reward hypothesis)。
所谓的奖励假设就是:所有的目标都可以被描述为最大化期望累积奖励。也就是说,一个agent的目标是到达终点,就是从起点到终点的过程中要将奖励累积到最大。
agent的目标:选择一系列的动作去最大化总的未来奖励。(动作序列可能会很长才能到达目标)
也许你会问,并不是什么情况下只要做了一个动作就能知道有多少reward了,比如一个对话系统,机器人回复一句话之后并不能知道这句话究竟有多少reward。所以这是一个值得研究的问题。
状态state
从上面的描述,我们可以知道这整个过程就是一系列的observation,reward,action。这样就形成一系列的历史:
state is the information used to determine what happens next. 这就是状态,一般来说,状态是历史
Ht
H
t
的函数:
environment state Set S t e : 是环境的隐藏表示,事实上,它客观存在,但是agent观测到的不一定是全面的。所以是为了区分agent观测到的状态。而且agent执行一个动作之后,环境的状态就会有所变化,然后根据环境的状态产生reward反馈给agent。
而agent观测到的状态只是有利它所要的目标而已。比如:agent只需要一个摄像头看清前面的路就可以走了,它不需要知道声音。也就是agent观测一部分状态就可以做它想要完成的目标。
agent state Sat S t a : 如果agent能够完全观测到环境的状态,也就是 Sat==Set S t a == S t e ,这说明是一个马尔科夫决策过程。
value function
reward表示了agent选择一个动作的好坏。而value function则是表示从长期来看的好坏。也就是说,一个状态s的value是指在状态s下的平均reward。从状态s出发,有很多个动作可以选择,然后到达下一个状态,又有很多动作可以选择,这就像一棵树一样,不断展开。不同的动作会得到不同的reward。value function就是想表示一个状态s的平均reward。
environment model
如果我们知道环境的一切,我们就说这个环境是已知的,即model based。也就是说,在这种情况下,agent知道选择一个动作后,它的状态转移概率是怎样的,获得奖赏是怎样的。这些都知道的话,我们就可以使用动态规划的方法(DP)来解决问题。
但是在现实生活中,我们是很难知道状态之间的转移概率的。这种情况称为model free。所以我们无法直接使用动态规划的方法来解决问题。
exploration and exploitation(探索与利用)
上面讲了,在强化学习中,我们的目标就是为了累积奖赏最大化。那么在每次选择动作时,agent会选择在过去经历中它认为奖赏最大的动作去执行。但是有一个问题是,虽然有些动作一开始的奖赏很小。但是也许在这个动作的后面会有奖赏很大的时候呢?如果agent只是选取当前它认为奖赏最大的动作,那么它有可能陷入了局部最优。所以,agent需要去探索。探索那些奖赏比较小的动作,也许它后面的奖赏会很大。
当然,探索也不能一直去探索,因为可能你只有有限的时间,不能把时间一直放在探索上面。所以看起来这是一对矛盾体。如何平衡它们是一个很重要的事情。
RL 与 ML的区别
最后,说一下强化学习与机器学习的区别。
RL是没有监督者的也就是没有人告诉agent做这个动作是最好的,而是会告诉agent做这个动作能够获得多少奖励。它是一个不断试错的过程,通过很多次的尝试之后,agent慢慢修改自己的策略让自己去执行能够获得最大奖励的动作。
反馈是延时的,而不是即时。做某个动作能够获得的奖励有时并不是马上就反馈给agent的,而是有很大的时间延迟。就好像你下一步棋并不知道好坏,而是要等到最后你赢了你才知道下这一步棋是好的。或者说你做一个决定不是马上就能知道结果,而是要过很久之后,才知道当初的决定是错的还是对的。
时序是很重要的。也就是动作是一步一步来的。agent的动作会影响后续的子序列。机器学习中的数据可以看成是独立同分布的,但是在RL中,是一个动态的系统,每一步的动作会影响到后续的动作或者reward。
参考资料:
https://zhuanlan.zhihu.com/p/28084904
David Silver强化学习公开课














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









