







简介
Intel MIC 集成众核(Many Integrated Core)架构是将多个核心整合在一起的处理器,面向HPC(High Performance Computing)领域。在其计算机体系中,并非欲取代CPU,而是作为协处理器存在的。
虽然Intel官方声称原生的CPU程序无需进行大的改动即可在MIC芯片上运行,但在具体的应用移植过程中发现,真实的应用在MIC架构下通常都会在规模、内存以及第三方库移植等各方面受到一定的制约。
硬件架构
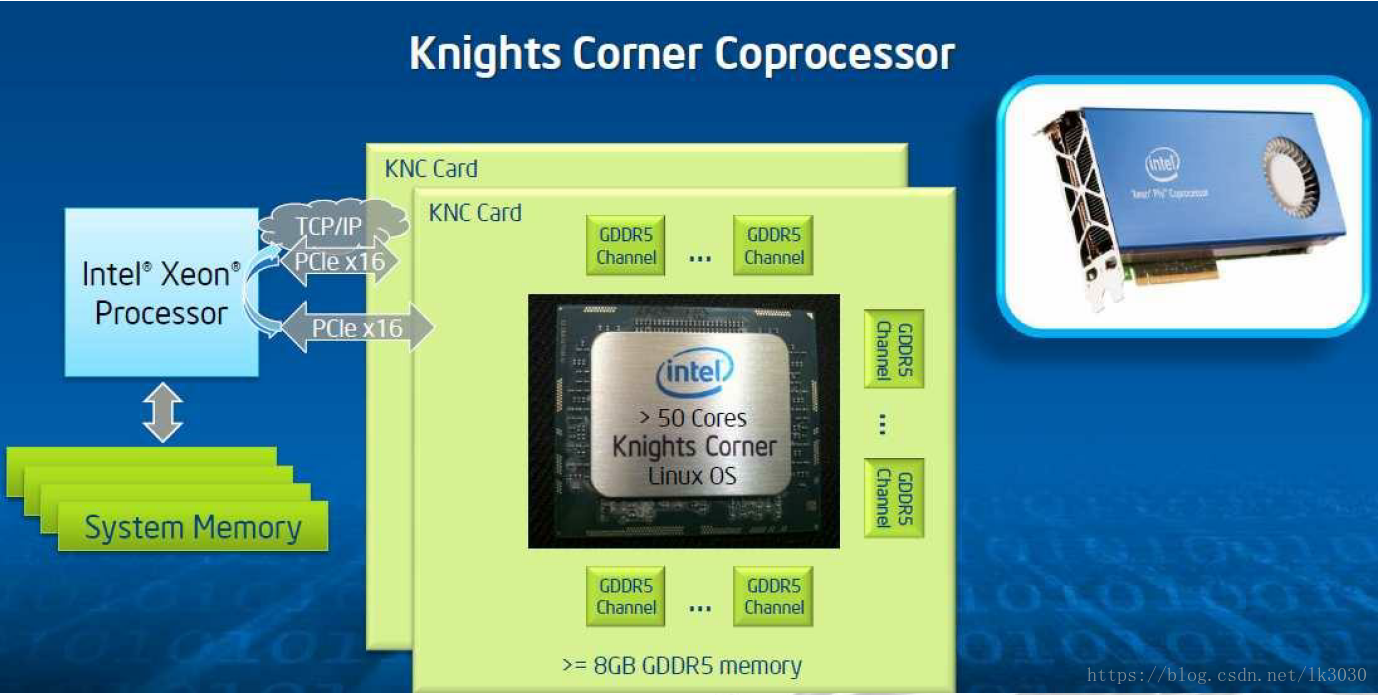
MIC Core的组成:
- 单芯片57~61Cores,每个Core有4个硬件线程,硬件线程调度器将4个硬件线程以顺序轮询方式并发执行。
- 指令译码/发射器。
- Pipe0和Pipe1执行管线。
- VPU单元:(Vector Permutate Unit)512位向量处理单元,一次可处理16个单精度计算。
- X86单元:x86架构的标量微处理器单元,与Xeon共享代码,编程简单,开发周期短,工具链通用。
- 2级Cache
- 2级TLB(Translation Lookaside Buffer)转换检测缓冲区,用于改进虚拟地址到物理地址转换速度的缓存
- Cache未命中处理单元
- CRI:内核与片上环形总线的链接接口
- 片上软件实现TCP/UDP IP :单卡 ≈ 独立的MPI节点/进程
MIC性能:
- 单核:计算能力较 Core core差,较GPU core强
- 单卡:双精度 > 1TFLOPS (Floating-point operations per second:每秒浮点运算次数)
片上对称多处理器(Symmetric Multiprocessor on-a-chip,SMP)是对Intel MIC架构的准确描述方式,Intel Xeon Phi(至强融核)协处理器是基于Intel MIC架构的首款产品。协处理器卡的核心是Intel Xeon Phi协处理器芯片,由61个IA(Intel Architecture)核组成,这些核执行IA指令集,每个核有4个完全相同的硬件线程。
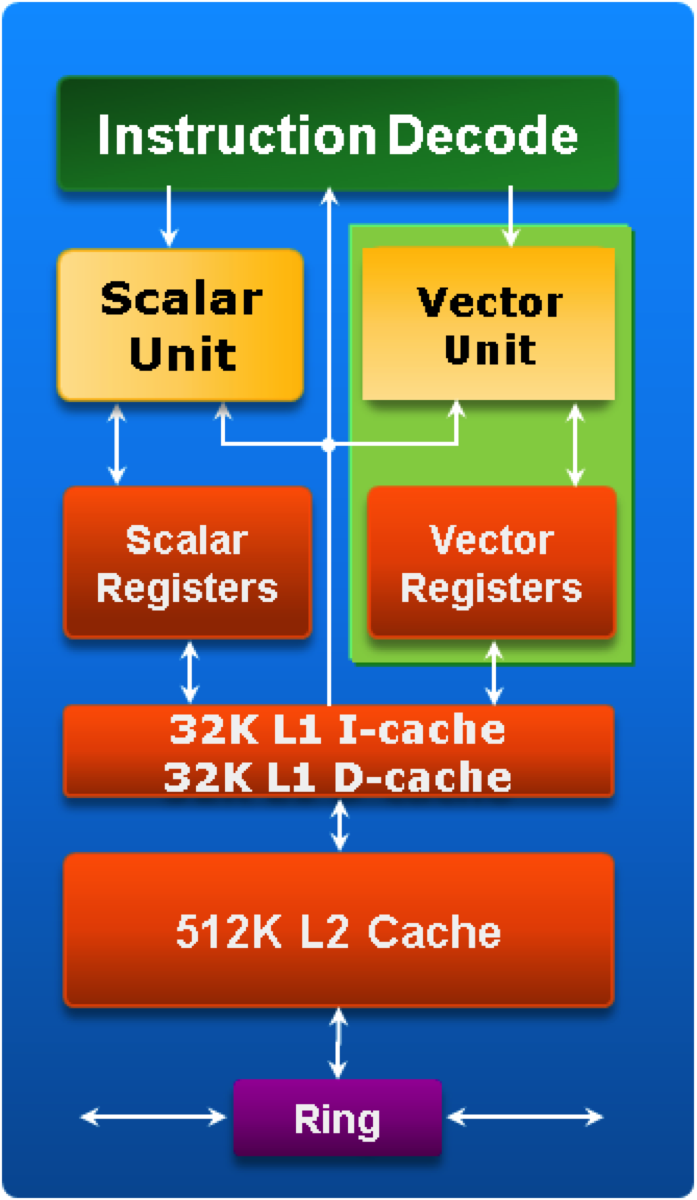
MIC每个核的二级缓存组织包括:
- 一级缓存:32KB数据缓存、32KB指令缓存
- 二级缓存:512KB私有(本地)缓存
512KB的私有二级缓存总共构成了容量可达30.5MB的片上缓存。所有的二级缓存由全局分布的 (global-distributed) 标签目录保持完全一致。
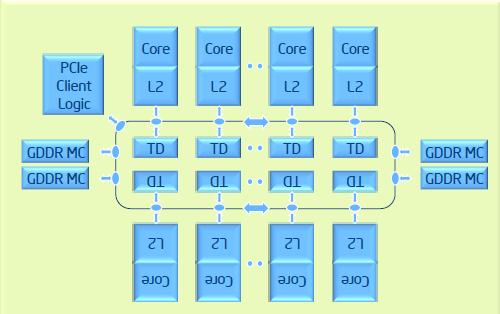
内存控制器和 PCIe 客户端逻辑分别向协处理器上的 GDDR5 内存和 PCIe 总线提供一种直接接口。所有这些组件都由环形互连连接在一起,被多个核共享的数据将会被复制到需要使用该数据的核所对应的本地二级缓存中,所以,如果每个核都以完美的同步方式共享相同的代码和数据,则有效的二级缓存容量只有512KB。所以,二级缓存的实际可用容量大小与代码和数据在核与线程间的共享情况密切相关。
协处理器同时支持4KB(标准)、64KB(非标准)和2MB(超大,标准)页面大小的虚拟内存管理。较小页面的访问会带来总体内存映射空间变小以及最快的访问速度。4KB的页面大小长期以来是Linux的标准设置。64KB的页面大小在现有的微处理器并不常见,同时需要Linux核心的特殊支持。2MB大型存储页支持一般是可用的,但是应用程序或运行环境需要经过一些特殊的修改。在访问大数据集和数组时,使用超大页面能够通过提高TLB命中率提升应用性能,这点在应用优化时需要额外注意。
协处理器芯片的每一个核都包含有一个512位宽的SIMD向量处理单元(VPU),并设计了通信向量化指令集。VPU每个时钟周期可同时处理16个单精度(32bit)或8个双精度(64bit)浮点运算。另外,还包含一个扩展数学单元(EMU,Extended Math Unit)用来实现单精度的超越函数指令集,即通过硬件实现指数、对数、倒数和倒数平方根等常用数学运算。
Intel Xeon Phi协处理器主要针对高度并行化的负载优化,同时支持多种常用的编程语言、编程模式和编程工具。除了大量的处理核心,协处理器还包括提供了并行功能的向量处理器单元。此外,协处理器的PCIe接口、DMA、电源管理、传感器以及散热监控等均有各自的设计特点。
软件架构
系统:
- 片上uOS,基于linux
语言:
- 支持C、C++、Fortran
支持多种并行模型
- OpenMP、pthread、Clik
- MPI,片上支持TCP/IP,MIC卡可作为独立节点
Intel工具链都支持MIC:
- Intel parallel studio
- 片上软件实现TCP/UDP,IP
- MIC卡自动检测识别,增强软件自适应性
开发流程
- CPU单线程=> CPU多线程(OpenMP) => MIC Offload&Opt => MIC+CPU协同计算
MIC的µOS建立的基本执行环境,是其他软件栈的基础。MIC的µOS是基于标准的Linux内核源码。MIC基于Linux的µOS是最小化的,是嵌入式Linux环境通过Linux标准基础(LSB,Linux Standard Base)核心库一直到MIC架构的产物,这也是个未签名的操作系统。µOS提供一些典型的能力,如:进程/任务创建、时序安排、内存管理等。µOS也提供设置、电源和服务器的管理能力。
Intel MPSS提供驱动程序,将PCIe总线映射成一个网络栈中的以太网设备,虚拟化TCP/IP堆栈。系统可以配置桥接TCP/IP网络于所连接的其他网络通信。使用户可以将其作为网络节点直接使用ssh连接到协处理器上。
编程模型
MIC拥有较为灵活的编程方式,MIC卡可以作为一个协处理器存在,也可以被看做是一个独立的节点。host端与MIC端的关系可以组合成一下5种关系:
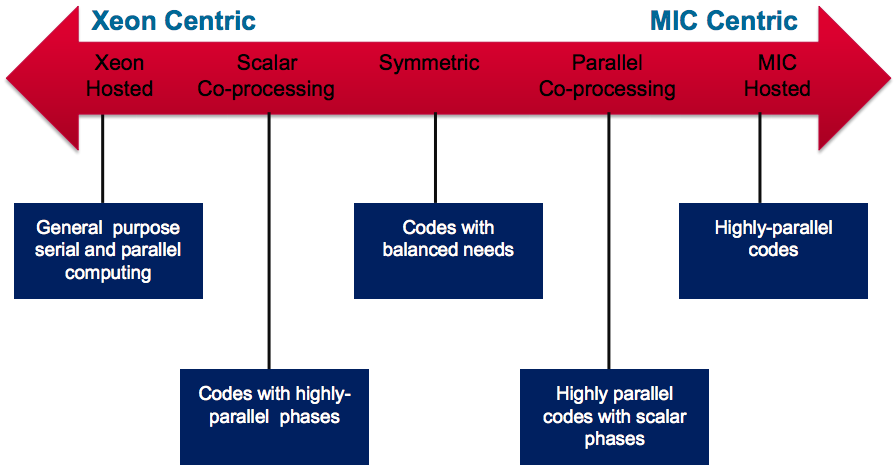
而实际中的的应用模式通常不会这样复杂,常用的模式:
Native模式,即MIC本地模式:
- 手动将二进制文件传到MIC卡上并运行。
- 所有负载均在MIC端,通常使用于高并行计算程序,程序直接在MIC执行。
- 应用移植来说难度较小,客观限制较多,如内存,第三方库函数等,提升的性能效果也比较有限。
offload模式:
- 从CPU端运行程序,主函数由host发起。
- 通过引语方式,将高度并行的计算部分标示为MIC端代码,分载到MIC端,由协处理器完成计算后返回结果。
- 语法类似于OpenMP,简单。
- 集调用设备、开辟空间、数据传输于一身。
- 有更为明显的性能提升效果,缺点是移植较为复杂,特别是对于一些数据结构、算法逻辑较为复杂的代码,甚至需要完全重写。
对称模式:
- Host-MIC对称模式
- MPI模式
MIC Offload模式
Offload+OpenMP :
- Offload:空间开辟、数据传输(in&out)
- OpenMP:实现多线程并行
- Offload与OpenMP结合,使代码在MIC卡上并行执行
MIC Offload数据传输模式(难点&耗时) :
- 只能传输连续地址空间数据块
- In:copy CPU to MIC
- Out:copy MIC to CPU
- Inout:copy in&out both
- Nocopy:the Data is already local to MIC
MIC Native模式编程
- 不用在OpenMP基础上添加任何代码
- 编译 icc –openmp –mmic –o OnShipTest piTest.c
- 为MIC卡配置IP,并写入/etc/hosts
- 上传到MIC卡上
• micput mic0 OnShipTest /tmp(可执行程序)
• micput mic0 libiomp5.so /tmp(openmp库)
• 正式发布:使用scp等方式,或直接把MIC卡显存通过NFS共享至host - 登录MIC节点 ssh mic0
- 配置环境
• cd /tmp
• export LD_LIBRARY_PATH=/tmp - 执行程序 ./ OnShipTest
MIC MPI对称模式编程
- 编程方法同Native模式
- 只是使CPU、MIC同时参与运算
- CPU、MIC间以MPI交互
- 编译同Native模式
- 执行模式与普通CPU MPI应用类似,将MIC卡视作一个节点
MIC 编译
- Intel编译器:icc/icpc/ifort
- CPU+MIC:default or -offload-build选项
- CPU only:-no-offload选项
编程实例
- 计算PI实例:piTest.c
- 编译:
• icc –openmp –o piTest piTest.c(默认打开offload)
• icc –openmp –offload-build –o piTest piTest.c
• icc –openmp –no-offload –o piTest piTest.c - 运行:./piTest
- 查看是否跑在MIC上
• export H_TRACE = 1(CPU/MIC基本信息)
• export H_TRACE = 2(更详细信息) - 查看MIC运行时间
• export H_TIME=2 - MIC上加打印
MIC平台HPC应用开发策略
- 适应MIC的应用特征分析
- MIC众核并行算法设计
- MIC应用高效编程
- MIC应用效率与可扩展性能提升
MIC程序快速开发方法
分析原有CPU程序:
- 热点定位
- 并行性、向量化、内存分析
MIC平台开发 :
- CPU平台OpenMP版本开发
- 基于CPU平台的MIC线程扩展
- 单节点下CPU+MICs异构协同计算
- MIC集群大规模运算
MIC平台优化 :
- 向量化优化
- 内存优化(L1、L2 Cache优化)、IO优化
适应MIC的应用特征分析
移植可行性分析 :
- 是否拥有全部或核心源代码
- 所使用的编程语言
- 是否可以用Intel编译器编译
性能可行性分析 :
- 并行度
- 线程扩展性
- CPU利用率
- 向量化
- 通信分析
- 内存带宽
- 热点比例
MIC并行算法设计
- 并行粒度与并行度 : MIC百级以上线程+ 指令级并行( 512位向量化)
- 线程的可扩展性:是否有数据有依赖或部分依赖造成线程同步等待
- 大规模数据的分块处理:避免GPU或MIC的显存空间制约,避免过多临时中间数据的产生 。
- 计算与访存比
- 访存方式:连续or跳跃
MIC应用高效编程
CPU+MIC异构:
- 基于X86指令架构下异构模式
- X86多核+X86众核
- 通用编程思路
• MPI
• OpenMP
• OpenCL
MIC编程方式 :
- Native方式
- Offload方式
- Symmetric方式
• GTC
• Grapes
| 编程模式 | 编程方式 | 挑战 |
|---|---|---|
| Native | • 只编译:-mmic • 编程周期短 | • 只适用单卡、内存占用小的应用 • 性能受限串行部分比例 |
| Offload | • 类似OpenMP引语编程 • 编程简单 | 大型应用开发周期相对较长 |
| Symmetric | • 只编译:-mmic • 编程周期短 | • 第三方库的编译支持 • MPI进程通信开销 |














 4263
4263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









