







声明:工作以来主要从事TTS,VC以及ASR等等相关工作,平时看些文章做些笔记。文章中难免存在错误的地方,还望大家海涵。平时搜集一些资料,方便查阅学习:TTS 论文列表 http://yqli.tech/page/tts_paper.html TTS 开源数据 http://yqli.tech/page/data.html。如转载,请标明出处。欢迎关注微信公众号:低调奋进
(本文稍长,希望大家看完,而不是收藏之后等以后慢慢看)
大家平时对Incremental TTS(iTTS)关注较少,可能会问iTTS是如何工作?完成那些工作?对于iTTS的介绍屈指可数,今年出来的几篇语音合成的survey(可以参考语音合成论文优选:语音合成综述(2021)https://mp.weixin.qq.com/s/m6juWxML0E_e83fvs4k0Aw)也没有相关主题的总结,因此我这里就唠一唠该方向的研究。iTTS主要是根据部分语境(当前word以及前边已经观察到的word序列)来合成音频,其研究没有被重视的原因主要其语音质量无法与整句合成效果好,但其latency理论上是纯正的streaming。再进入主题之前,我先把几个术语捋一捋。ASR很多研究涉及streaming,该streaming对应本文的increamental,因此我们称增量式tts为streaming TTS或者increamental TTS。另外,real-time语音合成系统主要特点就是latency小,因此很多文章和研究人员习惯把具备局部streaming特点的TTS也称为streaming TTS(主要latency较小),这里我们没必要较真(有位朋友曾跟我探讨过streaming TTS和real-time TTS区别,其实real-time TTS是包括streaming TTS)。接下来我们进入主题。
本文主要讲解以下的几篇文章
segment-level的iTTS
1 Neural iTTS: Toward Synthesizing Speech in Real-time with End-to-end Neural Text-to-Speech Framework
2019.09
https://ahcweb01.naist.jp/papers/conference/2019/201909_SSW_tomoya-ya_1/201909_SSW_tomoya-ya_1.paper.pdf
使用future context的探索研究
2 What the Future Brings: Investigating the Impact of Lookahead for Incremental Neural TTS
2020.09.04
https://arxiv.org/pdf/2009.02035.pdf
3 Alternate Endings: Improving Prosody for Incremental Neural TTS with Predicted Future Text Input
2021.02.15
https://arxiv.org/pdf/2102.09914.pdf
4 Incremental Text-to-Speech Synthesis Using Pseudo Lookahead with Large Pretrained Language Model
2021.04.14
https://arxiv.org/pdf/2012.12612.pdf
5 Low-Latency Incremental Text-to-Speech Synthesis with Distilled Context Prediction Network
2021.09.22
https://arxiv.org/pdf/2109.10724.pdf
局部streaming,但具备更多的落地场景
6 High Quality Streaming Speech Synthesis with Low, Sentence-Length-Independent Latency
interspeech 2020
https://www.isca-speech.org/archive/Interspeech_2020/pdfs/2464.pdf
第一篇Neural iTTS: Toward Synthesizing Speech in Real-time with End-to-end Neural Text-to-Speech Framework
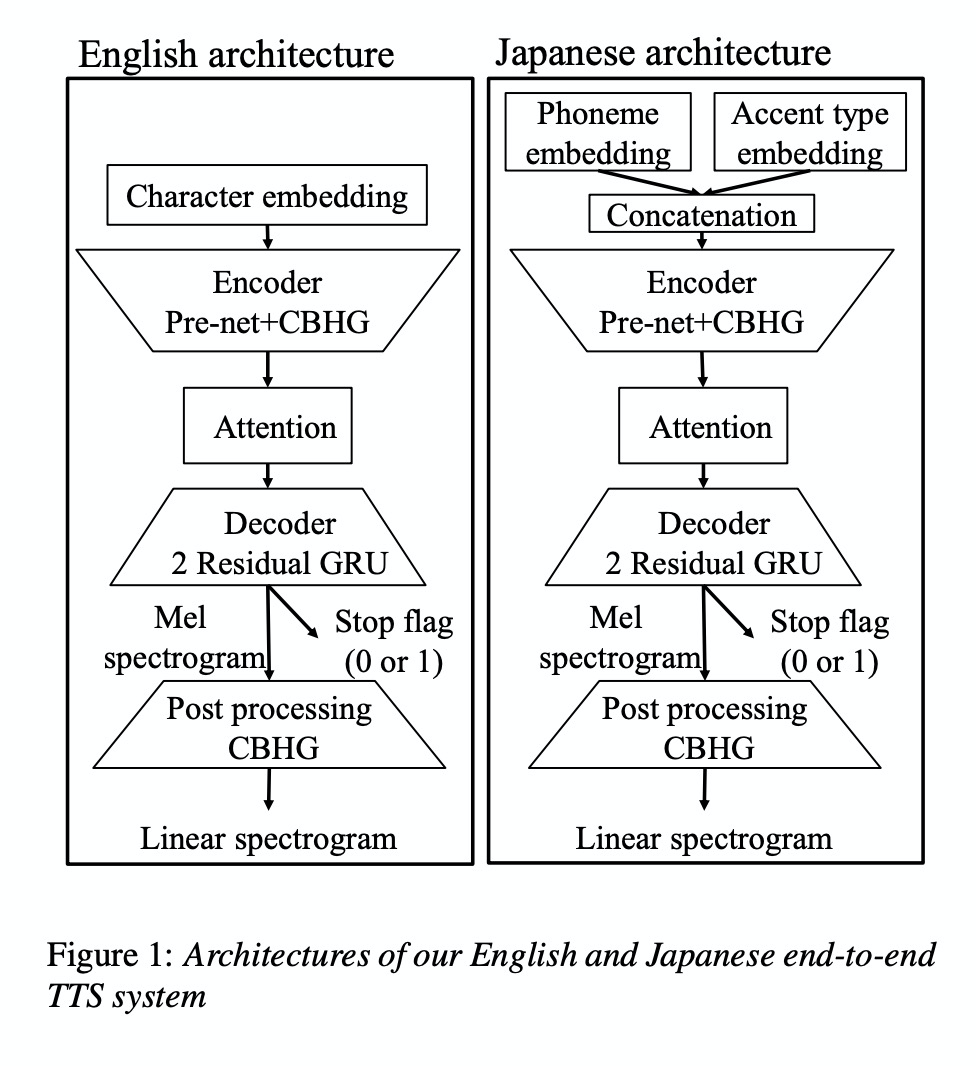
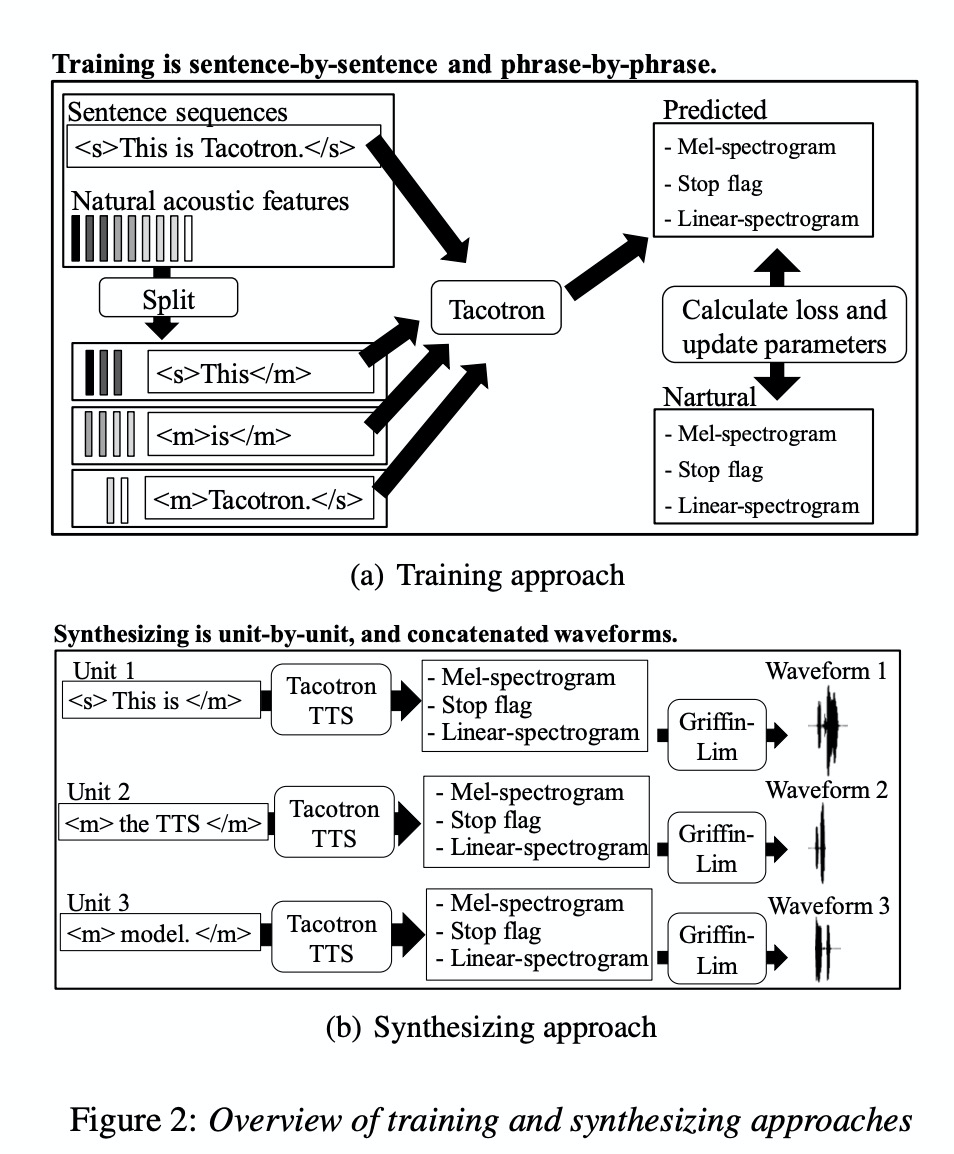
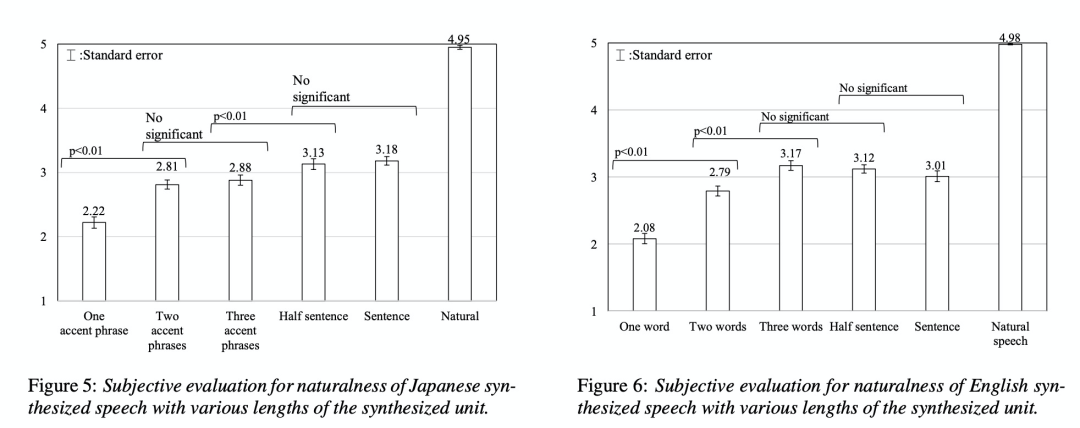
这篇文章是最早在基于神经网络的TTS上进行iTTS的研究,其主要在tacotron(图1)架构上进行english和japanese的试验。该iTTS如2所示进行片段式segment的合成,即逐块chunk模式合成然后再进行拼接,结果为图5图6所示。
第二篇What the Future Brings: Investigating the Impact of Lookahead for Incremental Neural TTS
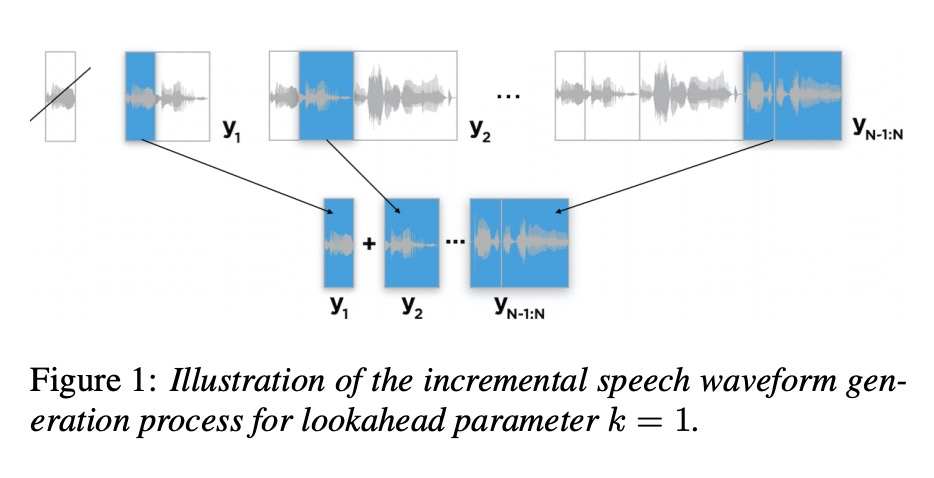
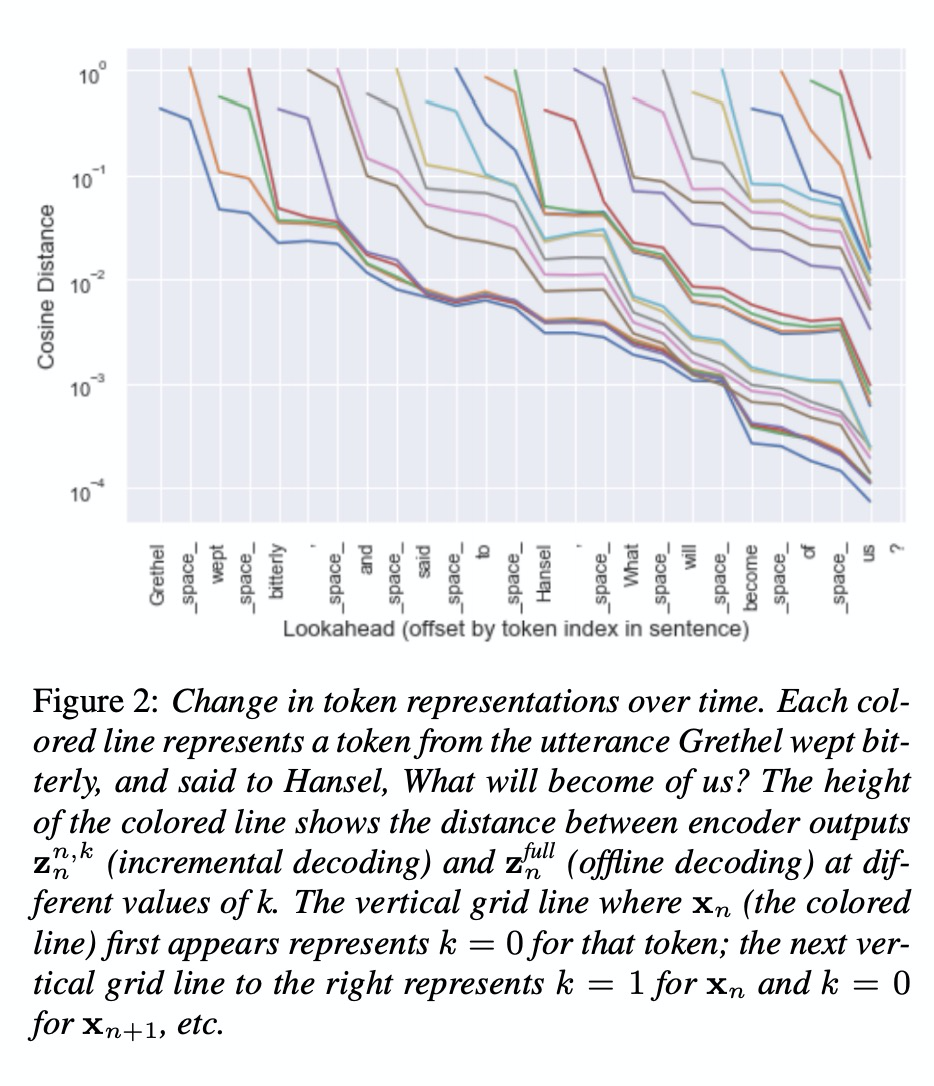
该篇文章主要探索iTTS需要具备多长的future context才能提高语音合成质量。本文是在tacotron系统上进行的实验,encoder和decoder都要做相应的处理。encoder的处理如table1所示,其中n代表一句话中该word的位置,k是向后看几步。decoder部分的如图1所示,合成增量的每部分音频,然后进行拼接。

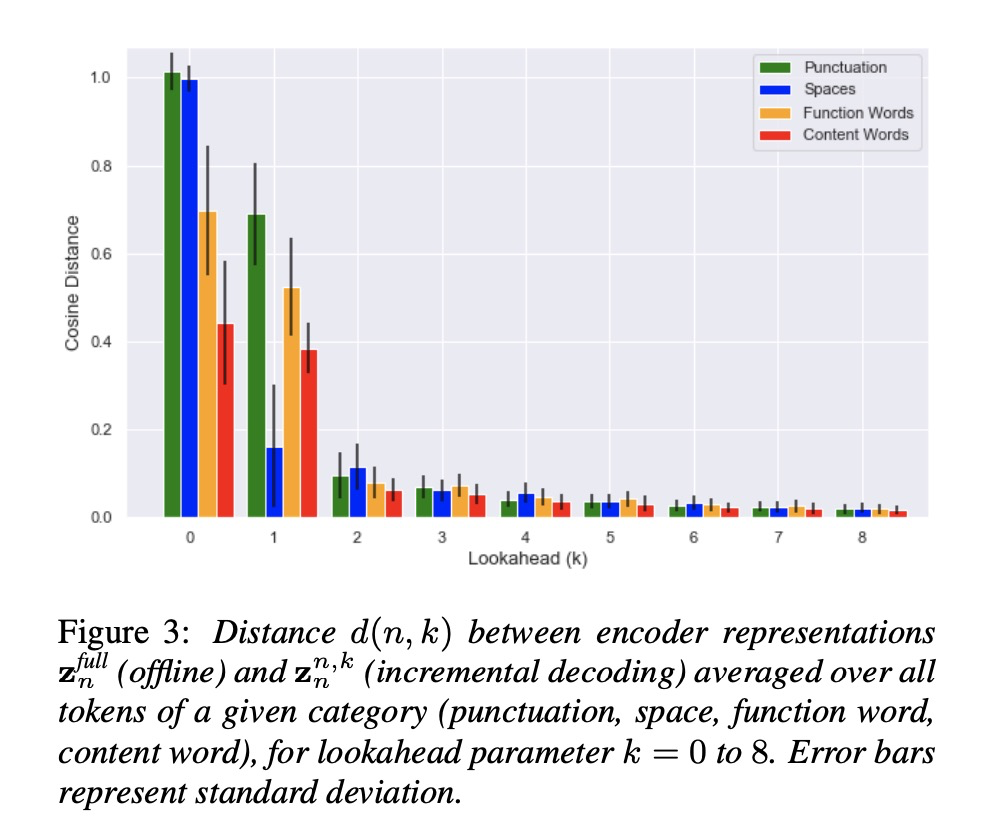
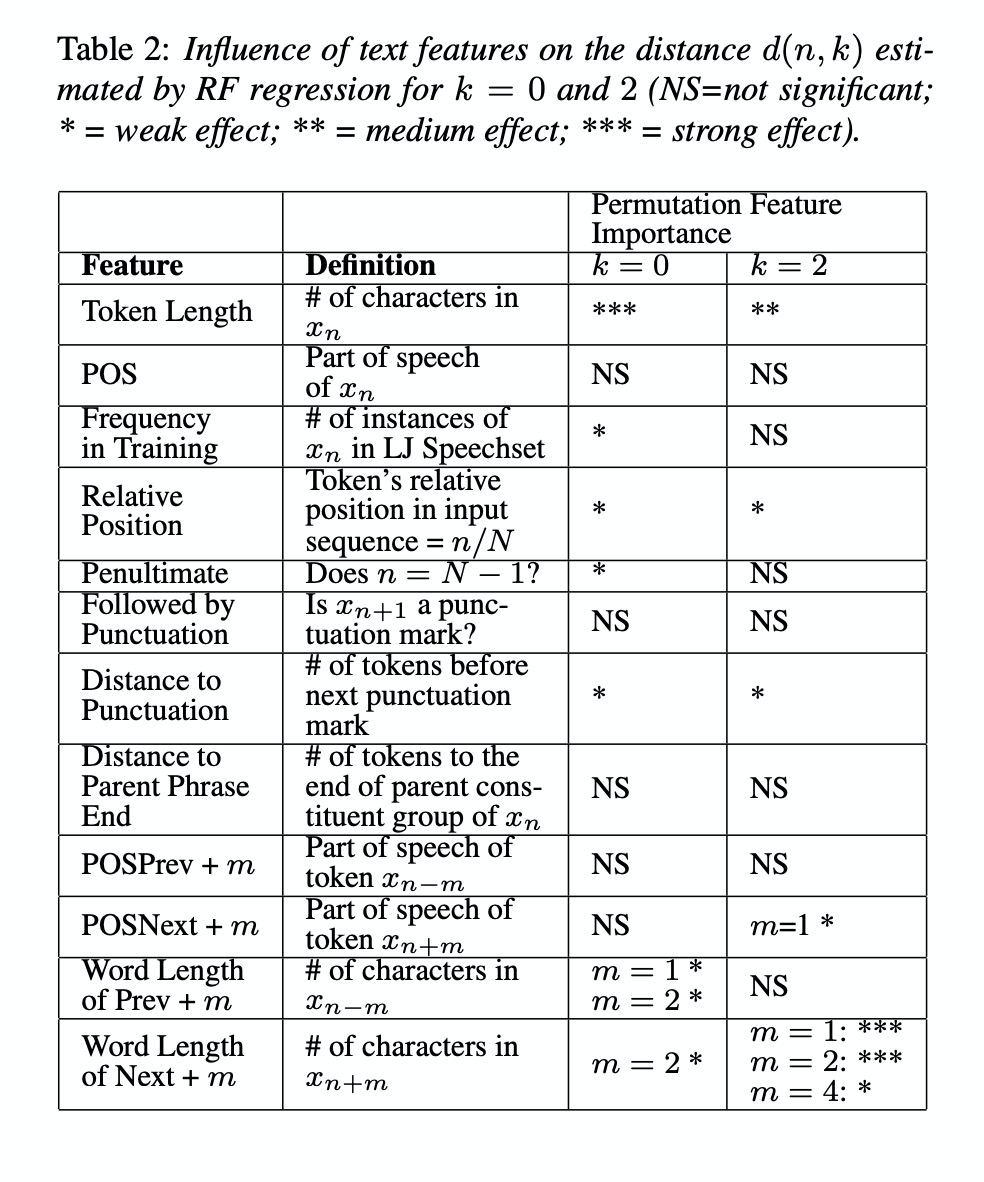
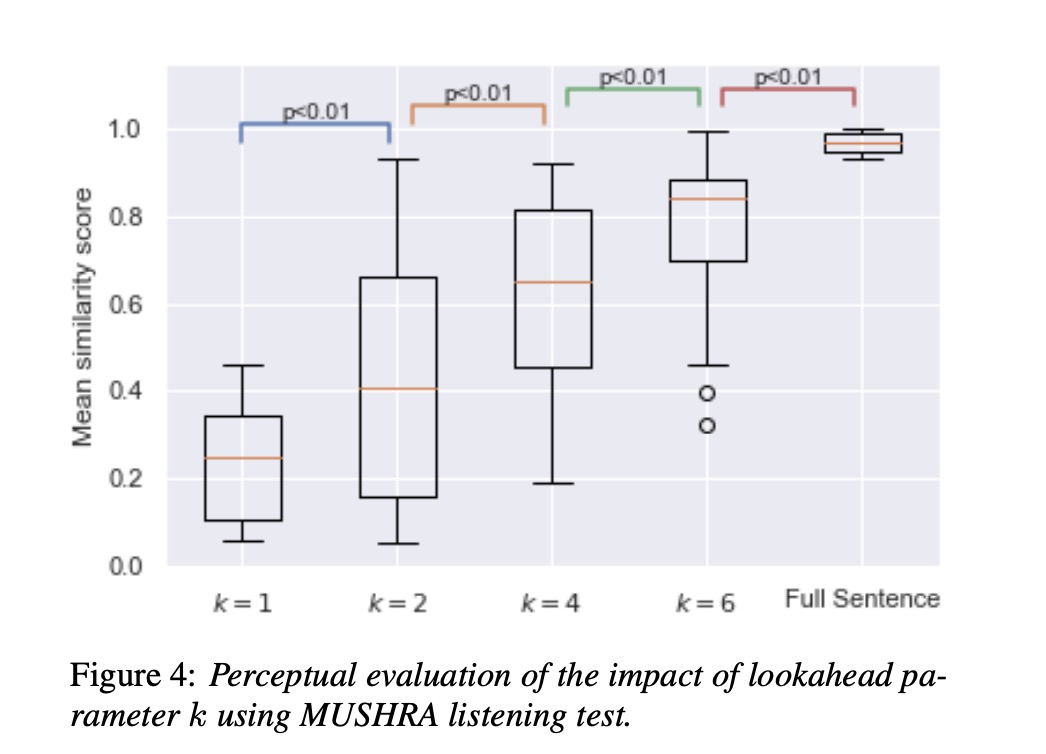
先看一下encoder部分增量k对每个word的影响,其中对比的为原始tacotron系统full,就是处理整个句子。可以看出随着k增大,其结果趋近于原始full的结果。图3的结果亦是如此,其中选择k=2的情况,可以较好的实现iTTS。table2给出了各种参数对iTTS的效果影响。table4显示合成音频的质量受到k的大小影响。
第三篇Alternate Endings: Improving Prosody for Incremental Neural TTS with Predicted Future Text Input
上篇文章主要研究当前word受到future context的影响大小。本文使用语言模型GPT2来预测该语境,来优化iTTS的自然度。详细的设计为图1所示,使用GPT2预测下一个词,然后使用声学模型和声码器合成语音。其中table1展示了集中对比系统,Ground truth为完整句子, Unkonwn k=0,不做任何处理,Ground Truth k=1,完整句子中获取下一个词,GPT2 k=1使用gpt2预测下一个, random是随机预测一下词。

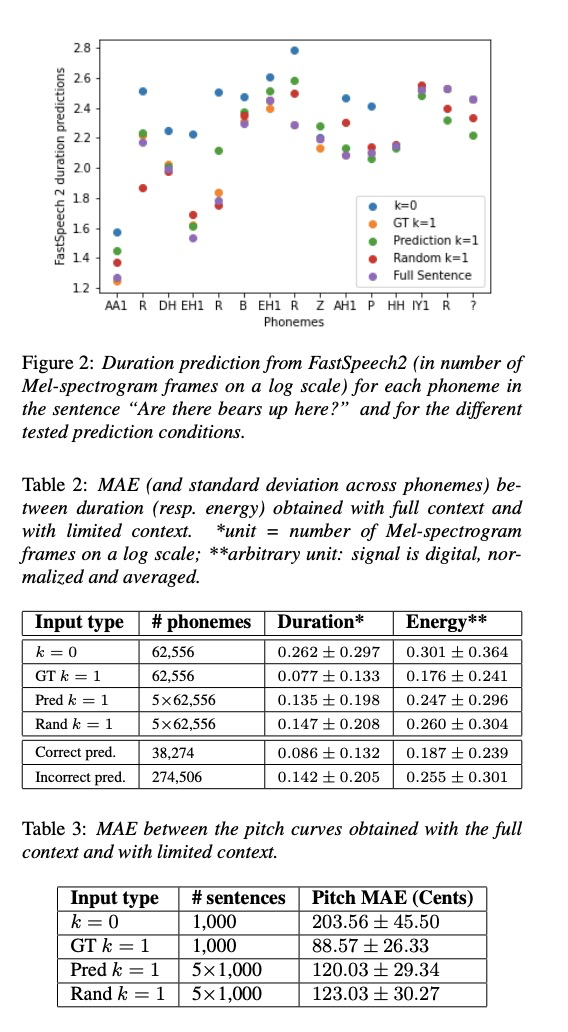
该方案的结果
图2展示了时长预测,可以看出GPT2的结果是弱于全句子和GT k=1,但好于k=0和random。tabel2和table3都展示一致的结果。
第四篇Incremental Text-to-Speech Synthesis Using Pseudo Lookahead with Large Pretrained Language Model
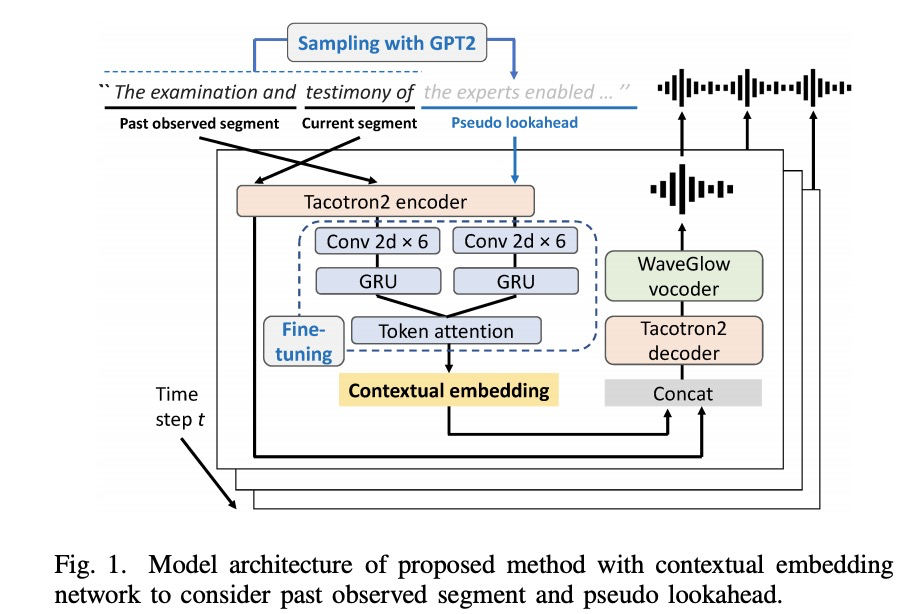
本文相对上一篇主要添加如图1虚线所示添加textual embedding network模块,该模块通过observed segment和预测的future segment来生成context embedding信息。
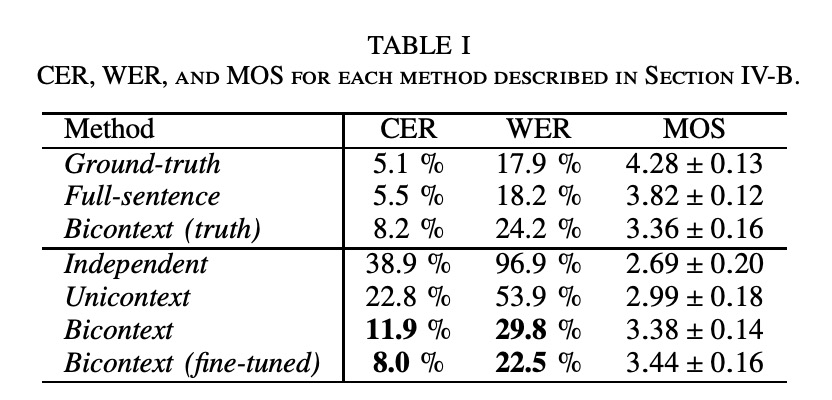
该方案的实验图table 1所示bicontext把MOS和CER,WER提高很多,不断接近full-sentence。
第五篇 Low-Latency Incremental Text-to-Speech Synthesis with Distilled Context Prediction Network
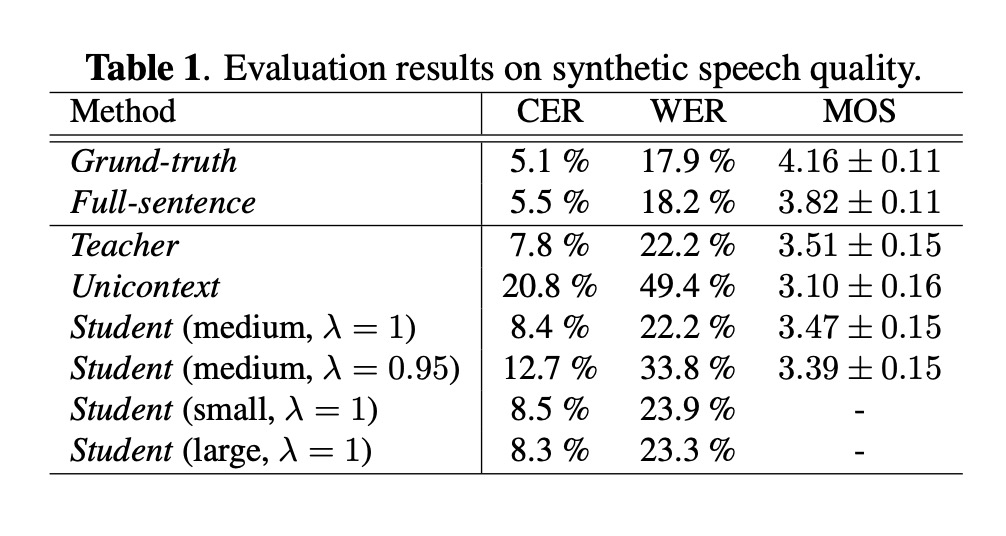
以上几篇文章引入语言模型GPT2会增加时间开销,因此本文在第四篇文章基础上通过知识蒸馏方法对语言模型gpt2和contextual embedding network进行蒸馏,其student只要使用observer segment和current segment就预测contextual embedding,从而提高推理速度。
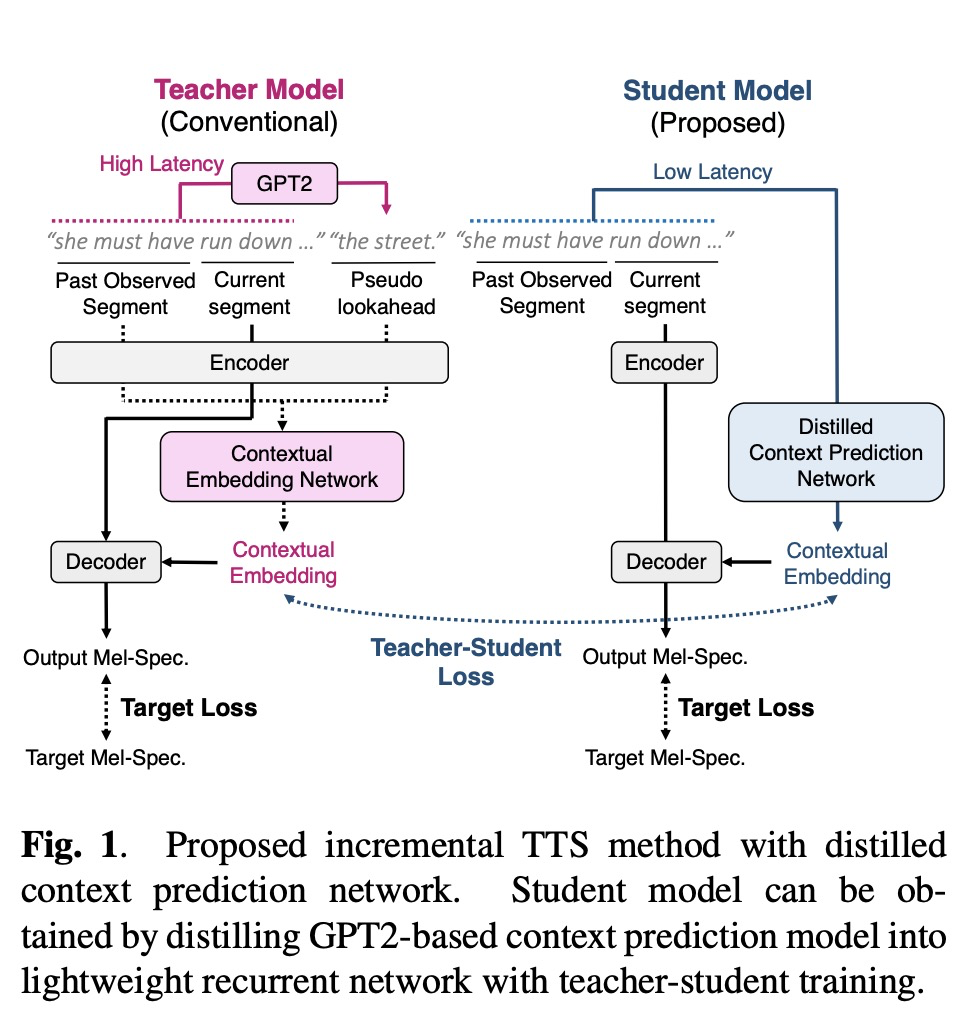
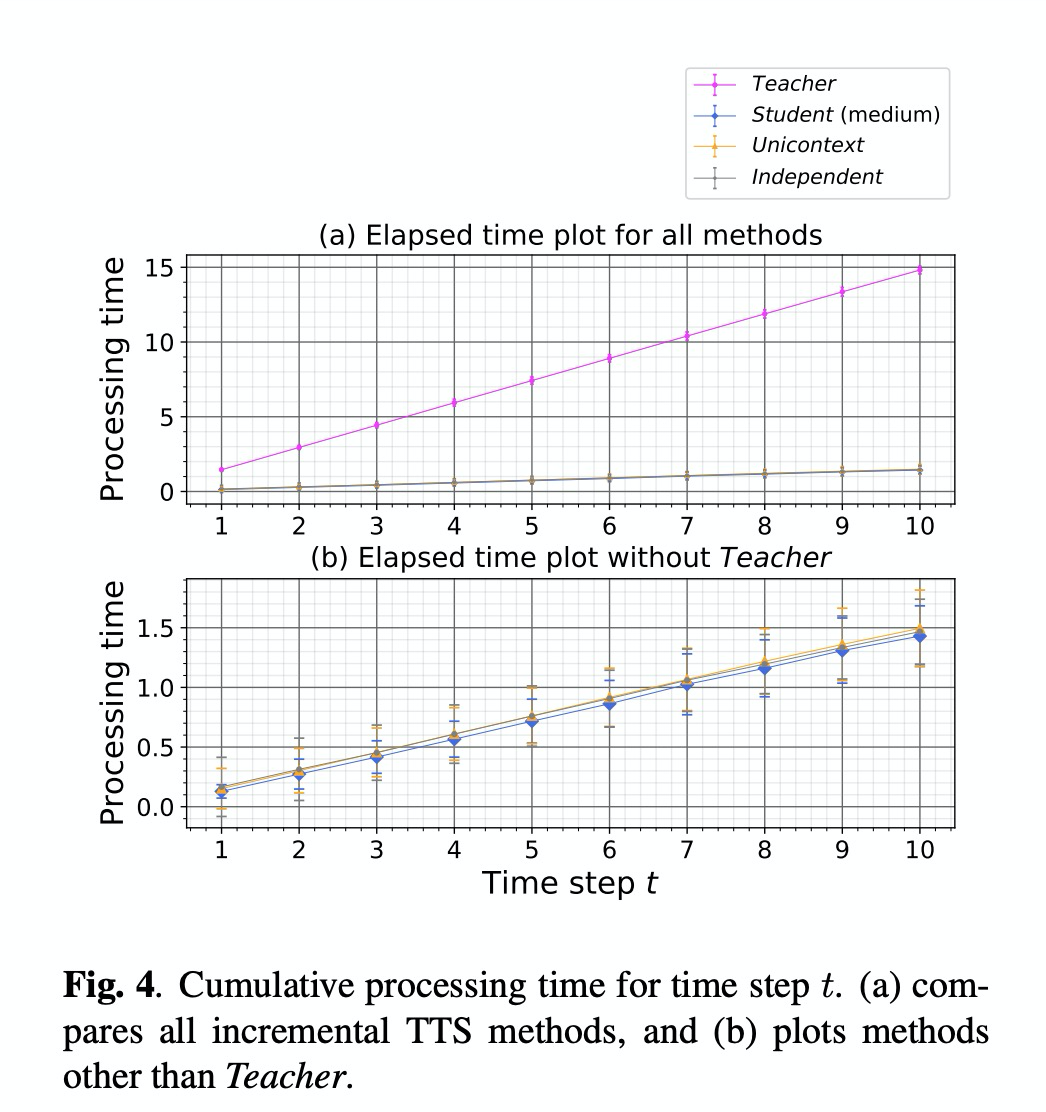
该方案的试验结果如图table 1和图4所示,相比第四篇文章,推理速度提高10倍。
第六篇 High Quality Streaming Speech Synthesis with Low, Sentence-Length-Independent Latency
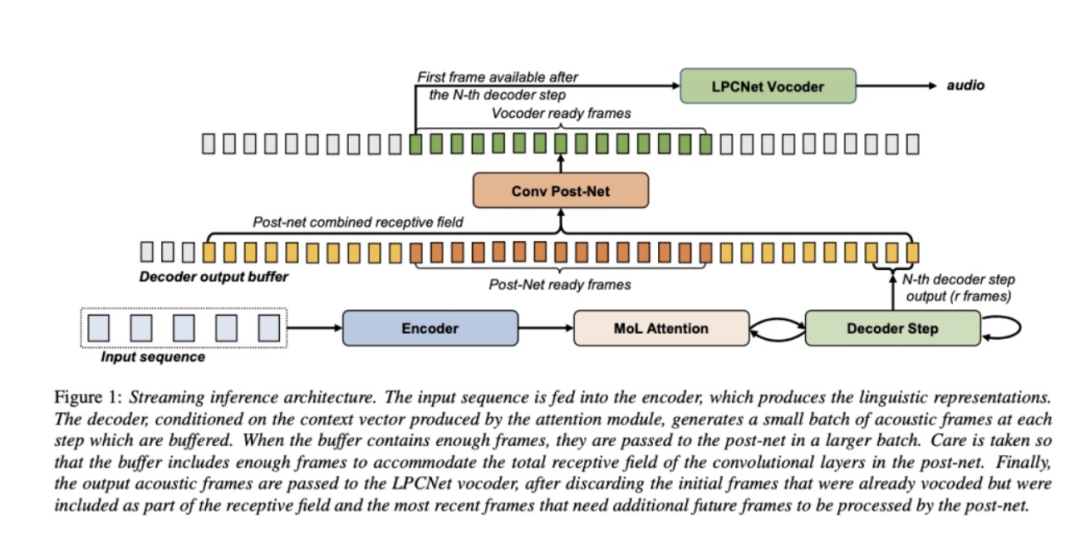
为了减小latency,本文提出了声学模型decoder和声码器streaming的合成系统,无论句子多长,都可以近乎常量时间返回首段音频。本文是在taotron+lpcnet系统上实现,具体的实现为图1所示。在tacotron的decoder的部分添加一个buffer,当buffer满了之后就可以进行post-net网络,(需要注意的是buffer大小要大于post-net的视野长度),同理输出的帧数大于lpcnet的encoder的感受视野就可以进行音频的合成。这样的模式可以使tacotron和lpcnet同时进行合成,而不需要等待tacotron合成整个句子的声学特征后才进行lpcnet的合成
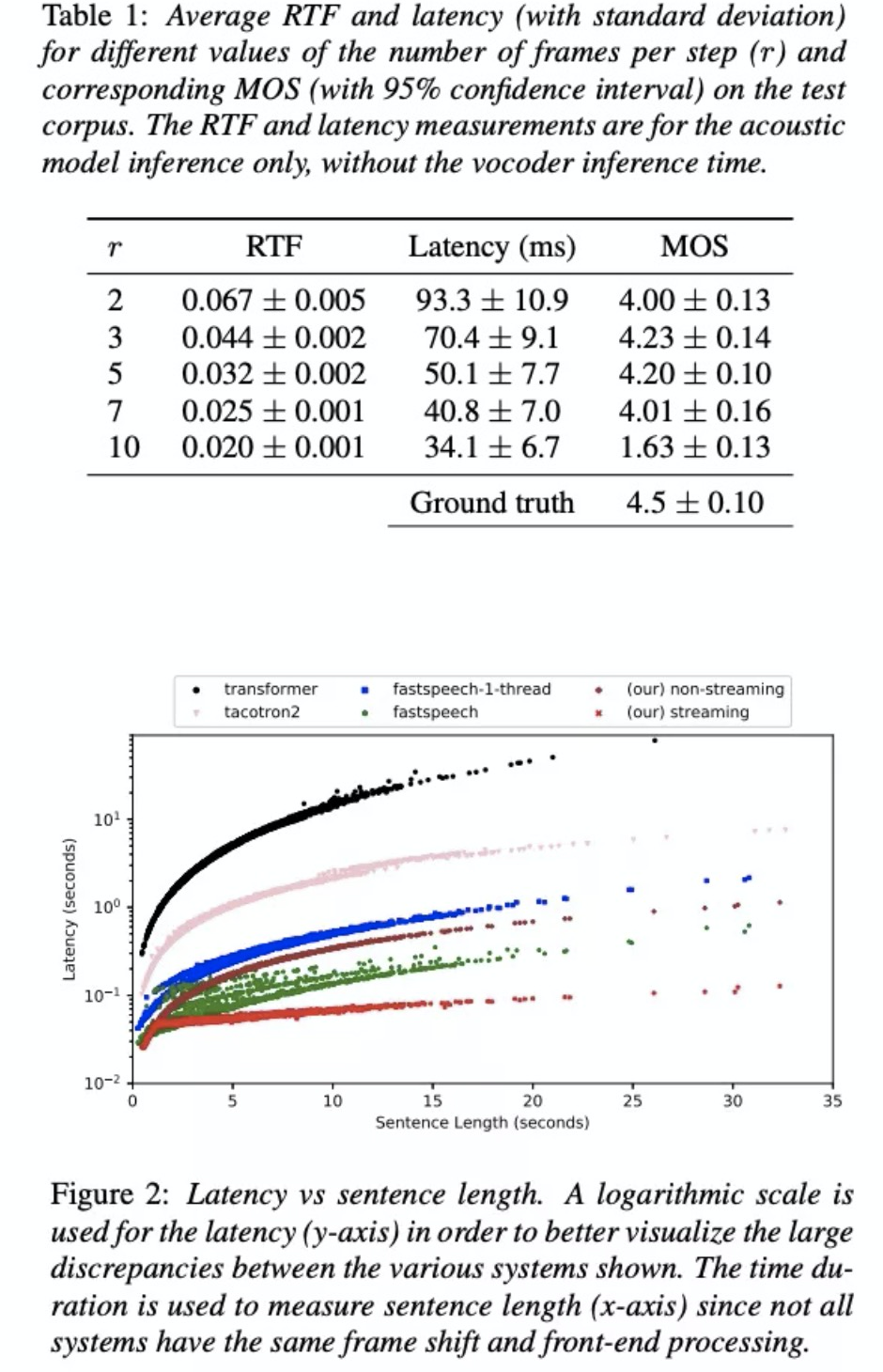
该方案试验结果。首先table1显示r的影响,当r增加可以减少latency,但超过7以后就会急剧下降,这是因为每个step不能涵盖那么多帧的信息,而r=2的效果没有3号,可能因为还没有收敛所致。table2对比了集中常用的语音合成系统,由结果可知,本文的流模式latency几乎最低,逼近常量时间,缓慢上升是由于tacotron的encoder部分随着句子增长而增加,但该部分时间占比很小。















 844
844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











