







Human Acitvity Analysis: A review
这篇论文发表是在2011年,是德克萨斯大学的J.K. Aggarwal教授所写。他是动作识别,行为识别,面部识别界的大牛。看过他的简历上一长串发表的文章,让我等汗颜。他现在仍然在研究上很活跃,主要的兴趣是在计算机视觉,模式识别,图像处理尤其是在人体动作和行为识别方面。
这篇论文是他继99年写过一篇综述关于人体动作分析,当时主要是关于人体动作的分析,主要是原子动作,诸如,行走,跑,弯腰,跳跃等。而在11年写的这个综述更加是面向复杂的行为分析和理解。比如说人与环境之间的交互,人物之间,群体之间的行为的理解。
先看摘要了解一下这篇文章的主要内容 。
Human activity recognition is an important area of computer vision research. Its applications include surveillance
systems, patient monitoring systems, and a variety of systems that involve interactions between persons and electronic devices such as human-computer interfaces. Most of these applications require an automated recognition of high-level activities, composed of multiple simple (or atomic) actions of persons. This article provides a detailed overview of various state-of-the-art research papers on human activity recognition. We discuss both the methodologies developed for simple human actions and those for high-level activities.
An approach-based taxonomy is chosen that compares the advantages and limitations of each approach.
人体行为识别是计算机视觉研究的一个重要的领域。它的应用包括监控系统,病人监护系统,和各种各样的涉及到人与电子设备交互的诸如人机界面的交互的系统。这些应用多数需要自动的识别高级行为,由多个简单(原子)的人体动作构成。这篇论文提供了一个详细的概述关于人体行为识别的应用了最先进技术的论文。我们即讨论了为简单的人体动作而研发的方法论也讨论了那些为了高级行为发展的方法论。基于方法的分类法被选择来比较每一种方法的优点和限制。
Recognition methodologies for an analysis of the simple actions of a single person are first presented in the article. Space-time volume approaches and sequential approaches that represent and recognize activities directly from input images are discussed. Next, hierarchical recognition methodologies for high-level activities are presented and compared. Statistical approaches, syntactic approaches, and description-based approaches for hierarchical recognition are discussed in the article. In addition, we further discuss the papers on the recognition of human-object interactions and group activities. Public datasets designed for the evaluation of the recognition methodologies are illustrated in our article as well, comparing the methodologies’ performances. This review will provide the impetus for future research in more productive areas.
单人的简单行为分析的识别方法首先在这篇论文里面进行讲述。时空体积方法和序列方法直接从输入图像中表示和识别行为首先被讨论。接下来,为了进行高级行为分析,陈述和比较了分层的方法。而且,我们进一步的讨论了关于人体-物体交互和群体行为的识别的论文。为了识别方法的评估设计的公共数据集也在我们的论文中详细的进行了讲述,同时比较了方法之间的性能。这篇综述将会在更多富有成效的领域为未来的研究提供动力和促进。
通过摘要我们可以看到这篇文章的主要内容。单人的原子行为识别不再是重点,而是假定我们已经能够很好的识别了简单的原子行为的基础之上,对高级行为进行分析和理解的一篇综述。让我等菜鸟无处洒泪。简单的动作识别我还做不出来,然而高深的人体-物体交互,群体行为的分析已经开始了。这篇论文的大体的内容可以从下图中看到。这也是本篇论文的脉络。
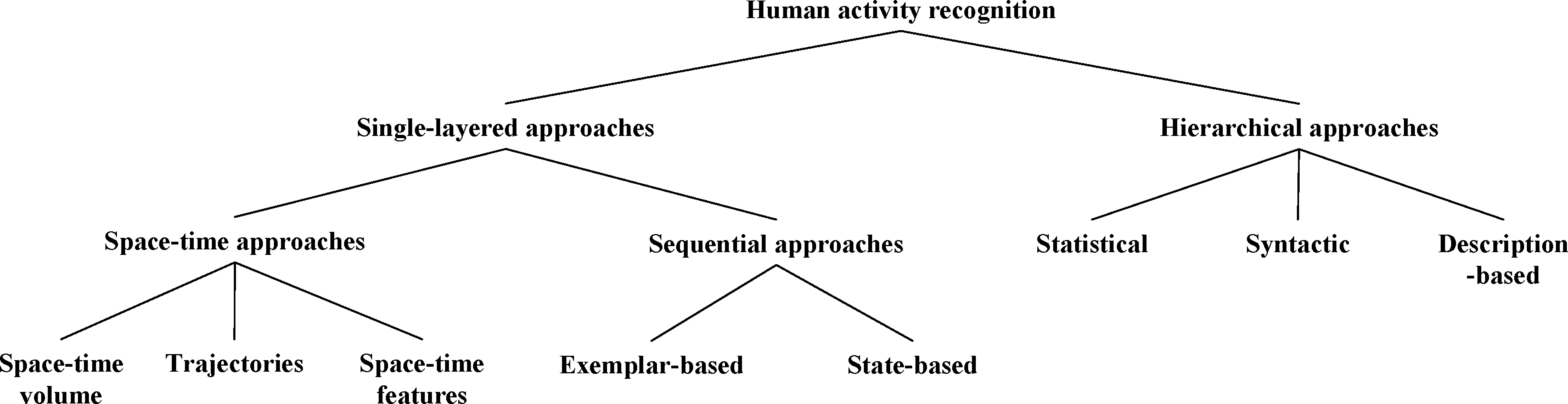
单层方法是那种直接基于图像序列来表示和识别人体行为的方法,由于它们的性质,单层方法适合于具有顺序特征的姿势和动作的识别。而另一方面,等级的方面通过就其他更加简单的行为而言描述它们来表示高级的人体行为,这些更加简单的行为又称为子事件。适合于复杂行为的识别。单层方法通过它们是如何建模人体行为又分成了两个类型,即时空方法和顺序方法。时空方法把输入看成一个3D(XYT)体积,而顺序方法把它解释成为一个观察序列。等级方法通过它们使用的识别方法分成统计方法(分层的隐式马尔科夫模型),句法方法(上下文无关文法,随机上下文无关文法)和基于描述的方法(通过描述行为的子事件,它们的时间,空间和逻辑关系)。

单层方法
单层方法直接从视频数据识别人体行为。多数单层方法采用滑动窗口技术,来分类所有可能的子序列。两个类别,时空方法把一个人体行为建模成时空维中一个特定的3-D体积或者从这个体积上提取的一组特征。视频体积通过沿着时间轴把图像帧串联起来构件。顺序方法则是把人体行为看成特定观察的序列。更具体的,他们把人体行为表示成为从图像中提取的一个特征向量序列,通过查找这样的一个序列而识别行为。
时空体积
使用时空体积进行识别的和兴是在两个体积之间进行相似判定。Bobick和Davis构建的运动历史图和运动能量图。MEI,MHI
时空体积的主要缺陷是当多个人在场中出现时,识别动作的难题。
使用时空轨迹
基于轨迹的方法是那种把一个行为阐述为一组时空轨迹的方法。在基于轨迹的方法中,人体通常被表示为一组二维点XY或者三维点XYZ对应于它的肢体位置。由Johansson[1975]早期的工作表明肢体位置的跟踪对于区分度工作室足够的,并且这个范例已经为了行为识别进行了深度研究。这方面相关的论文有[Sheikh et al; Yilmaz and Shah 2005;]Campbell and Bobick把人体行为表示成低维相空间中的曲线。而Rao and Shah的方法是从轨迹中提取有意义的曲率模式。基于轨迹的主要优点是他们的分析人体移动的能力,多数方法是视角不变的。问题是3D身体部位检测和跟踪仍然是一个未解决的问题,并且研究人员在这个领域正在活跃的工作。
使用时空局部特征
这类方法之后的动机是这个事实,一个3D时空体积实质上是一个刚性的3D物体。在这一部分,我们重点在三个方面:方法提取了那些3D局部的时空特征,就他们提取的特征而言,他们是如何表示行为的,他们使用什么方法对行为进行分类。局部特征,局部描述子,感兴趣点。Chomat and Crowley提出了使用局部外观描述子的思想来描述一个行为,因此使动作分类成为了可能。Harris corner,稀疏的局部外观特征,诸如SIFT。Dollar等提出了一个新的时空特征检测子用于人体动作的识别。在他们的方法中,他们的检测子尤其被设计来提取具有周期运动的时空点,从一个视频中获得感兴趣点的稀疏分布。检测之后,他们把一个小的3D正方体称为cuboid,关联到每一个感兴趣点。每个cuboid捕获了感兴趣点邻域的像素外观。时空方法提取局部描述子具有几个优点,由于它的性质,背景差分或者其他的低级成分通常是不需要的,并且局部特征是尺度,旋转,平移不变的。尤其适合于识别简单的周期运动诸如行走,挥手,因为周期动作将会重复的产生特征模式。
比较:施工时空体积的方法提供了简单的方法,但在处理速度和移动方面具有一致的困难。基于施工特征的方法主要缺陷不适合于建模复杂行为,也必须解决视角不变性的问题。
顺序方法:
顺序的方法是那些单层的方法,它们通过分析特征序列来识别人体行为。这样的方法把输入视频考虑为一个观察序列或者特征学列,并且如果如果他们能够观察到一个描述这个行为的特定序列,就推断在这个视频中一个行为已经发生。顺序方法首先把一个序列的图像转换成为一个序列的特征。一旦特征向量已经被提取出来,顺序的方法分析这个序列来推测由这个人执行这个行为所产生的特征向量多么相似。如果在序列和行为类之间的相似性足够高,系统会决策行为发生。也分成两类,基于范例的识别和基于状态模型的方法。
基于范例的方法
基于范例的方法通过维持一个模板序列或者一组样本动作序列执行来表示人体的行为。DTW,动态时间规整,被广泛用于比较两个具有变化的序列。DTW找到在两个序列之间的一个最优的非线性匹配,具有多项式的计算量。
基于状态模型的方法。
基于状态模型的方法是顺序方法,它把一个人体行为表示为由一组状态组成的行为模型。这个模型被统计训练,以使它对应于属于它的行为类的特征向量序列。更具体的,统计模型被设计来产生一个具有特定概率的序列。。通常,为每一个行为构建一个统计模型。对每个模型来说,模型产生一个受到观察的特征向量序列的概率被计算来推测动作模型和输入图像序列的相似性估计。或者极大似然估计或者最大后验概率密度因此被构建,为了识别行为。
隐式马尔科夫模型和动态贝叶斯网络已经被广泛的用于基于状态模型的方法。一个行为就一组隐含状态而言被表示,一个人体被假定在每一个时间帧上处于一个状态。在下一帧,系统过度到另一个状态,考虑到状态之间的转移概率。一旦转移和观察概率为了这个模型被训练得到,行为通常通过解决评估问题而得到识别。评估问题是计算由给定的状态模型产生的一个给定序列的概率的问题。
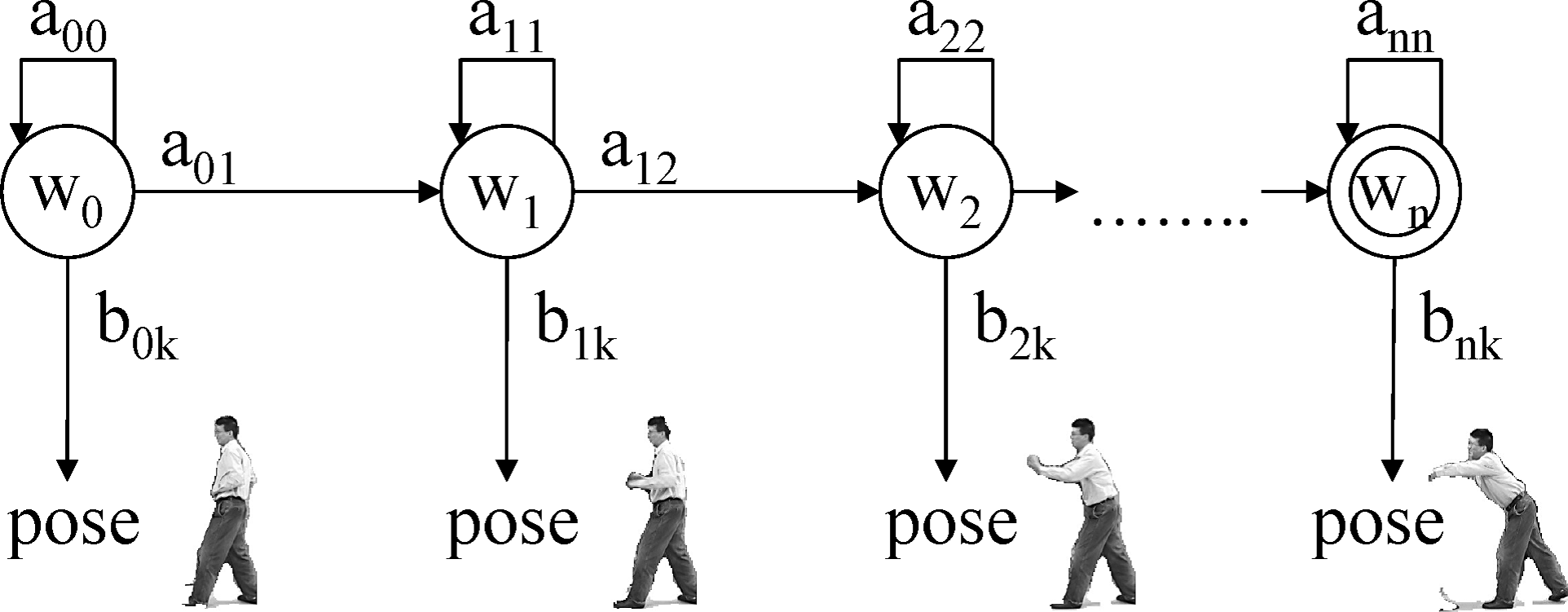
HMM是一个序列模型,一次只有一个状态被激活。一个DBN是一个HMM的延伸,由多个条件独立的隐含节点构成。
比较:
多样本序列
动态时间规整DTW可用于基于范例的方法,提供了一个非线性匹配方法,该方法考虑了执行速度的变化。而且可以处理更少的训练数据。而基于状态的方法能够做出行为的概率分析。一个基于状态的方法能够计算出一个行为发生的后验概率密度,使它能够与其他的决策容易得结合。一个限制是他们往往需要大量的训练。
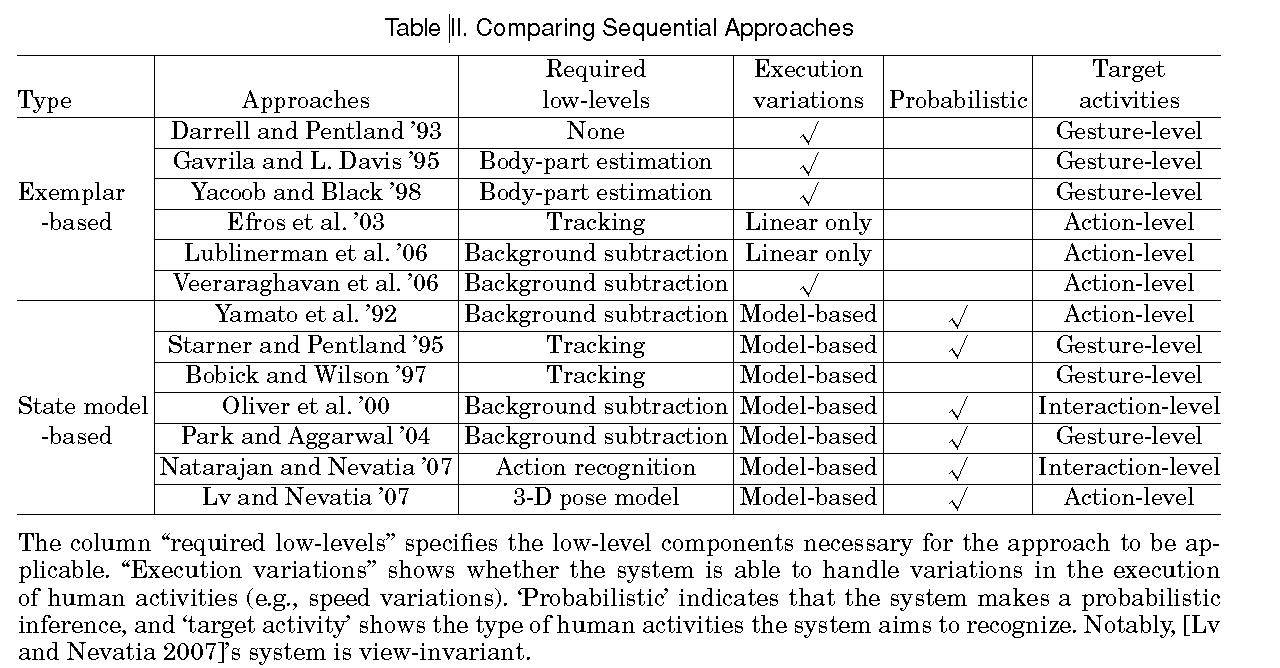
3, 分层方法
在分层方法之后的主要思想是使得高级行为的识别能够建立在其他的更加简单的行为的识别结果之上。动机是使得更加简单的子行为(也称为子事件)相对容易识别的进行首先进行建模,然后使用它们进行高级行为的识别。子事件充当着高级行为产生的观察。分层表示的范式不仅仅使得识别过程在计算上可处理,概念上可理解,而且也通过多次重用被识别的子事件从而降低了识别过程中的冗余性。分层方法比不分层的方法的主要优点是他们的识别具有复杂结构的高级行为的能力。分层的方法更加适合于人人之间或者人与物,以及复杂的群体行为的交互的语义级别的分析。这个优点是分层方法的两个能力的结果。能够处理较少的训练数据的能力,和能够整合先验的知识到表示的能力。
我们把分层的方法分成了三组:基于统计的方法,基于句法的方法,和基于描述的方法。
基于统计的方法
统计方法使用基于统计状态的模型来识别行为。在分层统计方法的情形下,多层基于状态的模型(通常是两层)诸如HMMs和DBNs被用来识别具有序列结构的行为。在底层,从特征向量序列识别原子行为,正如在单层序列方法。因此,特征向量的序列被转换成为原子动作的序列。第二层模型把这个原子动作的序列看做由第二层模型所产生的观察。对每个模型来说,模型的概率产生一序列的观察(即原子级的动作)被计算来测量行为和输入的图像序列之间的相似性。作为结果或者极大似然估计或者最大后验概率密度分类器被构建。Oliver等提出了分层的隐马尔可夫模型,它是分层统计方法的最基本的模型。在这个方法中,底层HMMs通过匹配模型与从视频中提取出来的特征向量序列来识别单个人的原子动作。叫上层HMMs把被识别的原子动作当做由较上层HMMs所产生的观察。即,实际上他们把一个高级行为表示成原子动作序列,通过使较上层HMM的每个状态从概率上对应于一个原子动作。从性质上来说,一个行为的所有子事件被要求在每一个LHMM中是严格顺序的。Shi等提出使用传播网P-net的分层方法。一个P-net的结构与HMM类似。行为就多个状态节点,变迁概率,观察概率而言被表示。他们的工作也把动作分解成几个原子级动作,并构建了一个网络来描述它们中所需要的时序关系。P-net和HMM的主要差别是P-net允许多个状态节点同时激活。这意味着P-net能够建模由并发的行为和序列的子行为所构成的高级行为。如果子事件是通过这个图所指定的特定时序顺序进行激活,系统能够推到出行为的发生。
基于统计的方法尤其适合于识别顺序行为。具有足够的训练数据,统计模型能够可靠的识别对应的行为,即使是噪音输入的情形。统计方法的主要缺陷是他们不能处理具有复杂结构的行为,诸如由并发的子事件所组成的行为。
句法方法
句法方法把人体行为建模成一个符号串,每一个符号对应于一个原子级别的动作。与分层统计方法相似,句法的方法也需要首先识别原子级别的动作,使用任何以前的技术。人体行为被表示为一组产生式规则(production rule)产生一个原子动作串,并通过编程语言领域的句法分析方法加以分析。上下文无关无法(Context-free grammars, CFGs)和随机上下文无关文法(Stochastic context-free grammars, SCFGs)已经被研究者广泛用来识别高级行为。CFGs的产生式规则自然的导致行为的分层表示和识别。
其中Icanov and Bobick提出了一个层次方法来识别高级行为,利用SCFGs。Moore and Essa也使用SCFGs进行行为的识别,更多的聚焦于多任务的行为。Joo and Chellappa设计了一个属性文法进行识别,它是SCFGs的扩展。
基于句法的方法的缺陷之一是并发行为的识别。句法的方法能够在概率上识别由并发的子事件组成的行为,但对于由并发行为所组成的事件具有内在的限制。由于句法的方法建模一个高级行为成一个原子行为的串,原子级行为的时序性必须严格顺序的。而且,基于句法的方法假定所有的观察都通过应用产生式规则进行句法分析。对这些系统而言,用户必须提供对所有可能事件的一套产生式,甚至是一个非常大的领域。因此,如果当一个未知的观察与系统交互的时候,他们往往具有困难。为了克服这些限制,Kitani等人在 07年提出啊从观察中自动的学习语法规则来改进。
基于描述的方法
一个基于描述的方法是一种显式的维持行为的时空结构的识别方法。它把一个高级行为表示成组成这个行为的更简单的行为(即子事件),描述它们的时间,空间,和逻辑关系。即基于描述的方法把人体行为建模成它的子事件的发生(子事件也可以拥有自己的子事件。)。这些子事件满足特定的关系。因此,行为识别是通过查找安祖由它的表示所指定的的关系的子事件的查找来执行的。所有基于描述的方法内在是分层的,因为它们使用子事件来表示人体行为。并且能够处理并发的结构。
在基于描述的方法中,时间间隔通常指定子事件之间的必要的时间关系的发生的子事件有关。其中Allen's的时间谓词被广泛的使用。他定义了七个基本谓词:before,meets,overlaps,during,starts,finishs,and equals。需要注意的是before和meets描述了顺序关系而其他的谓词用来指定并发的关系。在基于描述方法中,CFG通常用来作为人体行为表示的正式句法。这与之前句法方法中上下文无关文法的使用完全不同:基于句法的方法使用CFGs来进行识别,暗示了CFGs它们自己来描述行为的语义结构。另一方面,基于描述的方法采用CFGs作为一个句法正规的表示行为。行为的语义通常编码在类似于编程语言的结构中,并且CFG仅仅起着行为表示满足语法的作用。















 2277
2277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









