






使用 OpenAI 的模型蒸馏构建高效的 AI 模型:综合指南
在本详细教程中,我们将探索 OpenAI 的模型蒸馏——这种方法允许您采用功能强大的大型 AI 模型,并创建更小、更优化的版本,而不会对其性能造成太大影响。想象一下,您有一个运行良好的复杂模型,但想要更轻量、更易于部署且更高效的模型,以适应移动或边缘计算等环境。这就是模型蒸馏发挥作用的地方。
在本教程结束时,您将掌握构建较小但功能强大的模型的知识。我们将介绍从设置开发环境、获取 API 密钥、创建训练数据到在实际场景中部署精简模型的所有内容。
什么是模型蒸馏?
模型提炼是将知识从大型复杂模型(即“老师”)转移到较小、更高效的“学生”模型的过程。这种较小的模型更易于部署、占用更少的资源、运行成本更低,同时力求达到与原始模型几乎一样好的性能。
随着 AI 模型变得越来越强大,它们对计算的要求也越来越高。在现实世界中部署这些大型模型(尤其是在智能手机等资源有限的设备上)可能具有挑战性。在手机上运行如此繁重的模型会很慢,会很快耗尽电池电量,并占用大量内存。模型提炼有助于创建一个更小、更快的版本,同时保留原始模型的大部分功能。
通过从大型模型生成高质量的输出,学生模型通过训练学会复制老师的行为。这种方法在资源受限的环境中尤其有用,因为在这种环境中部署大型模型是不可行的。对于那些有兴趣更深入地探索模型提炼的技术和好处的人,我在另一篇博客文章中详细介绍了这个主题。[详细博客文章的占位符]
模型提炼与微调
了解模型提炼和微调之间的区别非常重要,因为这是用于使 AI 模型适应特定任务的两种常用方法。
-
模型蒸馏是将大型模型压缩为较小模型的过程。大型模型通常称为“老师”,它会生成输出,然后用于训练较小的“学生”模型。学生模型会学习模仿老师的输出,使其适合计算能力有限的环境。蒸馏的目标是尽可能多地保留老师的知识,同时显著减少模型的大小和复杂性。
-
另一方面,微调是采用预先训练的模型,并通过在新的数据集上进行训练来调整它以适应特定任务的过程。微调通常涉及使用与原始训练数据相比较小的数据集,并允许模型专注于特定领域。与蒸馏不同,微调不一定会使模型更小或更快;相反,它使模型的知识适应新的环境。
总之,模型蒸馏侧重于创建更小、更高效的模型版本,而微调侧重于使模型适应新的特定任务。这两种技术都很有价值,但它们的用途不同。当部署效率是首要任务时,蒸馏是理想的选择,而当需要专业化时,微调则使用。
模型蒸馏的最佳实践
如需全面了解模型蒸馏,包括最佳实践和详细见解,请参阅OpenAI 模型蒸馏博客文章。该资源涵盖了训练数据质量、示例多样性、超参数调整、评估和迭代以及元数据的使用等重要方面。
由于我们使用 OpenAI 的托管模型,整个过程变得简单得多,许多资源管理和基础设施问题都由我们为您处理。我们不会部署大型模型,而是专注于使用 OpenAI 平台微调较小版本,使其适合移动和边缘计算任务。有关更详细的指导,请访问模型蒸馏博客。
设置开发环境
要进行模型蒸馏,首先需要设置本地开发环境。下面,我们将介绍所有步骤 - 从设置 Python、创建虚拟环境、获取 API 密钥到配置环境。
安装 Python 并设置虚拟环境
首先,确保已安装 Python。你可以从python.org下载 Python 。选择与你将使用的工具兼容的版本。
接下来,您需要创建一个虚拟环境来管理无冲突的依赖关系:
-
如果你还没有安装virtualenv,请先安装:
<span style="color:var(--tw-prose-pre-code)"><span style="background-color:var(--tw-prose-pre-bg)"><code class="language-bash">pip <span style="color:rgb(244 114 182/var(--tw-text-opacity))">install</span> virtualenv </code></span></span> -
在您的项目目录中创建虚拟环境:
<span style="color:var(--tw-prose-pre-code)"><span style="background-color:var(--tw-prose-pre-bg)"><code class="language-bash">virtualenv venv </code></span></span> -
激活虚拟环境:
-
在 Windows 上:
<span style="color:var(--tw-prose-pre-code)"><span style="background-color:var(--tw-prose-pre-bg)"><code class="language-bash">venv<span style="color:rgb(100 116 139/var(--tw-text-opacity))">\</span>Scripts<span style="color:rgb(100 116 139/var(--tw-text-opacity))">\</span>activate </code></span></span> -
在 macOS/Linux 上:
<span style="color:var(--tw-prose-pre-code)"><span style="background-color:var(--tw-prose-pre-bg)"><code class="language-bash"><span style="color:rgb(244 114 182/var(--tw-text-opacity))">source</span> venv/bin/activate </code></span></span>
-
-
安装所需的库:激活虚拟环境后,安装必要的库,包括 OpenAI 和 dotenv:
pip 安装 openai python-dotenv
获取您的 API 密钥
要使用 OpenAI,您需要一个 API 密钥。获取方法如下:
1.在 OpenAI 仪表板中创建一个项目:
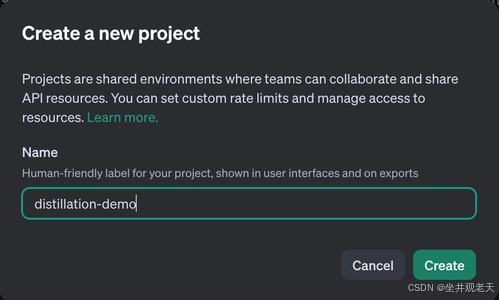
-
前往OpenAI 仪表板并登录,如果您没有帐户,请创建一个。
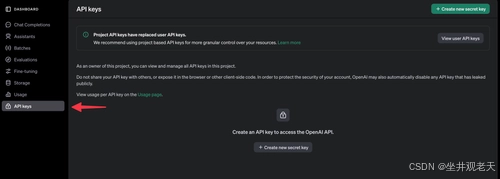
2.安全存储 API 密钥:
-
.env在您的项目目录中创建一个文件:OPENAI_API_KEY=your_openai_api_key_here
-
使用该库将此密钥加载到您的 Python 代码中
dotenv以确保其安全。
设置OpenAI客户端
现在,让我们使用 Python 设置 OpenAI 客户端:
from openai import OpenAI
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Set your OpenAI API key
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))上述代码初始化了 OpenAI 客户端,允许您发出 API 请求以与 OpenAI 的模型进行交互。此设置对于存储模型输出和管理蒸馏过程至关重要。
选择你的教师模式
“教师”模型是一种预先训练的高性能模型,您将使用它作为训练学生模型的基础。在本指南中,我们将使用该gpt-4o模型,该模型功能强大且用途广泛,适用于多种语言任务。
选择正确的教师模型是关键,因为它决定了传授给学生的知识质量。OpenAI 为不同的用例提供了几种预先训练的模型,例如语言处理、图像识别等。
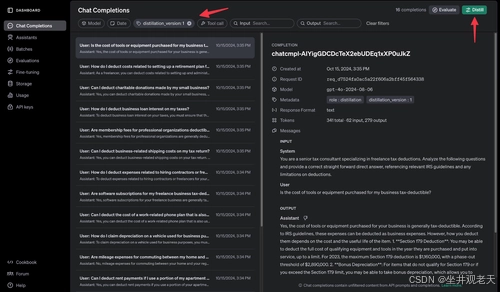
创建蒸馏训练数据
蒸馏过程涉及根据教师模型的输出创建训练数据集。在本节中,我们将使用该store: true选项保存教师模型的输出,然后将其用于训练学生模型。
模型蒸馏的主要目的是利用教师模型的知识和推理能力来生成学生模型可以借鉴的高质量输出。通过在这些输出上训练较小的模型,我们的目标是让它尽可能接近地复制教师模型的性能。这种方法使学生模型能够实现相当的准确性和推理能力,同时显著减轻重量和提高效率,使其适合在计算资源有限的环境中部署。
以下是使用 OpenAI 模型生成训练数据的示例代码片段gpt-4o:
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "You are a senior tax consultant specializing in freelance tax deductions."},
{"role": "user", "content": "Can I deduct the full cost of my laptop from my taxes if I use it for both work and personal tasks?"},
],
store=True,
metadata={
"role": "distillation",
"distillation_version": "1"
}
)
print(response.choices[0].message.content)在此代码中:
- 我们使用教师模型(
gpt-4o)创建一个完成品。 - 我们包含元数据来标记数据,以便以后轻松过滤。
- 该
store: true参数确保响应被保存并在 OpenAI 仪表板中可见,从而形成学生模型的训练数据集。
您可以通过循环一组问题来生成多个答案。OpenAI 建议至少有 10 个示例用于基本提炼目的,但为了获得更好的用例和生产级结果,建议有几百个示例。
以下是一个更全面的代码示例,它从一系列与税收相关的问题中生成训练数据:
from openai import OpenAI
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Set your OpenAI API key
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
tax_questions = [
"Can I deduct the full cost of my laptop from my taxes if I use it for both work and personal tasks?",
"Are home office expenses deductible if I only work from home part-time?",
"Can I deduct travel expenses for a conference if I also took a vacation during the trip?",
"How do I deduct business meals on my tax return?",
"What percentage of my internet bill can I deduct if I use it for both personal and business purposes?",
"Can I deduct rent payments if I use a portion of my apartment as a home office?",
"Is the cost of professional development courses tax-deductible for freelancers?",
"Can I deduct health insurance premiums as a self-employed person?",
"Are mileage expenses for commuting between my home and my office deductible?",
"How do I claim depreciation on a vehicle used for business purposes?",
"Can I deduct the cost of a work-related phone plan that is also used for personal calls?",
"Are software subscriptions for my freelance business tax-deductible?",
"How do I deduct expenses related to hiring contractors or freelancers for my business?",
"Can I deduct business-related shipping costs on my tax return?",
"Can I deduct advertising expenses for my small business?",
"Are membership fees for professional organizations deductible for freelancers?",
"How do I deduct business loan interest on my taxes?",
"Can I deduct charitable donations made by my small business?",
"How do I deduct costs related to setting up a retirement plan for myself as a freelancer?",
"Is the cost of tools or equipment purchased for my business tax-deductible?",
]
# Function to call OpenAI and print the response
def get_openai_response(model_name, question):
response = client.chat.completions.create(
model=model_name,
messages=[
{
"role": "system",
"content": "You are a senior tax consultant specializing in freelance tax deductions. Analyze the following questions and provide a correct straightforward direct answer, referencing relevant IRS guidelines and any limitations on deductions."
},
{"role": "user", "content": question},
],
temperature=0.25,
top_p=0.9,
store=True,
metadata={
"role": "distillation",
"distillation_version": "1"
}
)
print(f"Response from {model_name}:")
print(f"Question: {question}")
print(response.choices[0].message.content)
print("=" * 50) # For separation between responses
# Generate responses for all questions
def evaluate_all_questions(model_name):
print(f"Generating with model: {model_name}:")
for i, question in enumerate(tax_questions, 1):
print(f"Question {i}:")
get_openai_response(model_name, question)
# Run evaluations on the teacher model
print("Evaluating GPT-4o (Teacher Model):")
evaluate_all_questions("gpt-4o")这将创建一个全面的数据集,捕捉教师模型的知识,并有助于确保为提炼目的提供强大的训练集。
训练学生模型
准备好数据集后,就该训练学生模型了。这就是提炼过程:较小的模型从教师模型的输出中学习。
开始训练:
-
访问 OpenAI 仪表板:登录并导航到存储教师模型输出的项目。
-
选择已存储的完成:根据标签或其他元数据过滤已存储的完成。
-
启动提炼:单击“提炼”按钮,使用存储的完成情况对学生模型进行微调。
-
设置参数:配置学习率、批量大小和训练周期等参数。试验这些设置有助于获得最佳结果。
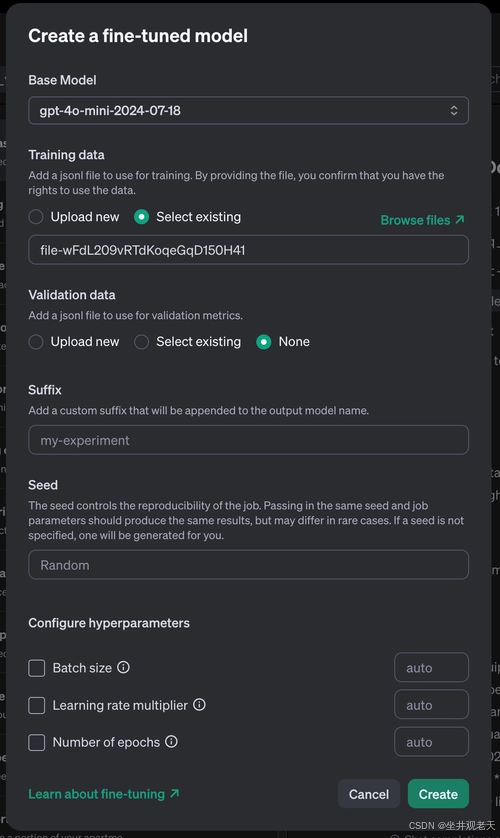
配置完成后,单击“创建”即可开始训练。微调过程可能需要 15 分钟到几个小时,具体取决于数据集大小和使用的计算资源。
微调学生模型
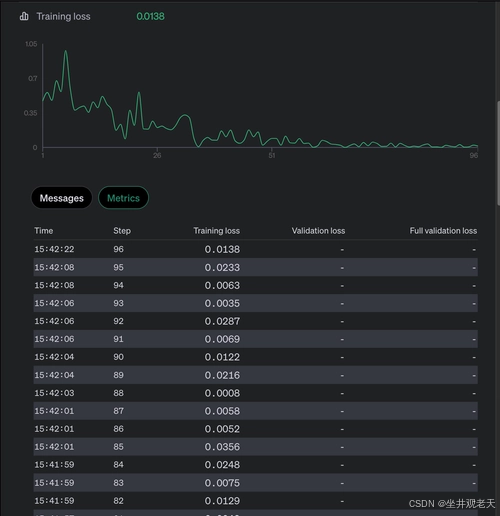
在此阶段,您将专注于评估和优化学生模型,根据训练期间收集的性能指标对其进行微调。训练过程完成后,您可以查看关键详细信息,例如处理的标记总数、完成的时期、批处理大小、学习率乘数以及用于模型初始化的种子。例如,您可能会看到诸如训练了 24,486 个标记、完成了 6 个时期、批处理大小为 1 以及学习率乘数设置为 1.8 之类的指标。这些参数可让您深入了解模型在训练期间的行为,并允许您根据需要进行调整。
检查点是微调期间要监控的另一个关键方面。每个检查点代表特定间隔内模型的保存版本,可让您比较不同训练阶段的性能。例如,您可能有诸如 等检查点ft:gpt-4o-mini-2024-07-18:{your org}::AIYpXq2U:ckpt-step-64。这些检查点不仅可以作为备份,还可以让您评估模型在不同阶段的表现。
此外,您还可以访问训练损失等关键指标,这有助于您衡量模型与训练数据的拟合程度。训练损失可以用多个步骤中的值(如 0.0138)表示,表明模型随时间的进展。通过查看这些信息,您可以做出明智的决定,确定模型是否需要进一步调整或是否已准备好部署。如有必要,您可以调整超参数(如学习率或批次大小),然后重新运行训练以获得更好的结果。
微调过程通常需要一些时间,从几分钟到几小时不等,具体取决于数据集的大小和可用的计算资源。完成后,您可以比较训练和验证损失以评估过度拟合或欠拟合,然后继续部署优化的模型。
在操场上进行比较
本节展示了 GPT-4.0、GPT-4.0-mini 及其微调版本之间的实际差异。通过比较这些输出,您可以清楚地看到微调如何影响模型的性能,从而让您更好地了解针对特定领域任务的定制模型的优势。
GPT-4.0 与微调迷你模型
GPT4O:

GPT40-迷你:
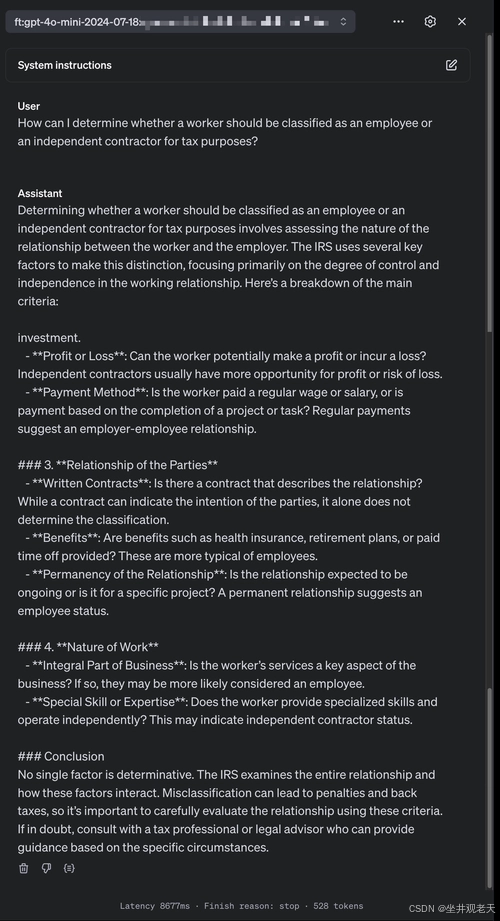
在第一个比较中,GPT-4.0 提供了一个全面但有些笼统的答案。它分解了决定工人是被归类为雇员还是独立承包商的因素。虽然准确,但这种解释似乎更适合广大受众。它涵盖了行为控制、财务控制和关系类型等关键要素,但缺乏使其更适用于特定业务场景的特定领域细微差别。
现在,看看微调模型的响应,差异就变得明显了。微调版本提供了更有针对性的答案,仍然涵盖相同的基本 IRS 标准,但感觉更清晰,更符合具体用例。它消除了任何不必要的宽泛性,深入探讨了员工与承包商之间的区别,展现了更高的精确度。它还以更结构化的方式组织信息,为分类决策过程提供更清晰的指导。
经过微调的模型擅长产生有针对性且与特定任务相关的输出,使需要精确答案的用户无需筛选一般信息即可获得更轻松的结果。
GPT-4.0-mini 与微调 Mini 模型

GPT-4.0-mini 的输出在深度方面与完整的 GPT-4.0 模型明显不同。它提供了更快的响应,但牺牲了细节。它只是简要地涉及对工人进行分类的因素,提供了更表面的视角。虽然它很高效并且回答了问题,但响应感觉有些仓促且不够彻底,这在处理需要细致理解的更复杂任务时可能是一个缺点。
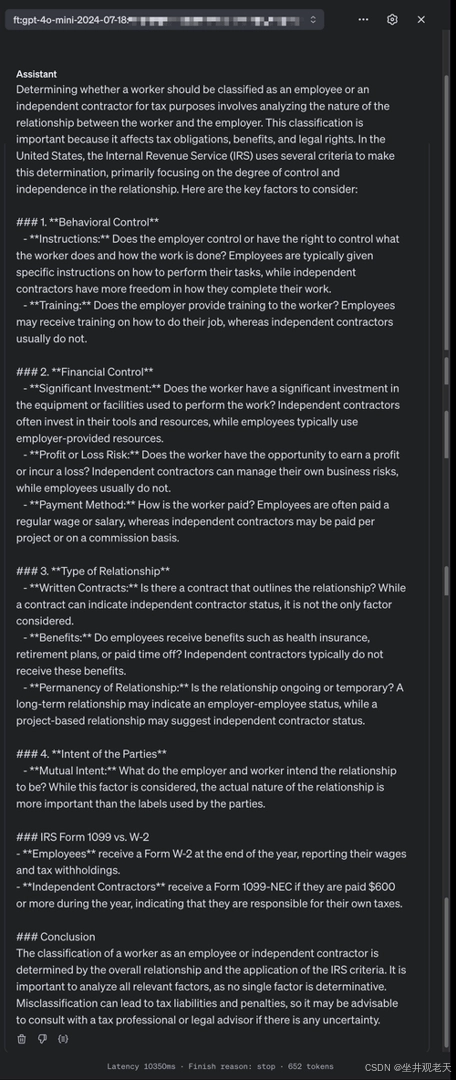
另一方面,经过微调的迷你模型弥补了这一差距。在保持 GPT-4.0-mini 效率的同时,经过微调的版本提供了更完整的答案。它包含更多相关细节,仔细区分不同类型的控制(行为、财务),并添加通用 GPT-4.0-mini 响应中缺少的宝贵背景信息。当您需要快速响应而不影响信息质量时,这使其成为一个更通用的选择。
经过微调的迷你模型提高了输出的相关性和实用性,而不会引入不必要的复杂性,在速度和准确性之间保持了良好的平衡。
比较中的关键观察结果
-
深度与精度:比较表明,虽然 GPT-4.0 提供了全面的响应,但微调模型侧重于提供精度和相关性。微调模型的响应更适合特定领域的任务,而像 GPT-4.0 这样的通用模型可能会产生信息过载或缺乏必要的重点。
-
效率和上下文:GPT-4.0-mini 速度更快,但细节较少。然而,经过微调后,迷你模型变得既高效又具有上下文感知能力,使其成为需要速度和相关性的任务的良好中间地带。
-
实际应用:经过微调的模型在应用于特定任务或行业时表现出色。它们经过量身定制,可提供更有针对性的指导,消除了基础模型的宽泛性。这可以在特定见解至关重要的商业或技术应用中产生巨大影响。
这些见解证明了 GPT-4.0 和 GPT-4.0-mini 等微调模型对于需要精确度和上下文的任务的价值。微调将这些模型从通用助手转变为可以直接满足您的领域的工具,使响应更具可操作性和相关性。
考虑到这一点,Playground 提供了一个完美的环境来试验这两个版本,让您可以直观地比较每个模型如何处理特定查询并根据您的独特需求评估它们的性能。
结论和后续步骤
总之,我们探索的微调过程展示了如何根据您的特定需求定制模型可以大大提高其性能。通过微调,您不仅仅依赖通用 AI;您还将其转变为强大的特定领域工具,可以提供更准确、更相关和更能感知上下文的响应。这正是 OpenAI 的免费微调优惠(截至10 月 31 日)对开发人员来说是一个黄金机会的原因。每个开发人员都应该利用此优惠,因为它允许您试验、训练和优化模型,而无需通常的成本障碍。
为了进一步提高模型的质量,而不仅仅是进行基本的微调,我建议创建一个强大的训练数据集,该数据集反映了模型需要处理的任务类型。该数据集应反映特定于您的用例的真实场景,确保您的模型在训练期间接触到正确类型的信息。
此外,使用 OpenAI Evals 等评估工具来持续监控和改进模型的性能也至关重要。训练、评估和调整的迭代过程将帮助您随着时间的推移实现近乎完美的效果。这不仅可以最大限度地发挥模型的潜力,还可以确保模型保持灵活性并适应不断变化的需求。通过微调和评估迭代模型的性能,您可以将其提升到一个新的水平,并真正掌握构建专用 AI 系统的艺术。
现在是采取行动的时候了——使用免费的微调窗口来开发一个能够在未来为您和您的项目服务的模型。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









