







表分区就是把逻辑上的一个大表分割成物理上的几个小块。表分区能够快速的删除历史数据,提高查询性能。下面我们将讲述分区表的创建过程。
创建一个学生表,按照学生的成绩对该表分区。插入学生信息时,根据成绩将信息存入不同的分区表中。
1.创建“父表”
所有分区都从“父表”继承,通常情况下,“父表”没有数据。
学生信息包括学号,姓名和成绩。
CREATE TABLE student (
id int,
name varchar(20),
score int
);2.创建“子表”
“子表”继承自“父表”,通常情况下,“子表”不会增加任何数据,子表又称为分区表。
根据学生的成绩创建子表。
CREATE TABLE student_A(CHECK(score >= 90 and score <= 100))INHERITS(student);
CREATE TABLE student_B(CHECK(score >= 80 and score < 90))INHERITS(student);
CREATE TABLE student_C(CHECK(score >= 70 and score < 80))INHERITS(student);
CREATE TABLE student_D(CHECK(score >= 60 and score < 70))INHERITS(student);
CREATE TABLE student_E(CHECK(score >= 0 and score < 60))INHERITS(student);3.给分区表加索引
对于每一个分区,可以在关键字字段上创建索引,也可以在其它需要的字段上创建。
在分区表上,将学号作为主键,并在成绩上建立索引。
ALTER TABLE student_A ADD PRIMARY KEY(id);
ALTER TABLE student_B ADD PRIMARY KEY(id);
ALTER TABLE student_C ADD PRIMARY KEY(id);
ALTER TABLE student_D ADD PRIMARY KEY(id);
ALTER TABLE student_E ADD PRIMARY KEY(id);
CREATE INDEX ON student_A(score);
CREATE INDEX ON student_B(score);
CREATE INDEX ON student_C(score);
CREATE INDEX ON student_D(score);
CREATE INDEX ON student_E(score);4.定义规则或触发器
规则或触发器能使对主表的数据插入重定向到合适的分区表。
CREATE OR REPLACE FUNCTION student_insert_trigger()
RETURNS TRIGGER AS $$
BEGIN
IF (NEW.score >= 90 and NEW.score <= 100) THEN INSERT INTO student_A VALUES(NEW.*);
ELSEIF(NEW.score >= 80 and NEW.score < 90) THEN INSERT INTO student_B VALUES(NEW.*);
ELSEIF(NEW.score >= 70 and NEW.score < 80) THEN INSERT INTO student_C VALUES(NEW.*);
ELSEIF(NEW.score >= 60 and NEW.score < 70) THEN INSERT INTO student_D VALUES(NEW.*);
ELSEIF(NEW.score >= 0 and NEW.score < 60) THEN INSERT INTO student_E VALUES(NEW.*);
ELSE RAISE EXCEPTION 'score out of range';
END IF;
RETURN NULL;
END;
$$
LANGUAGE plpgsql;
CREATE TRIGGER insert_trigger
BEFORE INSERT ON student
FOR EACH ROW EXECUTE PROCEDURE student_insert_trigger();5.插入数据
INSERT INTO student VALUES(1,'April',98);
INSERT INTO student VALUES(2,'Harris',77);6.查看数据
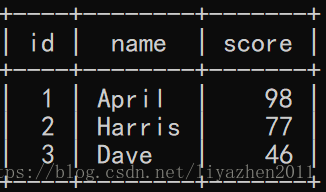
select * from student;执行结果:
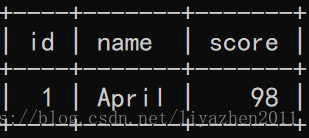
select * from student_a;执行结果:
select * from student_c; 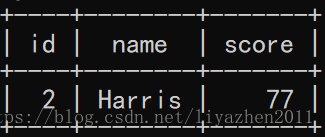
注:确保constraint_exclusion里的配置参数postgresql.conf是打开的。此时,如果查询中where子句的过滤条件与分区的约束条件匹配,那就会只查询这个分区,不会查询其他分区。














 2317
2317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









