






1、数据结构
数据结构( Data Structure) 是数据的组织方式。程序中用到的数据都不是孤立的,而是有相互联系的,根据访问数据的需求不同,同样的数据可以有多种不同的组织方式。
以前学过的复合类型也可以看作数据的组织方式,把同一类型的数据组织成数组,或者把描述同一对象的各成员组织成结构体。数据的组织方式包含了存储方式和访问方式这两层意思,二者是紧密联系的。
例如,数组的各元素是一个挨一个存储的,并且每个元素的大小相同,因此数组可以提供按下标访问的方式,结构体的各成员也是一个挨一个存储的,但是每个成员的大小不同,所以只能用.运算符加成员名来访问,而不能按下标访问。
2、堆栈
堆栈是一组元素的集合,类似于数组,不同之处在于,数组可以按下标随机访问,这次访问a[5]下次可以访问a[1],但是堆栈的访问规则被限制为Push和Pop两种操作, Push(入栈或压栈) 向栈顶添加元素, Pop(出栈或弹出) 则取出当前栈顶的元素,也就是说,只能访问栈顶元素而不能访问栈中其它元素。
如果所有元素的类型相同,堆栈的存储也可以用数组来实现,访问操作可以通过函数接口提供。看以下的示例程序。
#include <stdio.h>
char stack[512];
int top = 0;
void push(char c){
stack[top] = c;
top++;
}
char pop(void){
top--;
return stack[top];
}
int is_empty(void){
return top == 0;
}
int main(void){
push('a');
push('b');
push('c');
while(!is_empty()){
putchar(pop());
}
putchar('\n');
return 0;
}putchar函数的作用是把一个字符打印到屏幕上,和printf的%c作用相同。布尔函数is_empty的作用是防止Pop操作访问越界。这里我们把栈的空间取得足够大,其实严格来说Push操作也应该检查是否越过上界。
Pop操作的语义是取出栈顶元素,但上例的实现其实并没有清除原来的栈顶元素,只是把top指针移动了一下,原来的栈顶元素仍然存在那里。这就足够了,因为此后通过Push和Pop操作不可能再访问到已经取出的元素了,下次Push操作就会覆盖它。
3、深度优先搜索
现在我们用堆栈解决一个有意思的问题,定义一个二维数组:

它表示一个迷宫,其中的1表示墙壁, 0表示可以走的路,只能横着走或竖着走,不能斜着走,要求编程序找出从左上角到右下角的路线。
我们先看一段伪代码,也就是使用程序语言与自然语言交错的形式说明一下程序流程:
将起点标记为已走过并压栈;
while (栈非空) {
从栈顶弹出一个点p;
if (p这个点是终点)
break;
否则沿右、下、左、上四个方向探索相邻的点, if (和p相邻的点有路可走,并且还没走过)
将相邻的点标记为已走过并压栈,它的前趋就是p点;
}
if (p点是终点) {
打印p点的座标;
while (p点有前趋) {
p点=p点的前趋;
打印p点的座标;
}
} else{
没有路线可以到达终点;
}这次堆栈里的元素是结构体类型的,用来表示迷宫中一个点的x和y座标。我们用一个新的数据结构保存走迷宫的路线,每个走过的点都有一个前趋( Predecessor) 的点,表示是从哪儿走到
当前点的,比如predecessor[4][4]是座标为(3, 4)的点,就表示从(3, 4)走到了(4, 4),一开始predecessor的各元素初始化为无效座标(-1, -1)。在迷宫中探索路线的同时就把路线保存。在predecessor数组中,已经走过的点在maze数组中记为2防止重复走,最后找到终点时就根据predecessor数组保存的路线从终点打印到起点。
根据以上的分析,我们有一个示例源码,如下:
#include <stdio.h>
#define MAX_ROW 5
#define MAX_COL 5
struct point { int row, col; } stack[512];
int top = 0;
void push(struct point p)
{
stack[top] = p;
top++;
}
struct point pop(void)
{
top--;
return stack[top];
}
int is_empty(void)
{
return top == 0;
}
int maze[MAX_ROW][MAX_COL] = {
0, 1, 0, 0, 0,
0, 1, 0, 1, 0,
0, 0, 0, 0, 0,
0, 1, 1, 1, 0,
0, 0, 0, 1, 0,
};
void print_maze(void){
int i, j;
for (i = 0; i < MAX_ROW; i++) {
for (j = 0; j < MAX_COL; j++)
printf("%d ", maze[i][j]);
putchar('\n');
}
printf("*********\n");
}
struct point predecessor[MAX_ROW][MAX_COL] = {
{{-1,-1}, {-1,-1}, {-1,-1}, {-1,-1}, {-1,-1}},
{{-1,-1}, {-1,-1}, {-1,-1}, {-1,-1}, {-1,-1}},
{{-1,-1}, {-1,-1}, {-1,-1}, {-1,-1}, {-1,-1}},
{{-1,-1}, {-1,-1}, {-1,-1}, {-1,-1}, {-1,-1}},
{{-1,-1}, {-1,-1}, {-1,-1}, {-1,-1}, {-1,-1}},
};
void visit(int row, int col, struct point pre)
{
struct point visit_point = { row, col };
maze[row][col] = 2;
predecessor[row][col] = pre;
push(visit_point);
}
int main(void)
{
struct point p = { 0, 0 };
maze[p.row][p.col] = 2;
push(p);
while (!is_empty()) {
p = pop();
if (p.row == MAX_ROW - 1 /* goal */
&& p.col == MAX_COL - 1)
break;
if (p.col+1 < MAX_COL /* right */
&& maze[p.row][p.col+1] == 0)
visit(p.row, p.col+1, p);
if (p.row+1 < MAX_ROW /* down */
&& maze[p.row+1][p.col] == 0)
visit(p.row+1, p.col, p);
if (p.col-1 >= 0 /* left */
&& maze[p.row][p.col-1] == 0)
visit(p.row, p.col-1, p);
if (p.row-1 >= 0 /* up */
&& maze[p.row-1][p.col] == 0)
visit(p.row-1, p.col, p);
print_maze();
}
if (p.row == MAX_ROW - 1 && p.col == MAX_COL -1) {
printf("(%d, %d)\n", p.row, p.col);
while (predecessor[p.row][p.col].row !=-1) {
p = predecessor[p.row][p.col];
printf("(%d, %d)\n", p.row,p.col);
}
} else{
printf("No path!\n");
}
return 0;
}4、广度搜索
队列也是一组元素的集合,也提供两种基本操作: Enqueue(入队) 将元素添加到队尾, Dequeue(出队) 从队头取出元素并返回。就像排队买票一样,先来先服务,先入队的人也是先出队的,这种方式称为FIFO( First In First Out,先进先出) ,有时候队列本身也被称为FIFO。
为了帮助理解,我把这个算法改写成伪代码如下:
将起点标记为已走过并入队;
while (队列非空) {
出队一个点p;
if (p这个点是终点)
break;
否则沿右、下、左、上四个方向探索相邻的点, if (和p相邻的点有路可走,并且还没走过)
将相邻的点标记为已走过并入队,它的前趋就是刚出队的p点;
}
if (p点是终点) {
打印p点的座标;
while (p点有前趋) {
p点=p点的前趋;
打印p点的座标;
}
} else {
没有路线可以到达终点;
}从打印的搜索过程可以看出,这个算法的特点是沿各个方向同时展开搜索,每个可以走通的方向轮流往前走一步,这称为广度优先搜索。
#include <stdio.h>
#define MAX_ROW 5
#define MAX_COL 5
struct point {
int row, col, predecessor;
}
queue[512];
int head = 0, tail = 0;
void enqueue(struct point p)
{
queue[tail] = p;
tail++;
}
struct point dequeue(void)
{
head++;
return queue[head-1];
}
int is_empty(void)
{
return head == tail;
}
int maze[MAX_ROW][MAX_COL] = {
0, 1, 0, 0, 0,
0, 1, 0, 1, 0,
0, 0, 0, 0, 0,
0, 1, 1, 1, 0,
0, 0, 0, 1, 0,
};
void print_maze(void){
int i, j;
for (i = 0; i < MAX_ROW; i++) {
for (j = 0; j < MAX_COL; j++)
printf("%d ", maze[i][j]);
putchar('\n');
}
printf("*********\n");
}
void visit(int row, int col)
{
struct point visit_point = { row, col, head-1};
maze[row][col] = 2;
enqueue(visit_point);
}
int main(void){
struct point p = { 0, 0, -1 };
maze[p.row][p.col] = 2;
enqueue(p);
while (!is_empty()) {
p = dequeue();
if (p.row == MAX_ROW - 1 /* goal */
&& p.col == MAX_COL - 1)
break;
if (p.col+1 < MAX_COL /* right */
&& maze[p.row][p.col+1] == 0)
visit(p.row, p.col+1);
if (p.row+1 < MAX_ROW /* down */
&& maze[p.row+1][p.col] == 0)
visit(p.row+1, p.col);
if (p.col-1 >= 0 /* left */
&& maze[p.row][p.col-1] == 0)
visit(p.row, p.col-1);
if (p.row-1 >= 0 /* up */
&& maze[p.row-1][p.col] == 0)
visit(p.row-1, p.col);
print_maze();
}
if (p.row == MAX_ROW - 1 && p.col == MAX_COL -1) {
printf("(%d, %d)\n", p.row, p.col);
while (p.predecessor != -1) {
p = queue[p.predecessor];
printf("(%d, %d)\n", p.row,p.col);
}
} else {
printf("No path!\n");
}
return 0;
}5、环形队列
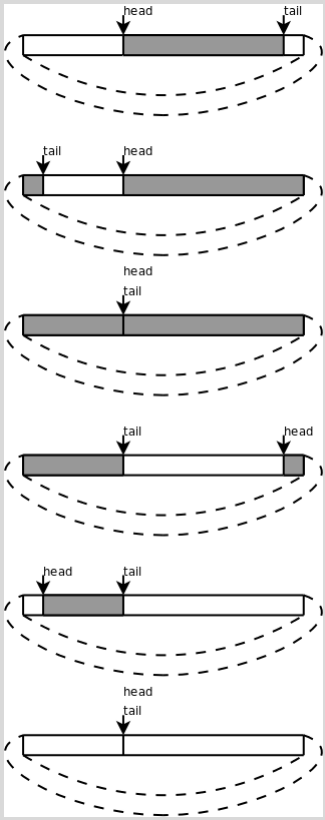
比较例 12.3 “用深度优先搜索解迷宫问题”的栈操作和例 12.4 “用广度优先搜索解迷宫问题”的队列操作可以发现,栈操作的top指针在Push时增大而在Pop时减小,栈空间是可以重复利用的,而队列的head、 tail指针都在一直增大,虽然前面的元素已经出队了,但它所占的存储空间却不能重复利用,这样对存储空间的利用效率很低,在问题的规模较大时(比如100×100的迷宫)需要非常大的队列空间。为了解决这个问题,我们介绍一种新的数据结构--环形队列( Circular Queue) 。
把queue数组想像成一个圈, head和tail指针仍然是一直增大的,当指到数组末尾时就自动回到数组开头,就像两个人围着操场赛跑,沿着它们跑的方向看,从head到tail之间是队列的有效元素,从tail到head之间是空的存储位置, head追上tail就表示队列空了, tail追上head就表示队列的存储空间满了。如下图所示:















 1848
1848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









