







进阶课程需要一些基础知识:
1、机器学习基础知识
2、概率论知识
3、线性代数和微积分
4、python编程
我们需要知道的机器学习基础知识:
1、线性回归:均方误差(MSE)、解析解
2、逻辑回归:模型、交叉熵损失、类概率估计
3、线性模型的梯度下降、均方误差(MSE)和交叉熵的求导
4、过拟合问题
5、线性模型的正则化
一、线性回归模型(linear model)
回归任务:收入预测、电影评分等预测结果是真实的数字
分类任务:对象识别、主题分类等预测结果是代无别的结果
线性回归模型:
线性回归模型以及参数:W系数(coefficients)、B偏差(bias),一共d+1个参数,求W参数的方法有以下两种
1、训练模型是均方误差(MSE)最小化的过程
2、W系数也可以通过帽子矩阵来求解,得出W的精确解,
但是对高维数据,求解X转置是很困难的,因此一般使用均方误差(MSE)最小化优化参数

线性分类模型:
二分类问题
多分类问题
分类问题使用准确率来评价,预测结果与y一致则为正确,否则错误
可以使用softmax继续进行转化测量这些时间之间的概率分布之间的距离

因此我们可以使用交叉熵损失函数,交叉熵只是真实类别的预测类别概率的负对数

二、梯度下降
梯度下降方法适用于均方误差(MSN)和交叉熵损失函数,使用梯度下降过程就是寻找损失函数最小化的过程

梯度下降如何实现参数优化的问题呢(损失函数最小)
t-1次的w参数与学习率和梯度向量的乘积之差仿佛更新参数,直到梯度向量达到结束循环的条件。

在这个过程中涉及到以下几个方面:
1、W参数如何初始化
2、η学习率怎么选取
3、什么时候结束循环
4、如何选取梯度向量去近似逼近
随机梯度下降的方法的原理:

随机梯度下降的特点
1、更新参数的过程中会出现更多的噪音干扰,loss不会是始终持续下降
2、没更新一次参数只需要一个样本
3、可以在在线环境中使用
4、需要谨慎选择学习率η

批量梯度下降(mini-batch gradient descent),每次使用m个样本进行训练
三、模型正则化
1、添加正则项对模型参数进行惩罚,正则项可选择L1、L2
2、数据降维
3、数据增强(data augmentation)
4、dropout
5、Early stopping
6、收集更多的数据

四、深度学习的优化方法:
1、动量(momentum):动量的引入就是为了加快学习过程,特别是对于高曲率、小但一致的梯度,或者噪声比较大的梯度能够很好的加快学习过程。动量的主要思想是积累了之前梯度指数级衰减的移动平均(前面的指数加权平均),得到加速学习过程的目的。(引用自博客https://blog.csdn.net/u012328159/article/details/80311892)
原理如下:

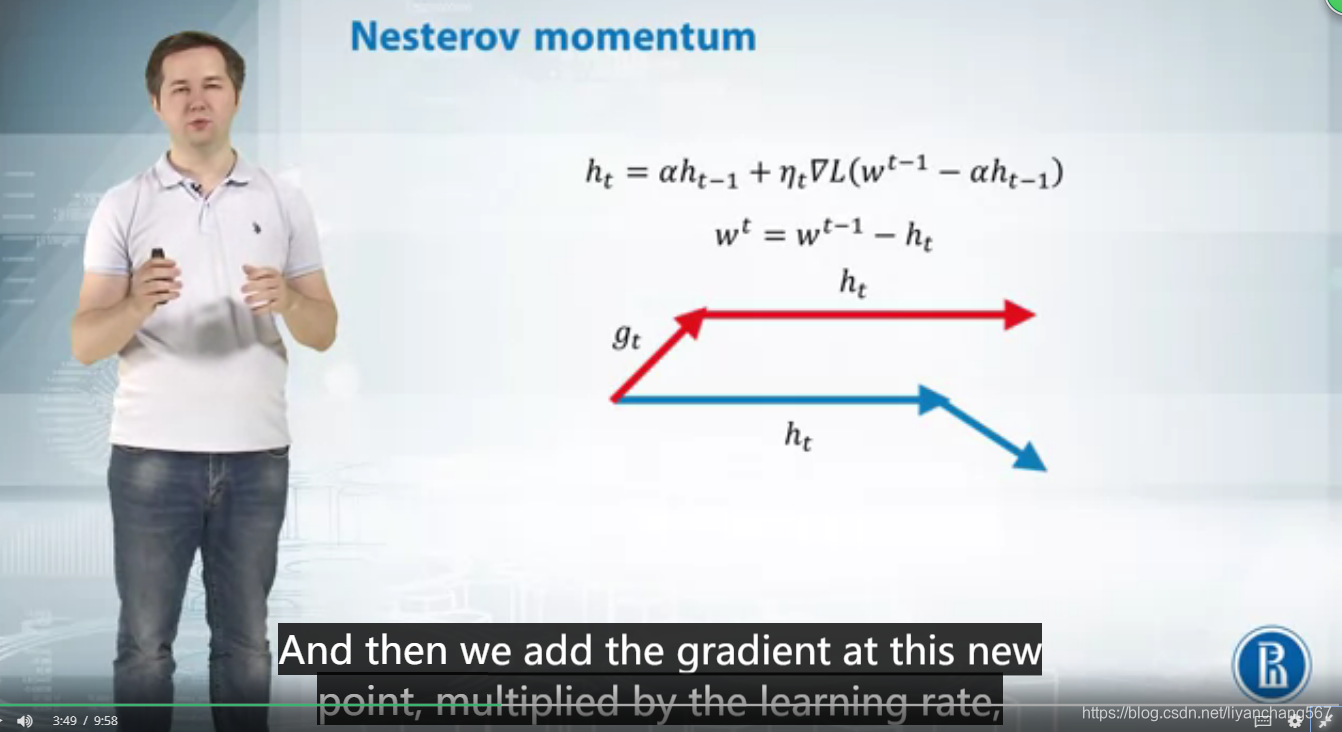
2、Nesterov Momentum是对Momentum的改进,可以理解为nesterov动量在标准动量方法中添加了一个校正因子。用一张图来形象的对比下momentum和nesterov momentum的区别(引用自https://blog.csdn.net/u012328159/article/details/80311892)
原理如下:
3、AdaGrad:通常,我们在每一次更新参数时,对于所有的参数使用相同的学习率。而AdaGrad算法的思想是:每一次更新参数时(一次迭代),不同的参数使用不同的学习率。(引用自博客https://blog.csdn.net/u012328159/article/details/80311892)
原理如下:

4、RMSprop(root mean square prop):RMSprop是hinton老爷子在Coursera的《Neural Networks for Machine Learning》lecture6中提出的,这个方法并没有写成论文发表(不由的感叹老爷子的强大。。以前在Coursera上修过这门课,个人感觉不算简单)。同样的,RMSprop也是对Adagrad的扩展,以在非凸的情况下效果更好。和Adadelta一样,RMSprop使用指数加权平均(指数衰减平均)只保留过去给定窗口大小的梯度,使其能够在找到凸碗状结构后快速收敛。直接来看下RMSprop的算法(来自lan goodfellow 《deep learning》(引用自博客https://blog.csdn.net/u012328159/article/details/80311892)
原理如下:


5、Adam(Adaptive Moment Estimation):Adam实际上是把momentum和RMSprop结合起来的一种算法,算法流程是(摘自adam论文)(引用自博客https://blog.csdn.net/u012328159/article/details/80311892)
















 2608
2608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









