







零、文章目录
Python进阶07-高级语法
1、with语句
(1)文件操作
- 文件使用完后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的
# 第一步:打开文件
f = open('python.txt', 'w', encoding='utf-8')
# 第二步:写入内容
f.write('人生苦短,我学Python!')
# 第三步:关闭文件
f.close()
(2)文件操作异常
- 由于文件读写时有可能产生IOError,一旦出错,后面的f.close()就不会调用。
# 第一步:打开文件
f = open('python.txt', 'r', encoding='utf-8')
# 第二步:写入内容
f.write('人生苦短,我学Python!') # 出现了异常,not writable,如果此代码出错,会导致下方代码无法执行
# 第三步:关闭文件
f.close()
(3)try…catch…finally解决异常情况
- 这种方法虽然代码运行良好,但是缺点就是代码过于冗长,并且需要添加try-except-finally语句,不是很方便,也容易忘记。,
try:
# 第一步:打开文件
f = open('python.txt', 'r', encoding='utf-8')
# 第二步:写入内容
f.write('人生苦短,我学Python!')
except:
# 第一步:打开文件
f = open('python.txt', 'w', encoding='utf-8')
# 第二步:写入内容
f.write('人生苦短,我学Python!')
finally:
f.close()
(4)with语句优化代码
- Python提供了 with 语句的这种写法,既简单又安全,并且 with 语句执行完成以后自动调用关闭文件操作,即使出现异常也会自动调用关闭文件操作。
'''
with语句:上下文管理器 => with语句通常有两部分操作(上文、下文)
如果是文件操作 => 上文管理器负责打开文件,下文管理器负责关闭文件,而且关闭操作是自动的,即使遇到了异常也会自动关闭
with open('python.txt', 'w') as f:
content = f.read()
print(content)
# 当文件执行结束,with语句会自动关闭刚才产生的f文件对象
'''
with open('python.txt', 'r', encoding='utf-8') as f:
content = f.read()
print(content)
2、yield生成器
(1)生成器是什么
- 根据程序员制定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,可以节约大量的内存。
- 创建生成器的方式:
- ① 生成器推导式
- ② yield 关键字
(2)生成器推导式
- 推导式,用于简化循环代码
'''
推导式:把一个有规律的数据推导为列表结构(有规律),主要作用:用于简化for...in循环代码
'''
list1 = []
for i in range(10):
list1.append(i)
print(list1)
# 把以上代码更改为推导式的形式
list2 = [i for i in range(10)]
print(list2)
- 生成器相关函数:
- next:函数获取生成器中的下一个值
- for:循环遍历生成器中的每一个值
'''
基本语法:
生成器对象 = (推导式代码 => 列表推导式怎么写的,生成器里面的代码也可以同样书写)
举个栗子:创建一个生成器对象,同时保存0-9一共10个元素
注意:虽然生成器的语法和元组推导式感觉很像,但是要特别注意Python中并没有元组推导式,其返回的结果一个generator生成器对象
在生成器中有一个方法,叫做next()方法,其主要功能就是获取生成器中的下一个元素
还有一个特别注意点:生成器中存储的和列表推导式存储的结果有所不同
列表推导式存储的是具体的数据0-9
生成器中存储的并不是具体的数据,而是数据的生成规则,每次next()方法,系统会自动根据生成器的生成规则生成一个元素
这样做的好处就是可以节省大量的空间(真正做到随用随取)
'''
generator = (i for i in range(10)) # (生成元素的规则,第一次打印生成一个0,第二次打印生成一个1)
print(generator) # generator object
# 如何获取生成器中的元素,我们可以基于next()方法调用生成器中的规则,打印元素
result = next(generator)
print(result)
result = next(generator)
print(result)
result = next(generator)
print(result)
# 还可以基于for循环遍历generator生成器对象,获取生成器中的所有数据
for i in generator:
print(i)
(3)为什么使用推导式
- 可以大量节省内存
'''
案例:使用列表推导式方式以及生成器推导式方式创建一组数据,一共有10000000万条数据,从0开始,针对这个列表生成一个新元素
新元素中包含10000000万条数据,每一个值是列表中每个值的平方。
[0, 1, 2, 3] 推导 [0, 1, 4, 9]
通过以下案例分析可知:相对于列表推导式,生成器更加节省内存空间,减少能耗!
为什么会产生以下结果?
答:因为列表推导式,列表中保存的是具体的数据
而生成器对象,其对象中保存的并不是具体的数据,而是1000万条数据的生成规则,随用随取,所以其只需要少量的空间,就可以
达到相同的运行结果
'''
import memory_profiler as mem
list1 = list(range(10000000))
print(f'运算前内存使用情况:{mem.memory_usage()}')
# list2 = [i ** 2 for i in list1]
generator = (i ** 2 for i in list1)
print(f'运算后内存使用情况:{mem.memory_usage()}')
print(next(generator))
(4)yield生成器
- 除了可以使用(推导式)方式来创建生成器对象以外,我们还可以通过函数 + yield方式来创建生成器
'''
在Python中,除了可以使用(推导式)方式来创建生成器对象以外,我们还可以通过函数 + yield方式来创建一个生成器。
这种创建方式是Python3中比较推荐的一种使用方式。
基本语法:
def 函数名称():
...
yield 值
...
'''
def generator(n):
for i in range(n):
print('开始生成数据')
yield i # 暂时可以把yield关键字理解为return,相当于返回数据的含义 => return 0
print('数据生成完成')
result = generator(5)
print(result)
print(next(result))
# 以上next(result),先执行了print('开始生成数据'),然后通过yield关键字返回了第一个数据0,然后函数中止执行,但是要特别注意,这里只是暂停在yield i这个位置,当我们下一次执行生成器的时候,程序会在此结束位置开始继续执行
print('-' * 40)
print(next(result))
print('-' * 40)
print(next(result))
(5)yield生成器实现斐波那契数列
- 数学中有个著名的斐波拉契数列(Fibonacci)要求:数列中第一个数为1,第二个数为1,其后的每一个数都可由前两个数相加得到:例子:1, 1, 2, 3, 5, 8, 13, 21, 34, …
- 现在我们使用生成器来实现这个斐波那契数列,每次取值都通过算法来生成下一个数据,生成器每次调用只生成一个数据,可以节省大量的内存。
'''
斐波那契数列:数学中的一个概念,是一组有规律的数字!
1 1 2 3 5 8 13 21 34 55 ...
规律:
隐藏了一个元素 => 0
第1个元素为1
第2个元素为1,第2个元素为1,实际上是由0 + 1 = 隐藏元素 + 第一个元素
第3个元素为2 = 1 + 1,第3个元素值 = 第2个元素值 + 第1个元素值
第4个元素为3 = 2 + 1,第4个元素值 = 第3个元素值 + 第2个元素值
刚好满足:数据量比较大,而且还要经过大量的计算 => 符合生成器的使用规则
0 1 1 2 3 5 8 13 21 34 55 ...
a变量代表,斐波那契数列中前一个元素,比如a可以代表0
b变量代表,斐波那契数列中后一个元素,比如b可以代表1
a,b是相邻的两个元素
'''
def fib(max): # 求max位斐波那契数列 => 前max位斐波那契数列的每个值
n, a, b = 0, 0, 1
while n < max:
yield b # 第一次循环,弹出一个1
# 想个办法,让第二次yield b,弹出一个1,第三次yield b,弹出一个2
# a = 0, b = 1
a, b = b, a + b
# a = 1, b = 1
n += 1
result = fib(50)
for i in result:
print(i)
3、深浅拷贝
(1)可变类型/不可变类型
- 不可变对象:一旦创建就不可修改的对象,包括字符串、元组、数值类型(整型、浮点型)
- 该对象所指向的内存中的值不能被改变。当改变某个变量时候,由于其所指的值不能被改变,相当于把原来的值复制一份后再改变,这会开辟一个新的地址,变量再指向这个新的地址。
- 可变对象:可以修改的对象,包括列表、字典、集合
- 该对象所指向的内存中的值可以被改变。变量(准确的说是引用)改变后,实际上是其所指的值直接发生改变,并没有发生复制行为,也没有开辟新的地址,通俗点说就是原地改变。
(2)变量赋值原理
- a = “python”:Python解释器干的事情
- ① 创建变量a
- ② 创建一个对象(分配一块内存),来存储值 ‘python’
- ③ 将变量与对象,通过指针连接起来,从变量到对象的连接称之为引用(变量引用对象)

(3)浅拷贝
- 浅拷贝: 创建新对象,其内容是原对象的引用。
- 浅拷贝之所以称为浅拷贝,是它仅仅只拷贝了一层,拷贝了最外围的对象本身,内部的元素都只是拷贝了一个引用而已
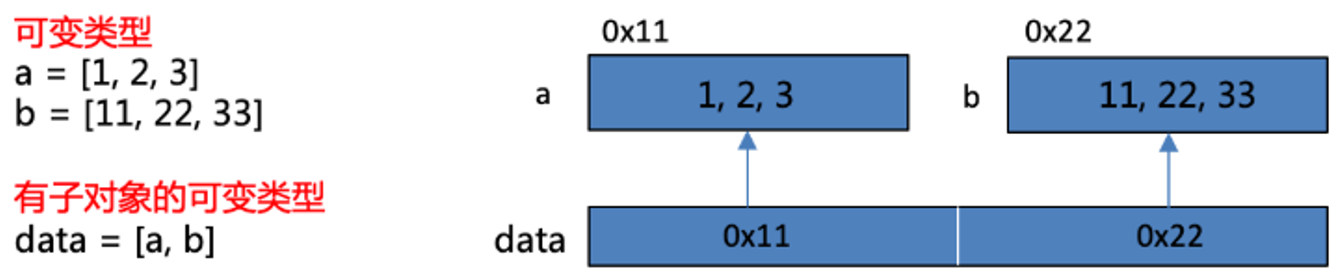
(4)浅拷贝-可变类型

(5)浅拷贝-不可变类型
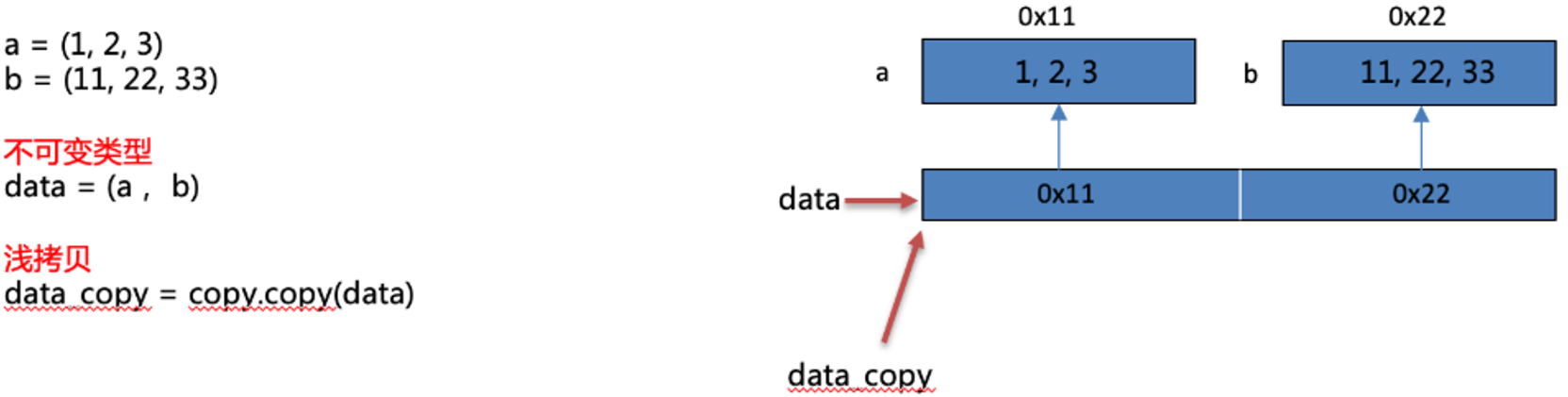
(6)浅拷贝总结
- 当浅复制的值是不可变对象(字符串、元组、数值类型)时和“赋值”的情况一样,对象的id值(id()函数用于获取对象的内存地址)与浅复制原来的值相同。
- 当浅复制的值是可变对象(列表、字典、集合)时会产生一个“不是那么独立的对象”存在。
- 第一种情况:复制的对象中无复杂子对象,原来值的改变并不会影响浅复制的值,同时浅复制的值改变也并不会影响原来的值。原来值的id值与浅复制原来的值不同。
- 第二种情况:复制的对象中有复杂子对象(例如列表中的一个子元素是一个列表),如果不改变其中复杂子对象,浅复制的值改变并不会影响原来的值。 但是改变原来的值中的复杂子对象的值会影响浅复制的值。
(7)深拷贝
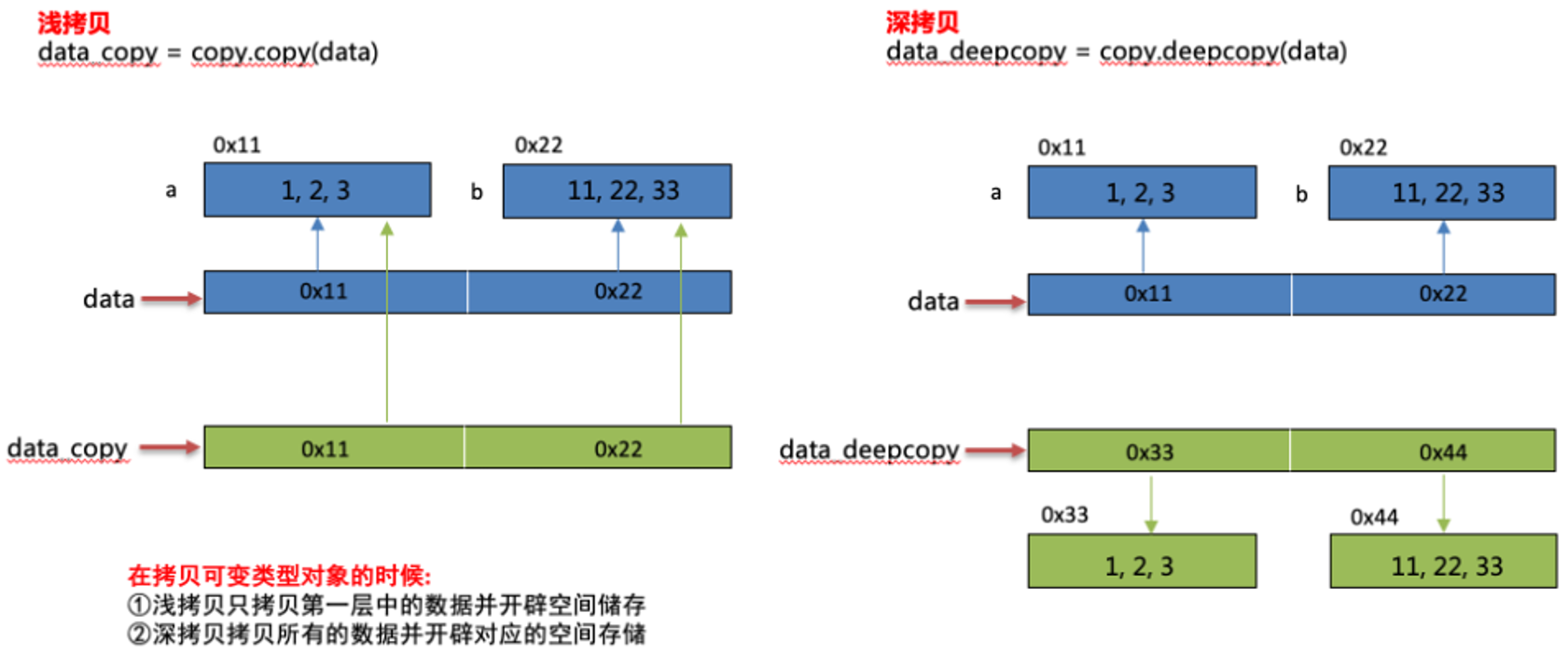
- 深拷贝:和浅拷贝对应,深拷贝拷贝了对象的所有元素,包括多层嵌套的元素。深拷贝出来的对象是一个全新的对象,不再与原来的对象有任何关联。所以改变原有被复制对象不会对已经复制出来的新对象产生影响。只有一种形式,copy模块中的deepcopy函数。
(8)深拷贝-可变类型
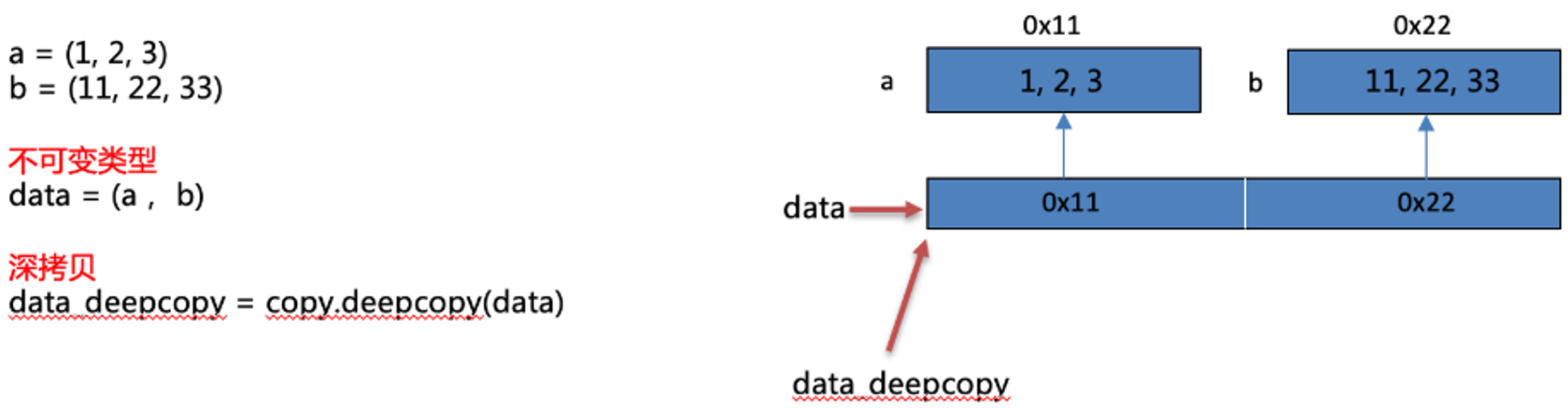
(9)深拷贝-不可变类型
- 不可变类型深拷贝:不可变类型进行深拷贝不会给拷贝的对象开辟新的内存空间,而只是拷贝了这个对象的引用。
4、正则表达式
(1)正则表达式有什么用
- 在实际开发过程中经常会有查找符合某些复杂规则的字符串的需要比如:邮箱、图片地址、手机号码等这时候想匹配或者查找符合某些规则的字符串就可以使用正则表达式了。
(2)正则表达式是什么
- 正则表达式(regular expression):描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串、将匹配的子串做替换或者从某个串中取出符合某个条件的子串等。
- 模式:一种特定的字符串模式,这个模式是通过一些特殊的符号组成的。
- 某种:也可以理解为是一种模糊匹配。
- 精准匹配:select * from blog where title=‘python’;
- 模糊匹配:select * from blog where title like ‘%python%’;
- 正则表达式并不是Python所特有的,在Java、PHP、Go以及JavaScript等语言中都是支持正则表达式的。
(3)正则表达式的功能
- ① 数据验证(表单验证、如手机、邮箱、IP地址)
- ② 数据检索(数据检索、数据抓取) => 爬虫功能
- ③ 数据隐藏(135****6235 王先生)
- ④ 数据过滤(论坛敏感关键词过滤)
- …
(4)re模块的介绍
- 在Python中需要通过正则表达式对字符串进行匹配的时候,可以使用一个re模块
- re模块使用三步走
- 导入re模块:import re
- 使用match方法进行匹配操作:result = re.match(pattern正则表达式, string要匹配的字符串, flags=0)
- 如果数据匹配成功,使用group方法来提取数据:result.group()
# 1、使用正则表达式匹配数字8
import re
str1 = '13567006604'
result = re.findall('8', str1)
if result:
print(result)
else:
print('暂未匹配到任何数据!')
# 2、查找一个字符串中是否具有数字(0-9)
str2 = 'abcdef9ghij6kl1mn'
result = re.findall('[0-9]', str2)
print(result)
# 3、查找一个字符串中是否具有非数字
str3 = '12345a67b89c0'
result = re.findall('[^0-9]', str3)
print(result)
- 正则表达式中的相关方法
- ① re.match():匹配以正则开头的字符串信息,返回一个re对象,group()打印结果
- ② re.search():在字符串中匹配正则表达式中的内容,没有位置限制,但是默认只能匹配第一个匹配到的结果
- ③ re.findall():匹配字符串中所有满足正则表达式的结果,返回是一个列表类型数据
- ④ re.finditer():匹配正则表达式中所有内容,包括分组内容,但是其返回结果是一个可迭代对象,必须使用for循环遍历,然后通过group()才能获取结果
- ⑤ re.split():按照正则表达式匹配到的内容对字符串进行切割操作
(5)匹配单个字符
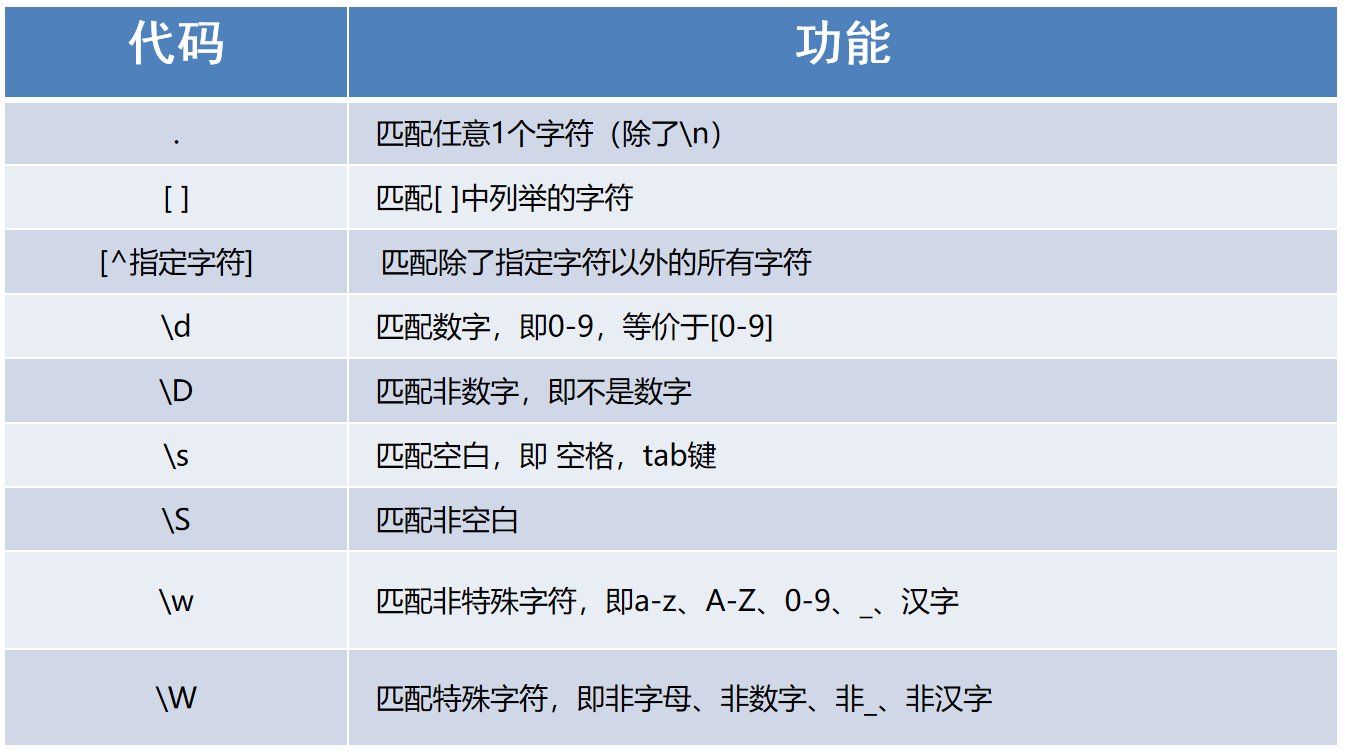
'''
正则表达式 => ① 查什么 ② 查多少 ③ 从哪查
import re模块
要用到的知识点:match() => re.match('正则表达式', 字符串)
match只能匹配出以正则开头的内容,使用match匹配某个字符
'''
import re
# 1、匹配字符串中的第一个数字字符
str1 = '6abcdefg'
result = re.match('\d', str1)
if result:
print(result.group())
# 2、匹配任意某1个字符
str2 = '@abcd123'
result = re.match('.', str2)
if result:
print(result.group())
# 3、匹配aeiou字符中的任意某个字符
str3 = 'abcdefg'
result = re.match('[aeiou]', str3)
if result:
print(result.group())
# 4、匹配空白字符\s字符串
str4 = ' admin'
result = re.match('\s', str4)
if result:
print(len(result.group()))
# 5、字符簇取反[0-9] => [^0-9]匹配0-9以外的其他某1个字符
str5 = 'z12345'
result = re.match('[^0-9]', str5)
if result:
print(result.group())
# 6、匹配26个字符中的任意某个字符
str6 = 'Abc123'
result = re.match('[a-zA-Z]', str6)
if result:
print(result.group())
# 7、匹配0-9或a-z或A-Z或_中的任意某1个字符
str7 = '_bc123'
result = re.match('\w', str7)
if result:
print(result.group())
(6)匹配多个字符
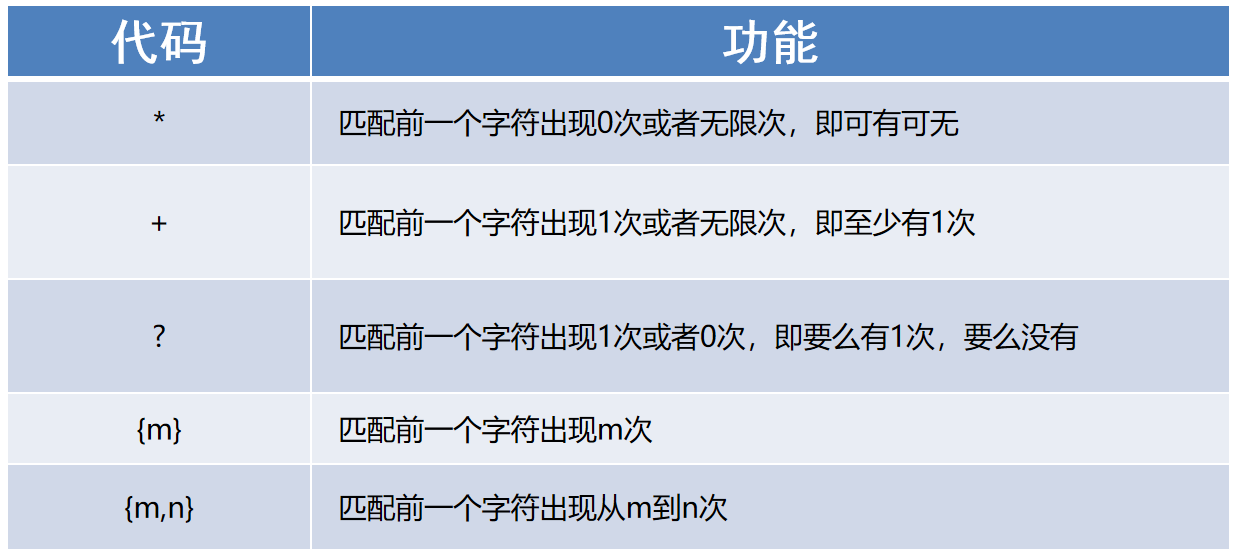
'''
正则三步走之查多少,到底要匹配多少个字符
普通字符或元字符* : 0或多,匹配前面的字符出现0次或多次,实际工作中,经常和.号配合使用,代表匹配任意字符.*
普通字符或元字符+ : 1或多,匹配前面的字符出现1次或多次,至少要出现1次,至多出现N次
普通字符或元字符? : 0或1,匹配前面的字符出现0次或1次
普通字符或元字符{m} : 匹配前面的字符出现m次
普通字符或元字符{m,} : 匹配前面的字符至少出现m次
普通字符或元字符{m,n} : 匹配前面的字符至少出现m次,至多出现n次
注意:限定符,默认只能限定前面的第一个字符,比如10?,只能限定0不能限定1
101? 前面必须是10,1可以出现也可以不出现 => 首先匹配101,如果101匹配不到,则匹配10
'''
import re
# 1、匹配连续的3位纯数字
str1 = '666abcd'
result = re.match('\d{3}', str1)
if result:
print(result.group())
# 2、匹配1或10开头的字符
str2 = '1abcabc'
result = re.match('10?', str2)
if result:
print(result.group())
# 3、匹配所有字符
str3 = '<img src="avatar.jpg">'
result = re.match('.*', str3)
if result:
print(result.group())
# 4、至少匹配连续4位字符(a-z)
str4 = 'abcdefg123'
result = re.match('[a-z]{4,}', str4)
if result:
print(result.group())
(7)匹配字符串开头或者结尾

'''
^ :托字节,^代表匹配以某个字符开头
$ :dollar美元符号,$代表匹配以某个字符结尾
注意:如果^托字节出现在[]字符簇中,则代表取反。如果单独出现,代表匹配以某个字符开头
案例:使用正则表达式匹配国内手机号码
手机号码 => 11位 => \d{11},不能这么写,因为手机号码要满足一定的规则
第1位必须是1
第2位必须是13、14、15、16、17、18、19,第2位必须是3或4或5或6或7或8或9
第3位开始~第11位,什么样的数字都有
手机验证:
1[3-9]\d{9}
'''
import re
mobile = input('请输入您的手机号码:')
result = re.match('^1[3-9]\d{9}$', mobile)
if result:
print('合法的手机号码,发送短信验证码')
else:
print('您输入的手机号码有误,请重新输入')
(8)提取分组数据
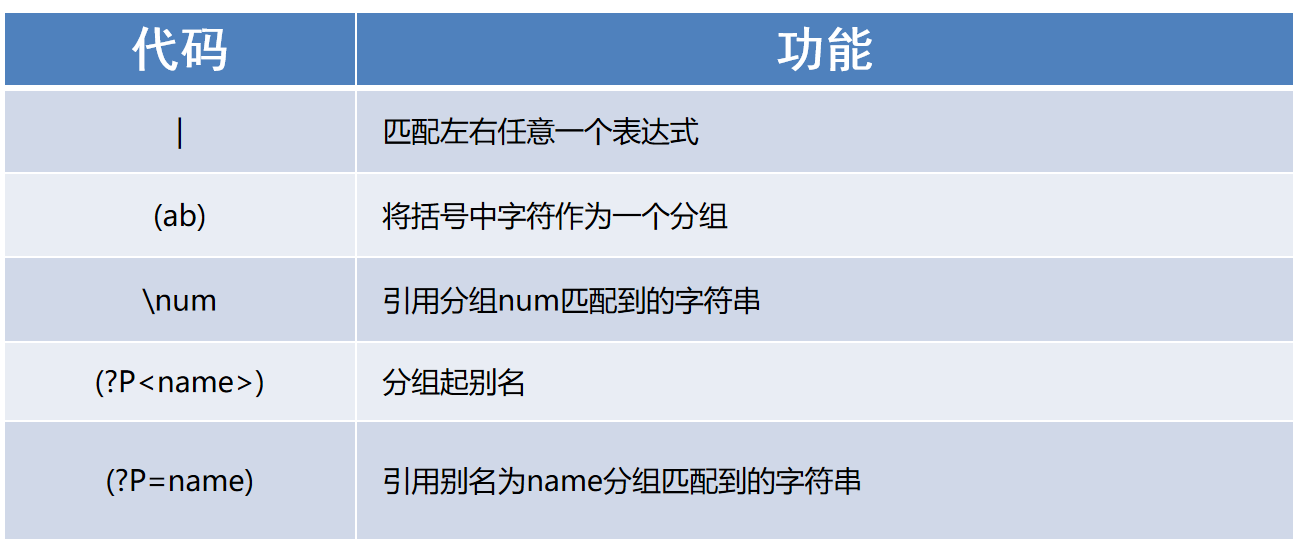
-
引入r:把正则中的转义字符当做普通字符使用
-
选择匹配符
-
|可以匹配多个规则 -
# 选择匹配符 result = re.finditer(r'hello(java|python)', 'hellojava, hellopython') if result: for i in result: print(i.group()) else: print('未匹配到任何数据')
-
-
子表达式:又叫分组,表达式中小括号括起来的部分就是子表达式
-
正则表达式中\d(\d)(\d)中,(\d)(\d)就是子表达式,一共有两个
()圆括号,则代表两个子表达式 -
re.search(r'\d(\d)(\d)', 'abcdef123ghijklmn')
-
-
捕获:当正则表达式在字符串中匹配到相应的内容后,计算机系统会自动把子表达式所匹配的到内容放入到系统的对应缓存区中
-
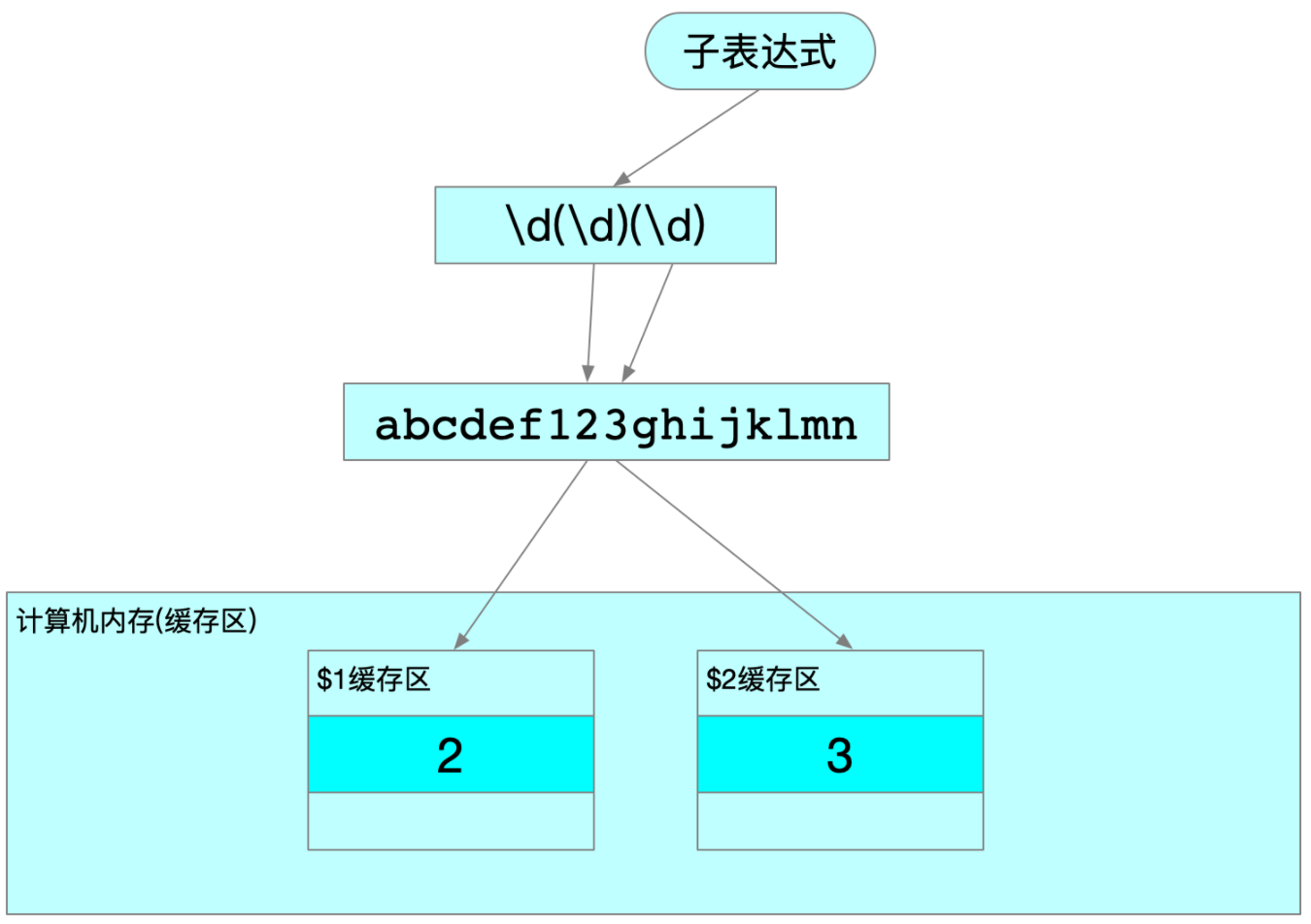
-
result = re.search(r'\d(\d)(\d)', 'abcdef123ghijklmn') print(result.group()) #123 print(result.group(1)) #2 print(result.group(2)) #3
-
-
反向引用(后向引用)
-
在正则表达式中,我们可以通过\num(num代表第num个缓存区的编号)来引用缓存区中的内容,我们把这个过程就称之为"反向引用"。
-
# 四个数字 result =re.search(r'\d\d\d\d', 'abcdef1234ghijklmn7894') print(result.group()) # 1234 # 四个数字叠字 1111 2222 3333 4444 result =re.search(r'(\d)\1\1\1', 'abcdef1234ghijklmn33aaaa4444sese') print(result.group()) #4444
-
-
分组别名
-
result = re.search(r'<(?P<mark>\w+)></(?P=mark)>', '<book></book>') print(result.group()) #'<book></book>'
-
















 1755
1755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











