







正则表达式(regular expressiong)是用一种形式化语法描述的文本匹配模式。模式被解释为一组指令,然后会执行这组指令,以一个字符串作为输入,生成一个匹配的字迹或者原字符串的修改版本。“正则表达式”一词在讨论中通常会简写为“regex”或者“regexp”。表达式可以包括字面文字匹配、重复、模式组、分支以及其他复杂的规则。对于很多解析问题,用正则表达式解决会比创建特殊用途的词法分析器和语法分析器容易。
正则表达式通常在涉及大量文本处理的应用中使用。例如,在开发人员使用的文本编辑程序中,常用正则表达式作为搜索模式。另外,正则表达式还是UNIX命令行工具的一个不可或缺的部分。如sed、grep和awk。很多编程语言都在语法中包括对正则表达式的支持,如Perl、Ruby、Awk和TCL。另外一些语言(如C、C++和Python)通过扩展库来对正则表达式支持。Python的re模块中使用的语法以Perl所用的正则表达式语法为基础,并提供了一些特定于Python的改进。
1. 查找文本中的模式(re.search(p,text))
re常见的用法就是搜索文本中的模式。search()函数取模式和要扫描的文本为输入,如果找到这个模式,则返回Match对象,如果未找到,search()返回为None。每个Match对象包含有关匹配的信息,包括原输入字符串、使用的正则表达式,以及模式在原字符串中出现的位置。如果Match对象为M,则M.re.pattern保存的正则表达式,M.string则为匹配的字符串,M.start()和M.end()则为匹配到的首位位置。
Found "this" in:
"Does this text match the pattern?"
from 5 to 9 ("this")
"Does this text match the pattern?"
from 5 to 9 ("this")
match对象
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
属性:
- string: 匹配时使用的文本。
- re: 匹配时使用的Pattern对象。
- pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
- lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
- group([group1, …]): 获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
- groups([default]): 以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
- groupdict([default]): 返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。
- start([group]): 返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。
- end([group]): 返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。
- span([group]): 返回(start(group), end(group))。
- expand(template): 将匹配到的分组代入template中然后返回。template中可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。\id与\g<id>是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符'0',只能使用\g<1>0。
2. 编译表达式(re.compile(p))
re包含一些模块机函数,用于处理作为文本字符串的正则表达式,不过对于频繁使用的表达式,编译这些表达式更为高效。compile()函数会把一个表达式字符串转换为一个RegexObject。
模块级函数会维护已编译表达式的一个缓存。不过,这个缓存的大小是有极限的,直接用已编译表达式可以避免缓存查找开销。使用已编译表达式的另一个好处是,通过在加载模块时预编译所有表达式,可以把编译工作转到应用开始时,而不是当程序响应一个用户动作时才进行编译。对于一个编译好的表达式M,M.pattern保存正则表达式。结果为:
Text: 'Does this text match the pattern?'
Seeking "this" -> match!
Seeking "that" -> no match
Seeking "this" -> match!
Seeking "that" -> no match
3. 多重匹配(re.findall(p,text))
findall()函数会返回输入中与模式匹配而不重叠的所有子串。
执行结果为:['abb', 'a', 'a', 'abbb', 'a', 'a', 'a', 'a']
finditer()会返回一个迭代器,它将生成Match实例,而不像findall()返回字符串。
这个例子找到了ab出现了两次,Match实例显示出了他们在原字符串中的位置
Found 'ab' at 0:2
Found 'ab' at 5:7
4. 模式语法
正则表达式支持强大的模式匹配,模式可以重复,可以锚定到输入中的逻辑位置,还可以采用紧凑形式表示而不需要在模式中提过每一个字面量字符。使用所有这些特性时,需要结合字面量文本值和元字符(metacharacter),元字符是re实现正则表达式模式语法的一部分。
重复与非贪婪模式
模式中有5种表达重复的方式。如果模式后面的跟有原字符
*,这个模式会被匹配0次或者多次。如果是
+,那么这个模式至少出现1次。使用“
?”则表示要出现0或者1次。如果希望出现特定的次数,需要在模式后面使用
{m},这里的m是模式匹配需要重复的次数。最后,如果如果允许重复次数在可变范围,那么可以使用
{m,n},这里的m是重复的最小次数,n是重复的最大次数。如果省略n,表示至少出现m次,且无上限。
正常情况下,处理重复指令时,re匹配模式会利用(consume)尽可能多的输入。这种所谓的“贪心”行为可能导致单个匹配减少,或者匹配中包含了多余原先预定的输入文本。
在重复指令后面加上“?”可以关闭这种贪心行为。
字符集
字符集(character set)是一组字符,包含可以与模式中相应位置匹配的所有字符。例如:[ab]可以匹配a或者b。^在字符集的首位时,表否定,即不包含字符集中的字符。随着字符集的变大,可以使用一种更紧凑的模式,利用字符区间来定义一个字符集,其中包含一个起点和一个终点之间的所有连续的字符。如:[a-zA-Z0-9]表示匹配所有大小写字母和数字的字符。元字符“.”(点号)指模式应当匹配位置的任意单个字符。
转义码
还有一种更为紧凑的表示,可以对一些预定义的字符集使用转义码。re可以识别的转义码表示:

转义字符通过在该字符前面加一个反斜杠(\)前缀表示。遗憾的是,正常的Python字符串中反斜线自身也必须转义,这就会导致表达式很难阅读。通过使用“原始”(raw)字符串(在字面值前面加一个前缀r来创建),可以消除这个问题,并维持可读性。如:
要匹配隶属于正则表达式中的字符,需要对搜索模式中的字符进行转义。如下面的例子中的模式对反斜线和加号字符进行了转义,这两个字符在正则表达式中都有特殊含义。
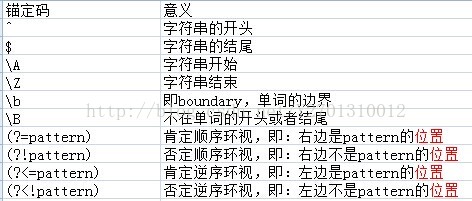
如果已经提前知道只要搜索整个输入的一个子集,可以告诉re限制搜索范围,从而进一步约束正则表达式匹配。例如,如果模式必须出现在输入的最前面,那么使用match()而非seach()会锚定搜索,而不必在搜索中显式地加一个锚。
结果为:
Text : This is some text -- with punctuation.
Pattern : is
Match : None
Search : <_sre.SRE_Match object at 0xb7626090>
Pattern : is
Match : None
Search : <_sre.SRE_Match object at 0xb7626090>
已编译正则表达式的search()方法还可接受可选的start和end位置参数,将搜索限制在输入的一个子串上。
5 : 6 = "is"
结果只能匹配到子串5-7位置的is:
Text: This is some text isgood-- with punctuation.
5 : 6 = "is"
6. 用组解析匹配(groups())
匹配组
为模式增加组(group)可以隔离匹配文本的各个部分,近一步可以扩展这些功能来创建一个解析工具。通过将模式包围在小括号中来分组。
任何完整的表达式都可以转换为组,并嵌套在一个更大的表达式中。所有重复修饰符可以应用到整个组作为一个整体,这就要求重复整个组模式。要访问一个模式中单个组匹配的子串,可以使用Match对象的group()方法。Match.grups()会按照表达式中与字符串匹配的顺序返回一个字符串序列。
This is some text -- with punctuation.
Pattern '^(\\w+)' (word at start of string)
('This',)
Pattern '(\\w+)\\S*$' (word at end, with optional punctuation)
('punctuation',)
Pattern '(\\bt\\w+)\\W+(\\w+)' (word starting with t, another word)
('text', 'with')
Pattern '(\\w+t)\\b' (word ending with t)
('text',)
Pattern '^(\\w+)' (word at start of string)
('This',)
Pattern '(\\w+)\\S*$' (word at end, with optional punctuation)
('punctuation',)
Pattern '(\\bt\\w+)\\W+(\\w+)' (word starting with t, another word)
('text', 'with')
Pattern '(\\w+t)\\b' (word ending with t)
('text',)
使用group()可以得到某个组的匹配。如果使用分组来查找字符串的各部分,不过结果中并不需要某些与组匹配的部分,此时group()会很有用。
其中match.group(0)表示整个匹配,match.group(1)表示第一个组,即(\bt\w+),而match.group(2)当然就表示第二个组,即:(\w+),依次类推,结果为:
Input text : This is some text -- with punctuation
Pattern : (\bt\w+)\W+(\w+)
Entir match : text -- with
Word starting with "t": text
Word after "t" word : with
Pattern : (\bt\w+)\W+(\w+)
Entir match : text -- with
Word starting with "t": text
Word after "t" word : with
命名组((?P<name>pattern))
python对基本分组语法做了扩展,增加了命名组()。通过使用名字来指示组,这样以后就可以更容易地修改模式,而不必同时修改使用了匹配结果的代码。要设置一个组的名字,可以使用以下语法:
(?P<name>pattern),要获得命名组可以用(?P=name)
使用groupdict()可以获得一个字典,它将组名映射到匹配的子串。groups()返回的有序序列还包括命名模式。
Text is some text -- with punctuation.
Matching "^(?P<first_word>\w+)"
('Text',)
{'first_word': 'Text'}
Matching "(?P<last_word>\w+)\S*$"
('punctuation',)
{'last_word': 'punctuation'}
Matching "(?P<t_word>\bt\w+)\W+(?P<other_word>\w+)"
('text', 'with')
{'other_word': 'with', 't_word': 'text'}
Matching "(?P<ends_with_t>\w+t)\b"
('Text',)
{'ends_with_t': 'Text'}
Matching "^(?P<first_word>\w+)"
('Text',)
{'first_word': 'Text'}
Matching "(?P<last_word>\w+)\S*$"
('punctuation',)
{'last_word': 'punctuation'}
Matching "(?P<t_word>\bt\w+)\W+(?P<other_word>\w+)"
('text', 'with')
{'other_word': 'with', 't_word': 'text'}
Matching "(?P<ends_with_t>\w+t)\b"
('Text',)
{'ends_with_t': 'Text'}
反向引用
对于捕获组和非捕获组,还可以用反向引用。如匹配开头的连续两个相同的单词:对于非命名组:^(\w+)\W(\1),对于命名组:^(?<word>\w+)\W(?P=word)
候选模式((patter1)|(pattern2))
组对于制定候选模式也很有用。可以使用管道符号(|)指示应当匹配某一个或者另一个模式。不过要仔细考虑管道的放置位置。如((a+) |(b+))可以匹配1-n个连续的a字符串或者1-n个连续的b字符串,而(a|b)+则表示匹配的字符串中每个字符要么是a要么是b。
非捕获组((?:pattern))
我们知道在
匹配单个组中,得到每个组的匹配字符串是M.group(1),M.group(2)等等,如匹配字符”8000¥“时,分别要得到”8000“和”¥“,则模式可以为:(\d+)(¥),用模式M.group(1)得到”8000“,用M.group(2)得到”¥“。但是如果是字符串”8000.56¥“,现在只想得到整数部分”8000“和”¥“,而又只想改变正则不想改变输出M.group(1)和M.group(2),这就要创建一个非捕获组,将字符串中的小数点和小数部分加到非捕获组中即可,非捕获组的语法是(?:pattern),表示仅用于分组,不提取文本。
这样还是可以用M.group(1)和M.group(2)作为输出,结果同样也是”8000“和”¥“
7. 搜索选项
利用选项标志可以改变匹配引擎处理表达式的方式。可以使用或(OR)操作结合这些标志,然后传递至compile()、search()、match()以及其他可以接受匹配模式完成搜索的函数。
有两个标志会影响如何在多行输入中进行搜索:MULTILINE和DOTALL。MULTILINE标志会控制模式匹配代码如何对包含换行符的文本处理锚定指令。当打开多行模式,除了整个字符串外,还要在每一行的开头和结尾应用^和$的锚定规则。
MULTILINE会将"\n"解释为一个换行,而 默认情况下只将其解释为一个空白字符。执行结果为:
Text: 'This is some text -- with puncturation.\nA second line.'
Pattern:
(^\w+)|(\w+\S*$)
Single Line:
('This', '')
('', 'line.')
MULTILINE :
('This', '')
('', 'puncturation.')
('A', '')
('', 'line.')
DOTALL也是一个与多行文本有关的标志,正常情况下,点字符(.)可以与输入文本中除了换行符之外的所有其他字符匹配。这个标志则
允许点字符还可以匹配换行符。
如果没有这个标志,输入文本会与模式单独匹配。增加了这个标志后,则会利用整个字符串。
Text:
'This is some text -- with punctuation.\nA second line.'
Pattern:
'.+'
No newlines :
'This is some text -- with punctuation.'
'A second line.'
Dotall :
'This is some text -- with punctuation.\nA second line.'
Unicode
在Python2中,str对象使用的是ASCII字符集,而且正则表达式会处理假设模式和输入文本都是ASCII字符。之前描述的转义码就默认使用ASCII来定义。这些假设意味着模式\w+会匹配单词person而不会匹配单词pérson
详细表达式(re.VERBOSE)
随着表达式变得越来越复杂,紧凑格式的正则表达式语法可能会成为障碍。随着表达式中组数的增加,需要做更多的工作来明确为什么需要各个元素以及表达式的各个部分究竟如何交互。使用组名有助于缓解这些问题,不过一种更好的方法是使用详细表达式,它允许在模式中嵌入注释和额外的空白符。
例如,可以用来验证Email地址的模式来说明详细模式能够更容易地处理正则表达式。
类似于其他编程语言,能够在详细正则表达式中插入注释有利于增强可读性和可维护性。执行结果为:
Candidate: first.last@example.com
Name: None
Email: first.last@example.com
Candidate: first.last+category@gmail.com
Name: None
Email: first.last+category@gmail.com
Candidate: valid-address@mail.example.com
Name: None
Email: valid-address@mail.example.com
Candidate: not-valid@example.foo
No match
Candidate: First Last <first.last@example.com>
Name: First Last
Email: first.last@example.com
Candidate: No Brackets first.last@example.com
Name: None
Email: first.last@example.com
Candidate: First Last
No match
Candidate: First Middle Last <first.last@example.com>
Name: First Middle Last
Email: first.last@example.com
Candidate: Fist M. Last <first.last@example.com>
Name: Fist M. Last
Email: first.last@example.com
Candidate: <first.last@example.com>
Name: None
Email: first.last@example.com
Name: None
Email: first.last@example.com
Candidate: first.last+category@gmail.com
Name: None
Email: first.last+category@gmail.com
Candidate: valid-address@mail.example.com
Name: None
Email: valid-address@mail.example.com
Candidate: not-valid@example.foo
No match
Candidate: First Last <first.last@example.com>
Name: First Last
Email: first.last@example.com
Candidate: No Brackets first.last@example.com
Name: None
Email: first.last@example.com
Candidate: First Last
No match
Candidate: First Middle Last <first.last@example.com>
Name: First Middle Last
Email: first.last@example.com
Candidate: Fist M. Last <first.last@example.com>
Name: Fist M. Last
Email: first.last@example.com
Candidate: <first.last@example.com>
Name: None
Email: first.last@example.com
模式中嵌入标志
如果在编译表达式时不能增加标志,如将模式作为参数传入一个将在以后编译该模式的库函数时,可以把标志嵌入到表达式字符串本身。例如,要启用不区分大小写匹配,可以
在表达式开头增加(?i),如下例的pattern会匹配已T或者t开头的单词:
| 标志 | 缩写 |
| IGNORECASE | i |
| MULTLINE | m |
| DOTALL | s |
| UNICODE | u |
| VERBOSE | x |
可以把嵌入标志放在同一组中结合使用。例如,(?imu)会打开相应的选项,支持多行Unicode字符不区分大小写的匹配。
8. 自引用表达式
匹配的值还可以用在表达式后面的部分。例如,前面的Email例子可以更新为由人名和姓组成的地址,为此要包含这组的反向引用,要达到这个目的,最容易地办法是使用\num按id编号引用先前匹配的组。
尽管这个方法很简单,不过数字id创建反向引用有两个缺点。从实用角度讲,当表达式改变时,这个组就得重新编号,每个引用可能都需要更新。另一个缺点是,采用这种方法只能创建99个引用,因为如果id编号为3位,就会解释为一个八进制字符值而不是一个引用。另一方面,如果一个表达式能超过99个组,还会产生更严重的维护问题。Python的表达式解析器包括一个扩展,可以使用
(?P=name)指示表达式中先前匹配的一个命名组的值。
在表达式中使用反向引用还有另外一种机制,即根据前一组是否匹配来选择不同的模式。可以修正这个Email模式,使得如果出现名字就需要匹配尖括号,如果只有Email本身就不需要尖括号。
查看一个组是否匹配的语法是(?(id)yes-expressiong|no-expression),这里id是组名或者编号,yes-expression是组有值时使用的模式,no-expression则是组没有值时使用的模式。
这个版本的Email地址解析用了两个测试。如果name组匹配,则当前断言要求两个尖括号都出现,并建立brackets组。如果name不匹配,这个断言则会要求余下的文本不能用尖括号括起来。接下来,如果设置了brackets组,具体的模式匹配代码会借助字面量模式利用输入中的尖括号;否则,它会利用所有空格。
9. 用模式修改字符串(sub())
除了文本搜索以外,re还支持正则表达式作为搜索机制来修改文本,而且替换可以引用正则表达式中的匹配组作为替换文本的一部分。使用sub()可以将一个模式的所有出现替换为另一个字符串
可以使用后向引用的\num语法插入与模式匹配的文本的引用。
Text: Make this **bold**. This **too**.
Bold: Make this <b>bold</b>. This <b>too</b>.
要在替换中使用命名组,可以使用语法
\g<name>
Text: Make this **bold**. This **too**.
Bold: Make this <b>bold</b>. This <b>too</b>.
Bold: Make this <b>bold</b>. This <b>too</b>.
向count传入一个值可以限制完成的替换数。
Text: Make this **bold**. This **too**.
Bold: Make this <b>bold</b>. This **too**.
Bold: Make this <b>bold</b>. This **too**.
subn()的工作原理与sub()很相似,只是它会返回修改后的字符串和完成的替换次数
10. 利用模式拆分
str.split()是分解字符串完成解析的做常用方法之一。不过,它只支持使用字面值作为分隔符。有时,如果输入没有一致的格式,就需要又一个正则表达式。例如,很多纯文本标记语言都把段落分隔符定义为两个或者多个换行符(\n)。在这种情况下,就不能使用str.split(),因为这个定义中提到了“或多个”。
使用findall()标识段落有一种策略,使用类似(.+?)\n{2,}的模式。
0 'Paragraph one\non two lines.'
1 'Paragraph two.'
可以扩展这个模式,指出段落以两个或者多个换行符结束或者以输入末尾作为结束,就能修正这个问题,但会让模式更为复杂。可以转向使用 re.split()而不是re.findall(),就能自动处理边界,并保证模式更简单。
1 'Paragraph two.'
可以扩展这个模式,指出段落以两个或者多个换行符结束或者以输入末尾作为结束,就能修正这个问题,但会让模式更为复杂。可以转向使用 re.split()而不是re.findall(),就能自动处理边界,并保证模式更简单。
0 'Paragraph one\non two lines.'
1 'Paragraph two.'
2 'Paragraph three.\n'
0 'one'
1 'two'
2 'three'
3 'four'
4 ''
可以将表达式包围在小括号里来定义一个组,这使得split()的工作方式更类似于str.partition(),因为它返回分隔符值以及字符串的其他部分。
0 'Paragraph one\non two lines.'
1 '\n\n'
2 'Paragraph two.'
3 '\n\n\n'
4 'Paragraph three.\n'
0 'one'
1 '1'
2 'two'
3 '2'
4 'three'
5 '3'
6 'four'
7 '4'
8 ''
如果要用圆括号但又不想分隔符在结果中,那么可以使用非捕获组(:?):
1 '\n\n'
2 'Paragraph two.'
3 '\n\n\n'
4 'Paragraph three.\n'
0 'one'
1 '1'
2 'two'
3 '2'
4 'three'
5 '3'
6 'four'
7 '4'
8 ''
如果要用圆括号但又不想分隔符在结果中,那么可以使用非捕获组(:?):
结果为:
result1:
['one', 'two', 'three', 'four', 'five', 'six', 'seven']
result2:
['one', ' ', 'two', ';', 'three', ',', 'four', ',', 'five', ',', 'six', ',', 'seven']
['one', 'two', 'three', 'four', 'five', 'six', 'seven']
[' ', ';', ',', ',', ',', ',', '']
one two;three,four,five,six,seven
result3:
['one', ' ', 'two', ';', 'three', ',', 'four', ',', 'five', ',', 'six', ',', 'seven']
['one', 'two', 'three', 'four', 'five', 'six', 'seven']
['one', 'two', 'three', 'four', 'five', 'six', 'seven']
result2:
['one', ' ', 'two', ';', 'three', ',', 'four', ',', 'five', ',', 'six', ',', 'seven']
['one', 'two', 'three', 'four', 'five', 'six', 'seven']
[' ', ';', ',', ',', ',', ',', '']
one two;three,four,five,six,seven
result3:
['one', ' ', 'two', ';', 'three', ',', 'four', ',', 'five', ',', 'six', ',', 'seven']
['one', 'two', 'three', 'four', 'five', 'six', 'seven']















 160
160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









