







回顾
- 在上一节中,我们主要是利用函数近似来将
Vπ(s)
V
π
(
s
)
与
Qπ(s,a)
Q
π
(
s
,
a
)
参数化:
而我们的策略 π π 则是从Q值中产生的。比如我们一直使用的 ϵ−greedy ϵ − g r e e d y 探索方法就是根据最大的Q值来选择动作(action)。没有Q值的话就无法使用这个方法了。也就是这个策略的更新是根据Q值的变化的。那么在本节,我们将直接对策略进行参数化而不是利用Q值。即:
这样的话,这个策略 π π 就不是概率集合而是一个函数了。这个策略函数表明在给定一个状态s的情况下,采取任何可能行为的概率,事实上,它是一个概率密度函数,就是说在实际应用策略的时候,是按照这个概率分布进行action采样的。
我们要做的是利用参数化的策略函数,通过调整这些参数来得到一个最优的策略。如何评价一个策略是否优秀呢?就是说如果遵循这个策略可以得到较多的奖励,那么这个策略就是优秀的策略。所以具体的做法就是设计一个关于策略的目标函数,通过梯度下降算法优化参数,最终使得惩罚最小化(奖励最大化)。
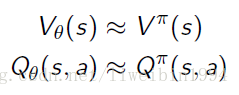
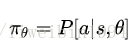
Policy Gradient
为什么要用基于策略的学习?
- 基于策略的学习可能会具有更好的收敛性,这是因为基于策略的学习虽然每次只改善一点点,但总是朝着好的方向在改善;但是上讲提到有些价值函数在后期会一直围绕最优价值函数持续小的震荡而不收敛。
- 在对于那些拥有高维度或连续状态空间来说,使用基于价值函数的学习在得到价值函数后,制定策略时,需要比较各种行为对应的价值大小,这样如果行为空间维度较高或者是连续的,则从中比较得出一个有最大价值函数的行为这个过程就比较难了,这时候使用基于策略的学习就高效的多。
- 能够学到一些随机策略,下文举了一个很好的例子;但是基于价值函数的学习通常是学不到随机策略的。
- 有时候计算价值函数很困难。比如当小球从空中掉下来你需要通过左右移动去接住它时,计算小球在某一个位置(状态)时采取什么样的行动(action)是很困难的。但是基于策略函数就简单了,只需要朝着小球落地的方向移动修改策略就好了。
什么时候使用基于价值的学习?什么时候使用基于策略的学习?
- 具体问题具体分析,根据需要评估的问题的特点来决定使用哪一种学习方式。
- 随机策略有时是最优策略。比如剪刀石头布这个游戏,如果你是按照某一种策略来出拳的话,很容易让别人抓住你的规律,然后你就会输了。所以最好的策略就是随机出拳,让别人猜不到。所谓的确定性策略,是说只要给定一个状态s,就会输出一个具体的动作a,而且无论什么时候到达状态s,输出的动作a都是一样的。而随机策略是指,给定一个状态s,输出在这个状态下可以执行的动作的概率分布。即使在相同状态下,每次采取的动作也很可能是不一样的。
- 基于价值函数的策略有时无法得到最优策略。
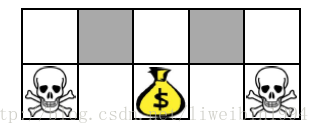
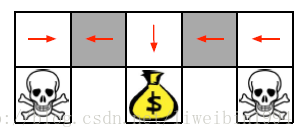
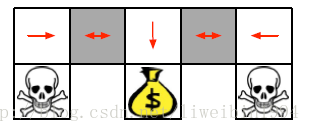
- 在这个图中,agent需要尽量不遇到骷颅头而去拿到钱包。agent所在的状态就是图中上方5个格子。对于这个环境的描述我们可以使用坐标来表示每个格子(状态),我们也可以使用格子某个方向是否有墙来作为特征描述这些格子。如果使用后者的话,我们就会发现两个灰色格子的状态描述是一样的,也就是视频中说的重名(Aliased)。它们的状态描述一样,但是我们可以看到(上帝视角)当agent处于这两个灰色格子时,应该采取的行动是不一样的。也就是说,当agent在左边的灰色格子时,它的策略应该是向东走,当它在右边的灰色格子时,它应该向西走。这样的话,就会出现在同一状态下,需要采取策略不同的情况。而对于基于价值的学习方法,策略是固定的,所以就会出现下面这样的策略:
- 或者灰色格子一直向东的策略。
- 所以出现这种状态相同,需要采取的行动不同的这种情况时,随机策略就会比确定性的策略好。即:
基于策略的学习要如何来优化策略呢?也就是如何定义目标函数?
- 首先我们要知道我们的目标是:对于一个带有参数 θ θ 的策略 πθ(s,a) π θ ( s , a ) ,我们要找到最优的 θ θ 。 但是,我们如何去评价一个策略 πθ π θ 的好坏呢?
start value:在能够产生完整Episode的环境下,也就是在个体可以到达终止状态时,我们可以用这样一个值来衡量整个策略的优劣:从某状态s1算起知道终止状态个体获得的累计奖励。这个值称为start value. 这个数值的意思是说:如果个体总是从某个状态s1开始,或者以一定的概率分布从s1开始,那么从该状态开始到Episode结束个体将会得到怎样的最终奖励。这个时候算法真正关心的是:找到一个策略,当把个体放在这个状态s1让它执行当前的策略,能够获得start value的奖励。这样我们的目标就变成最大化这个start value:
average value:对于连续环境条件,不存在一个开始状态,这个时候可以使用 average value。意思是考虑我们个体在某时刻处在某状态下的概率,也就是个体在该时刻的状态分布,针对每个可能的状态计算从该时刻开始一直持续与环境交互下去能够得到的奖励,按该时刻各状态的概率分布求和:
- dπθ(s) d π θ ( s ) 的意思是在策略 πθ π θ 下,关于状态s的一个分布。因为是连续环境下,所以在某个时刻,agent在哪一个状态下是由这个分布决定的。意义就是agent在某个时刻有处于所有状态的可能性。
- average reward per time-step:
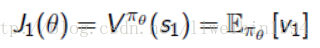
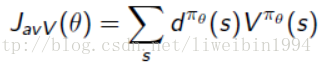
优化目标函数
有限差分策略梯度(Finite difference Policy Gradient)
上面三种方式找到的是目标函数,接下来就是如何优化目标函数,所以,可以说策略梯度就是一个优化问题。
策略梯度(Policy Gradient)
- 令 J(θ) J ( θ ) 为任何类型的策略目标函数,策略梯度算法可以使 J(θ) J ( θ ) 沿着其梯度上升至局部最大值。
- 其中 ▽θJ(θ) ▽ θ J ( θ ) 是策略梯度:
有限差分计算策略梯度:
- 上面策略梯度的算法可能比较复杂,特别是梯度函数本身很难得到的时候。具体的做法就是对 θ θ 的每个分量都单独求差分来估算梯度:
- 其中 uk u k 是一个单位向量,只有在第k个维度上的值为1,其它为0。
- 这种算法简单,而且不需要策略函数是可微分的,可以用于任意梯度。但它有噪声,而且很多时候不高效。
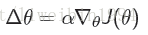
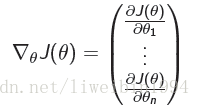
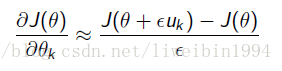
蒙特卡罗策略梯度(Monte-Carlo Policy Gradient)
- 对于一个关于变量 θ θ 的函数 πθ(s,a) π θ ( s , a ) ,可以利用Likelihood ratios的概念,将其化为:
我们定义score function为: ▽θlogπθ(s,a) ▽ θ l o g π θ ( s , a )
softmax策略
- 其实就是针对action是离散的情况,softmax就可以输出在某个状态下所有可能执行的动作的概率。
高斯策略
- 高斯策略用于连续的动作空间。比如,如果控制机器人行走要调整流经某个电机的电流值,而这个电流值是连续值。
- 高斯策略就需要用到均值和方差,一般对于均值来说会用参数化来表示,例如用线性组合:
- 方差可以使用固定值也可以像均值那样参数化。
- 那么,我们知道行为(action)是对应一个具体的数值,这个数值就是从以 μ(s) μ ( s ) 为均值, σ σ 为标准差的高斯分布中随机采样产生的:
- 所以score function就变成(其实就是对高斯函数进行求导就得到下面的公式了):
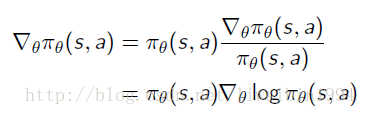
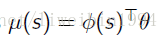
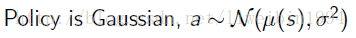

以上只是给了关于Score函数的直观表示,更深入的理解需要结合策略梯度学习来讲解。不过有了这些常用的策略,我们可以看看这些公式是如何体现在优化策略的目标函数里的,这就是后文要介绍的:策略梯度定理。
策略梯度定理(Policy Gradient Theorem)
- 上面说的是关于Score函数的定义以及计算,但是无论如何,我们的真正目标是对目标函数进行梯度计算,即 ▽θJ(θ) ▽ θ J ( θ )
根据策略梯度定理,无论是上面说的三种目标函数的哪一种,它们的梯度都是一样的,如下所示:

问题:上面的公式的期望是指什么?不同的s和a,对 θ θ 的梯度不一样,那么期望是指所有s与a的组合的梯度值的均值吗?应该是这样理解,毕竟在一个s状态下,都有一个关于 θ θ 的策略函数,通过这个函数来找到要执行的动作a。而不同的状态下, θ θ 值是不一样的。
有了上述公式,我们就可以着手设计算法,解决实际问题了。在强化学习里,在谈到学习算法时,应该马上能想到三大类算法:动态规划(DP)、蒙特卡洛(MC)学习和时序差分(TD)学习。我们先从MC学习开始讲起。
有了上面的铺垫,蒙特卡罗策略梯度具体要怎么算的过程就比较清晰了。
蒙特卡罗策略梯度
之所以可以蒙特卡罗,是因为我们可以得到完整的episode。我们应用策略梯度理论,使用随机梯度上升来更新参数,对于公式里的期望,我们通过采样的形式来替代,即使用t时刻的收获(return)作为当前策略下行为价值的无偏估计。
算法过程如下:

Actor-Critic 策略梯度
使用蒙特卡洛策略梯度方法使用了收获作为状态价值的估计,它虽然是无偏的,但是噪声却比较大,也就是变异性(方差)较高。如果我们能够相对准确地估计状态价值,用它来指导策略更新,那么是不是会有更好的学习效果呢?这就是Actor-Critic策略梯度的主要思想。
通过使用基线的方式来减少方差:
其基本思想是从策略梯度里抽出一个基准函数B(s),要求这一函数仅与状态有关,与行为无关,因而不改变梯度本身。 B(s)的特点是能在不改变行为价值期望的同时降低其Variance。当B(s)具备这一特点时,下面的推导成立:
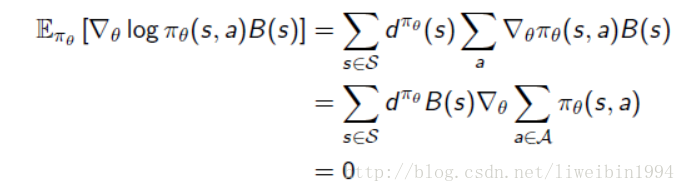
推导过程解释:策略函数对数的梯度与基准函数乘积的期望可以表示为第一行等式对策略函数梯度与B(s)的乘积对所有状态及行为分布求的形式,这步推导主要是根据期望的定义,以及B是关于状态s的函数而进行的。由于B(s)与行为无关,可以将其从针对行为a的求和中提出来,同时我们也可以把梯度从求和符号中提出来(梯度的和等于和的梯度),从而后一项求和则变成:策略函数针对所有行为的求和,这一求和根据策略函数的定义肯定是1,而常熟的梯度是0。因此总的结果等于0 。那么如何设计或者寻找这样一个B(s)呢?
原则上,和行为无关的函数都可以作为B(s)。一个很好的B(s)就是基于当前状态的状态价值函数:
这样我们可以通过使用一个advantage function,定义为:
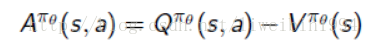
这个advantage function 的现实意义在于,当个体采取行为a离开s状态时,究竟比该状态s总体平均价值要好多少。
《an introduction RL 》这本书对B(s)的一种直观解释:
In some states all actions have high values and we need a high baseline to differentiate the higher valued actions from the less highly valued ones; in other states all actions will have low values and a low baseline is appropriate.
参考:
David Silver强化学习公开课
https://zhuanlan.zhihu.com/p/28348110
《Reinforcement+Learning:An+Introduction》














 807
807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









