





GPU 被称为人工智能领域的稀土金属,甚至是黄金,因为它们是当今生成式人工智能时代的基础。
三个技术原因和许多故事解释了为什么会这样。每个原因都有多个方面值得探讨,但从高层次来看:
- GPU 采用并行处理。
- GPU 系统可扩展至超级计算高度。
- 用于 AI 的 GPU 软件堆栈广泛而深入。
最终结果是 GPU 比 CPU 执行技术计算的速度更快,能效更高。这意味着它们在 AI 训练和推理方面提供领先的性能,并在使用加速计算的广泛应用程序中带来收益。
斯坦福大学以人为本的人工智能小组在其最近的人工智能报告中提供了一些背景信息。报告称,自 2003 年以来,GPU 性能“提高了约 7,000 倍”,而性能价格比“提高了 5,600 倍”。
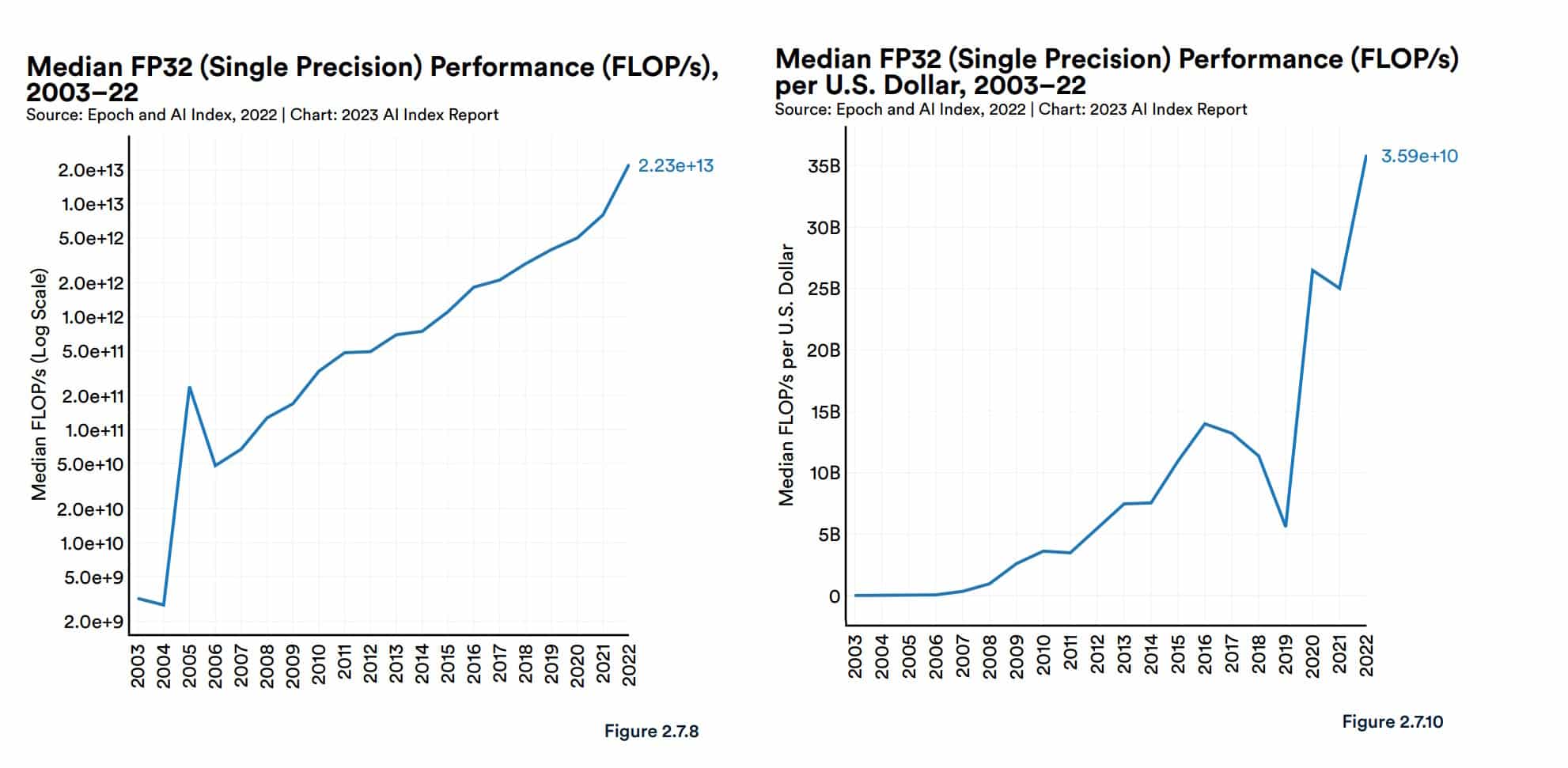
2023 年的一份报告记录了 GPU 性能和性价比的急剧上升。
该报告还引用了衡量和预测人工智能进步的独立研究机构 Epoch 的分析。
Epoch 在其网站上表示:“GPU 是加速机器学习工作负载的主要计算平台,过去五年中大多数(如果不是全部)最大的模型都是在 GPU 上进行训练的……[它们]因此为人工智能的最新进展做出了重要贡献”。
2020 年的一项评估美国政府人工智能技术的研究也得出了类似的结论。
该公司表示:“我们预计,在计算生产和运营成本时,(领先的)人工智能芯片的成本效益将比领先节点的 CPU 高出一到三个数量级。”
NVIDIA 首席科学家 Bill Dally 在半导体和系统工程师年度聚会 Hot Chips 的主题演讲中表示,NVIDIA GPU 在过去十年中将 AI 推理性能提高了 1,000 倍。
ChatGPT 传播新闻
ChatGPT 提供了一个有力的例子,展示了 GPU 如何助力 AI。大型语言模型(LLM) 在数千个 NVIDIA GPU 上进行训练和运行,运行着超过 1 亿人使用的生成式 AI 服务。
自 2018 年推出以来,AI 行业标准基准MLPerf已提供数字详细说明 NVIDIA GPU 在 AI 训练和推理方面的领先性能。
例如,NVIDIA Grace Hopper 超级芯片横扫了最新一轮推理测试。自该测试以来发布的推理软件NVIDIA TensorRT-LLM可将性能提高 8 倍,并将能耗和总拥有成本降低 5 倍以上。事实上,自 2019 年发布基准测试以来,NVIDIA GPU 赢得了每一轮 MLPerf 训练和推理测试。
2 月份,NVIDIA GPU在推理方面取得了领先的成绩,在 STAC-ML Markets 基准测试(金融服务行业的一项关键技术性能指标)中最苛刻的模型上每秒可进行数千次推理。
RedHat软件工程团队在博客中简洁地指出:“GPU已经成为人工智能的基础。”
人工智能的底层原理
简单看一下就能明白为什么 GPU 和 AI 可以组成强大的组合。
人工智能模型,也称为神经网络,本质上是一个数学千层面,由一层又一层的线性代数方程组成。每个方程代表一个数据与另一个数据相关的可能性。
就 GPU 而言,它包含数千个核心,这些微型计算器并行工作,对构成 AI 模型的数学运算进行切片。从高层次上讲,这就是AI 计算的工作原理。
高度优化的张量核心
随着时间的推移,NVIDIA 的工程师已根据 AI 模型不断变化的需求调整了 GPU 核心。最新的 GPU 包括Tensor Core,其处理矩阵数学神经网络所使用的能力比第一代设计强大 60 倍。
此外,NVIDIA Hopper Tensor Core GPU还包含一个Transformer Engine,它可以自动调整到处理Transformer 模型所需的最佳精度,Transformer 模型是产生生成式 AI 的一类神经网络。
在此过程中,每一代 GPU 都配备了更多的内存并优化了技术,以便将整个 AI 模型存储在单个 GPU 或一组 GPU 中。
模型不断发展,系统不断扩展
人工智能模型的复杂性每年增加 10 倍。
目前最先进的 LLM GPT4 包含超过一万亿个参数,这是衡量其数学密度的指标。相比之下,2018 年流行的 LLM 的参数不到 1 亿个。
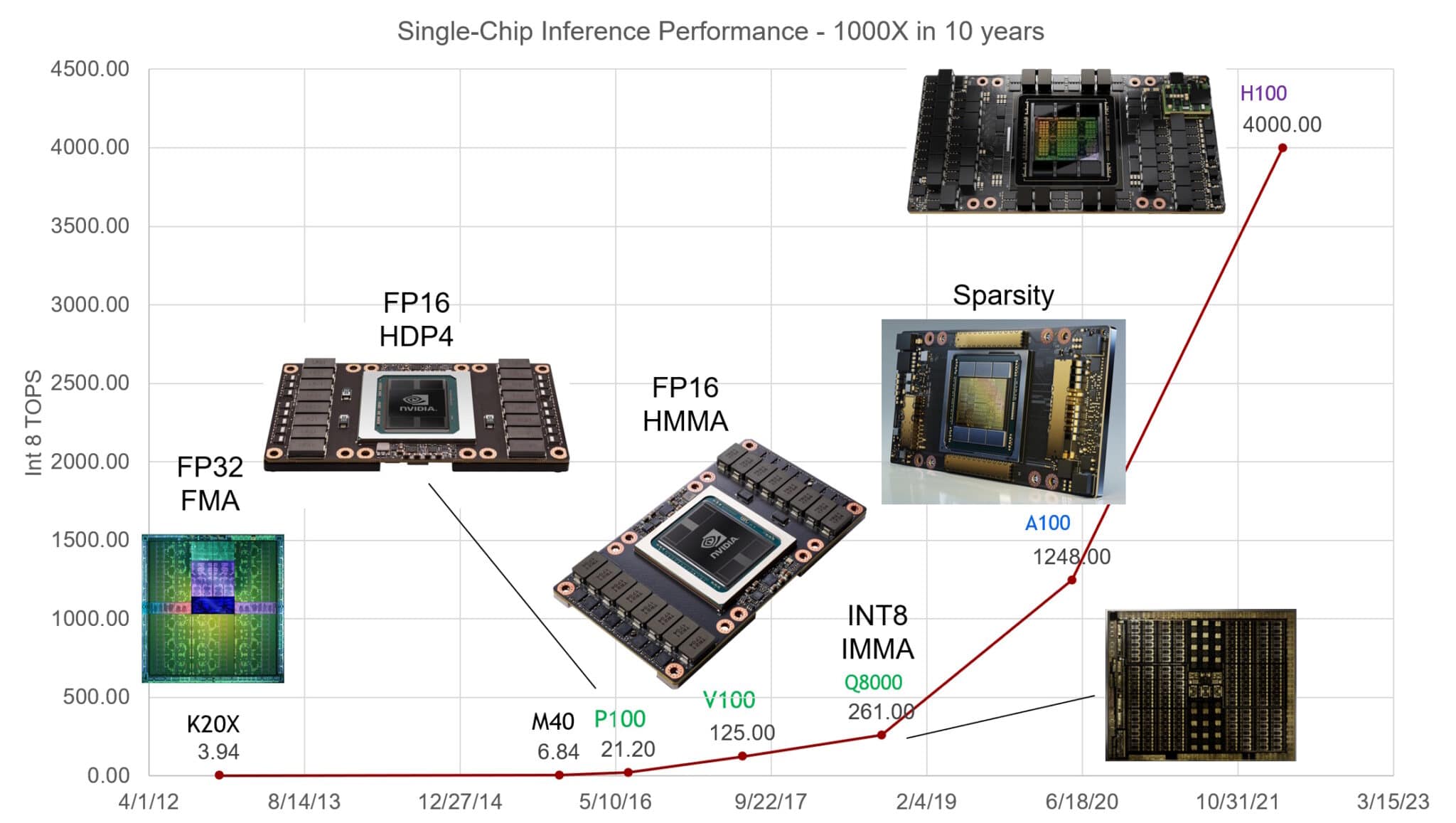
在最近的 Hot Chips 大会上,NVIDIA 首席科学家 Bill Dally 描述了过去十年中单 GPU 的 AI 推理性能如何提高了 1,000 倍。
GPU 系统通过联手应对挑战,与时俱进。得益于快速的NVLink互连和NVIDIA Quantum InfiniBand 网络,它们可扩展到超级计算机。
例如,大内存 AI 超级计算机DGX GH200将多达 256 个 NVIDIA GH200 Grace Hopper 超级芯片组合成一个数据中心大小的 GPU,并具有 144 TB 的共享内存。
每块 GH200 超级芯片都是一台服务器,配备 72 个 Arm Neoverse CPU 内核和 4 千万亿次浮点运算的 AI 性能。全新的四路 Grace Hopper 系统配置在单个计算节点中提供了高达 288 个 Arm 内核和 16 千万亿次浮点运算的 AI 性能,以及高达 2.3 TB 的高速内存。
11月份发布的NVIDIA H200 Tensor Core GPU搭载了高达 288 GB 的最新 HBM3e 内存技术。
软件覆盖海滨
自 2007 年以来,GPU 软件不断发展,支持 AI 的各个方面,从深度技术功能到高级应用程序。
NVIDIA AI 平台包含数百个软件库和应用程序。CUDA 编程语言和深度学习的 cuDNN-X 库为开发人员提供了一个基础,在此基础上,开发人员创建了NVIDIA NeMo等软件,这是一个框架,可让用户构建、自定义和运行自己的生成式 AI 模型的推理。
其中许多元素都是开源软件,是软件开发人员随身携带的必备品。NVIDIA AI Enterprise平台中集成了上百种元素,可供需要全面安全性和支持的公司使用。越来越多的主要云服务提供商也以NVIDIA DGX Cloud上的 API 和服务形式提供这些元素。
SteerLM是 NVIDIA GPU 的最新 AI 软件更新之一,它允许用户在推理过程中微调模型。
2008 年速度提升 70 倍
成功案例可以追溯到人工智能先驱 Andrew Ng(当时是斯坦福大学的研究员)在2008 年发表的一篇论文。他的三人团队使用两块 NVIDIA GeForce GTX 280 GPU,在处理具有 1 亿个参数的人工智能模型时,速度比 CPU 快 70 倍,在一天内完成了过去需要数周才能完成的工作。
他们报告称:“现代图形处理器的计算能力远远超过了多核 CPU,并有可能彻底改变深度无监督学习方法的适用性。”

吴恩达 (Andrew Ng) 在 2015 年 GTC 演讲中描述了他使用 GPU 实现 AI 的经历。
在2015 年 NVIDIA GTC 的一次演讲中,吴恩达描述了他如何继续使用更多 GPU 来扩大工作规模,在 Google Brain 和百度上运行更大的模型。后来,他帮助创立了 Coursera,这是一个在线教育平台,他在那里教授了数十万名 AI 学生。
吴恩达认为,现代人工智能教父之一杰夫·辛顿 (Geoff Hinton) 是受他影响的人之一。“我记得我曾对杰夫·辛顿说,看看 CUDA,我认为它可以帮助构建更大的神经网络,”他在 GTC 演讲中说道。
多伦多大学的这位教授传播了这个消息。 “我记得在 2009 年,我在 NIPS [现在的 NeurIPS] 上发表过一次演讲,我告诉大约 1,000 名研究人员,他们都应该购买 GPU,因为 GPU 将成为机器学习的未来,”Hinton 在新闻报道中说。
利用 GPU 实现快速发展
人工智能的进步预计将波及全球经济。
麦肯锡6 月份的一份报告估计,在其分析的银行、医疗保健和零售等行业的 63 个用例中,生成式人工智能每年可带来相当于 2.6 万亿至 4.4 万亿美元的收益。因此,斯坦福大学 2023 年人工智能报告中称,大多数企业领导者希望增加对人工智能的投资,这并不令人意外。
如今,超过 40,000 家公司使用 NVIDIA GPU 进行 AI 和加速计算,吸引了全球 400 万开发者。他们共同推动科学、医疗保健、金融和几乎所有行业的发展。
在最新成果中,NVIDIA 描述了利用 AI 减缓气候变化,将二氧化碳排除在大气之外,速度提高了 700,000 倍(见下方视频)。这是 NVIDIA 将 GPU 性能应用于 AI 及其他领域的众多方式之一。

















 4942
4942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









