







转载https://blog.csdn.net/weixin_44388679/article/details/106564349
重点参考
https://www.sohu.com/a/340384890_120053730
https://www.sohu.com/a/198655698_465975
一、什么是Horovod
Horovod是基于Ring-AllReduce方法的深度分布式学习插件,以支持多种流行架构包括TensorFlow、Keras、PyTorch等。这样平台开发者只需要为Horovod进行配置,而不是对每个架构有不同的配置方法。
Ring-AllReduce方法是把每个计算单元构建成一个环,要做梯度平均的时候每个计算单元先把自己梯度切分成N块,然后发送到相邻下一个模块。现在有N个节点,那么N-1次发送后就能实现所有节点掌握所有其他节点的数据。这个方法被证明是一个带宽最优算法。
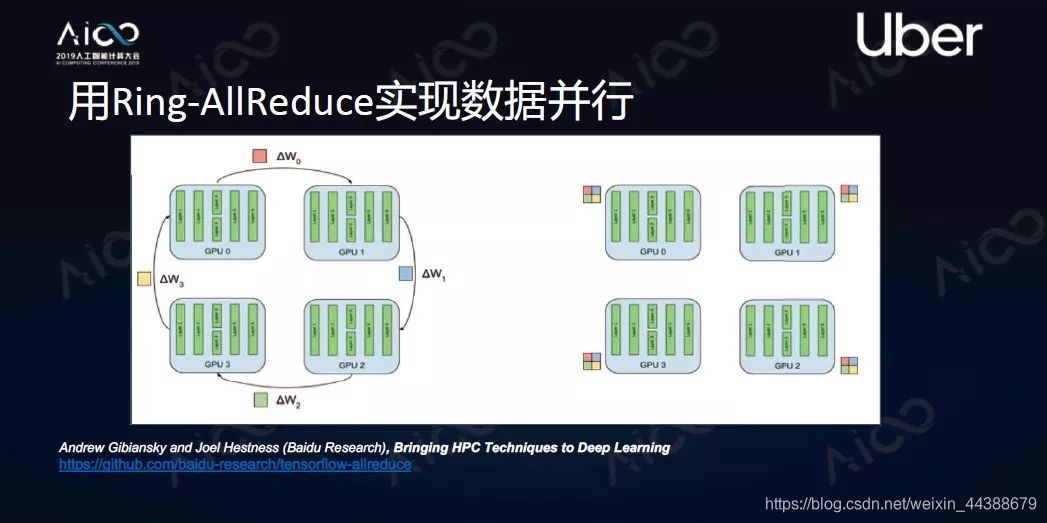
二、什么是分布式
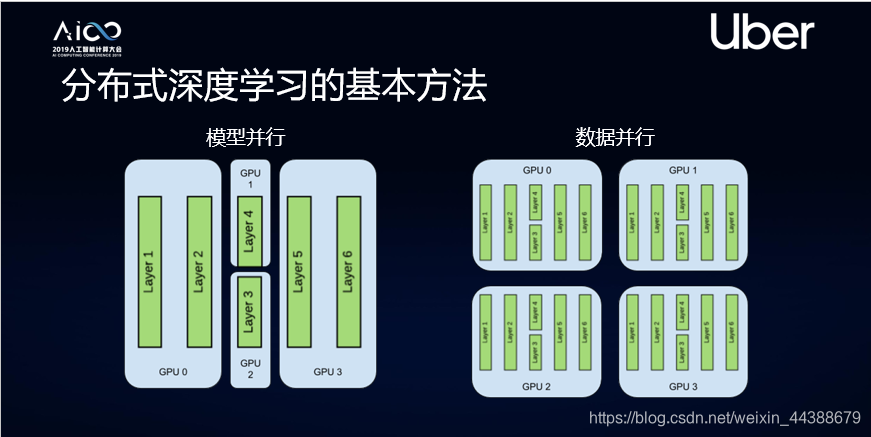
1、模型并行
即把复杂的神经网络拆分,分布在计算单元或者GPU里面进行学习,让每个GPU同步进行计算。这个方法通常用在模型比较复杂的情况下。
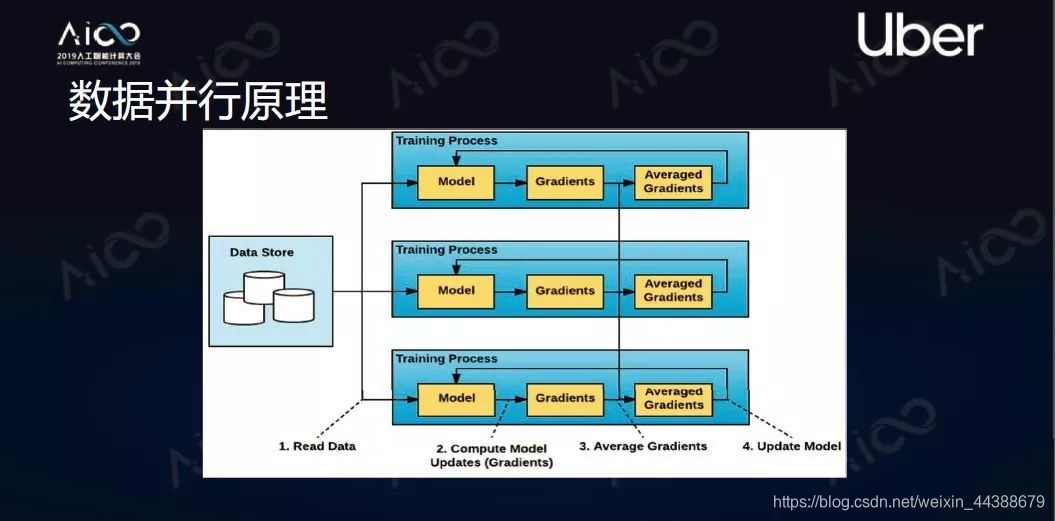
2、数据并行
即让每个机器里都有一个完整模型,然后把数据切分成n块,把n块分发给每个计算单元,每个计算单元独自计算出自己的梯度。同时每个计算单元的梯度会进行平均、同步,同步后的梯度可以在每个节点独立去让它修正模型,整个过程结束后每个节点会得到同样的模型。这个方法可以让能够处理的数据量增加,变成了原来的n倍。
三、TensorFlow、Keras、PyTorch代码怎么使用Horovod
1、keras实例
单机Keras训练
from tensorflow import keras
import tensoflow.keras.backend as K
import tensorflow as tf
model = ...
x_train, y_train, x_test, y_test = ...
opt = keras.optimizers.Adadelta(lr=1.0)
model.complie(
loss = ‘categprical_crossentropy’,
optimizer=opt,
metrics=[‘accuracy’])
Horovod+Keras分布式训练
from tensorflow import keras
import tensoflow.keras.backend as K
import tensorflow as tf
import horovod.tensorflow.keras as hvd
#Initialize Horovod
hvd.init()
#Pin GPU to be used
config = tf.ConfigProton()
config.gpu_options.visible_device_list=str(hvd.local_rank)
K.set_session(tf.Session(config=config))
model = ...
x_train, y_train, x_test, y_test = ...
#change lr
opt = keras.optimizers.Adadelta(lr=1.0 * hvd.size())
#Add Horovod Distribute Optimizer
opt = hvd.DistributedOptimizer(opt)
model.complie(
loss = ‘categprical_crossentropy’,
optimizer=opt,
metrics=[‘accuracy’])
#Broadcast initial variable state
callbacks = [hvd.callbacks.BroadcastGlobalVaribaleCallback(0)]
model.fit(
x_train,
y_train,
batch_size=32,
callbacks=callbacks,
epochs=(10 // hvd.size()),
validation_data(x_test, y_test))
总结一下,把单个计算单元训练变成多机分布式训练用Horovod是非常简单的,只需要做三步。第一步程序引入Horovod稍微做修改,调整学习率、时间;第二步处理训练的数据,进行分布化;第三步用Horovodrun程序进行启动,就可以进行分布式训练了。
2、pytorch实例
import horovod.torch as hvd
hvd.init()
if args.cuda:
# Horovod: pin GPU to local rank.
torch.cuda.set_device(hvd.local_rank())
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset, num_replicas=hvd.size(), rank=hvd.rank())
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.batch_size, sampler=train_sampler, **kwargs)
# Horovod: scale learning rate by the number of GPUs.
optimizer = optim.SGD(model.parameters(), lr=args.base_lr * hvd.size(),
momentum=args.momentum, weight_decay=args.wd)
# Horovod: wrap optimizer with DistributedOptimizer.
optimizer = hvd.DistributedOptimizer(
optimizer, named_parameters=model.named_parameters())
# Horovod: broadcast parameters & optimizer state.
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
hvd.broadcast_optimizer_state(optimizer, root_rank=0)
3、tensorflow 实例
import tensorflow as tf
import horovod.tensorflow as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf.ConfigProto()
config.gpu_options.visible_device_list = str(hvd.local_rank())
# Build model...
loss = ...
opt = tf.train.AdagradOptimizer(0.01 * hvd.size())
# Add Horovod Distributed Optimizer
opt = hvd.DistributedOptimizer(opt)
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
# Make training operation
train_op = opt.minimize(loss)
# Save checkpoints only on worker 0 to prevent other workers from corrupting them.
checkpoint_dir = '/tmp/train_logs' if hvd.rank() == 0 else None
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf.train.MonitoredTrainingSession(checkpoint_dir=checkpoint_dir,
config=config,
hooks=hooks) as mon_sess:
while not mon_sess.should_stop():
# Perform synchronous training.
mon_sess.run(train_op)
1)初始化 Horovod
hvd.init()
2)一个 GPU 与一个进程绑定
config = tf.ConfigProto()
config.gpu_options.visible_device_list = str(hvd.local_rank())
3)根据总 GPU 数量放大学习率
opt = tf.train.AdagradOptimizer(0.01 * hvd.size())
因为 BatchSize 会根据 GPU 数量放大,所以学习率也应该放大。
4)使用 hvd.DistributedOptimizer 封装原有的 optimizer
opt = hvd.DistributedOptimizer(opt)
分布式训练涉及到梯度同步,每一个 GPU 的梯度计算仍然由原有的 optimizer 计算,只是梯度同步由 hvd.DistributedOptimizer 负责。
5)广播初始变量值到所有进程
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
主要为了确保所有进程变量初始值相同。
6)只在 worker 0 上保存 checkpoint
checkpoint_dir = ‘/tmp/train_logs’ if hvd.rank() == 0 else None
防止 checkpoint 保存错乱。
Horovod 只是需要改动必要改动的,不涉及 Parameter Server 架构的 device 设置等繁琐的操作。
四、运行
在单机 4 卡的机上起训练,只需执行以下命令:
horovodrun -np 4 -H localhost:4 python train.py
在 4 机,每机 4 卡的机子上起训练,只需在一个机子上执行以下命令即可:
horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py
注意无论是单机多卡,还是多机多卡,都只需在一个机子上执行一次命令即可,其他机 Horovod 会用 MPI 启动进程和传递数据。
更多实例可以参考https://github.com/horovod/horovod/tree/master/examples
参考文献:
1、是时候放弃TensorFlow集群,拥抱Horovod了
2、你“听”得懂的干货,Horovod如何实现大规模分布式深度学习
3、Horovod, 分布式进阶














 3445
3445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









