









Database Management Systems
Part 5: Transaction Management
Chapter 16. Overview of transaction management
transaction: any one execution of a user program in a DBMS as a series of read and write operations
ACID: atomicity: either all actions of a transaction are carried out or none are; consistency; isolation: transactions are isolated/protected from the effects of concurrently scheduling other transactions; durability
users are responsible for ensuring transaction consistency (no errors in user program's logic) --> database consistency
isolation is ensured by guaranteeing that net effect of interleaved transactions is identical to executing all transactions one after the other in some serial order (but no guarantees about which order is effectively chosen)
transactions can be incomplete for three reasons: (1) aborted or terminated unsuccessfully (2) system crash (3) transaction encounter unexpected situation and decide to abort
recovery manager: atomicity is ensured by undoing the actions of incomplete transactions --> log <-- ensure durability (survive system crashes and media failures)
a transaction is seen by DBMS as a series/list of actions: reads and writes of database objects. each transaction must specify as its final action either commit or abort (terminate and undo all actions carried out thus far).
assumptions: transactions interact with each other only via database read and write operations; a database is a fixed collection of independent objects (relaxed later in this chapter)
schedule: a list of actions (read, write, abort, commit) from a set of transactions, and the order in which two actions of a transaction T appear in a schedule must be the same as the order in which they appear in T
motivation for concurrent execution: (1) overlapping I/O and cpu --> reduce idle time, increase system throughput (average number of transactions completed in a given time); (2) interleave short with long transaction --> improve response time (average time taken to complete a transaction)
serializable schedule: any serial order is acceptable
Conflicts:
reading uncommitted data (WR conflicts): dirty read
unrepeatable reads (RW conflicts)
overwriting uncommitted data (WW conflicts): blind write --> lost update
serializable schedule over a set S of transactions is a schedule whose effect on any consistent database instance is guaranteed to be identical to that of some complete serial schedule over the set of committed transactions in S
if T2 not committed, cascading abort of T1 and also abort T2 --> if T2 already committed, such a schedule is unrecoverable
recoverable schedule: transactions commit only after all transactions whose changes they read commit --> avoid cascading aborts
another potential problem: T2 overwrites object A that has been modified by T1, and T1 aborts --> restore value, T2's change lost if even T2 commit <-- prevent by Strict 2PL
DBMS must ensure only serializable, recoverable schedules are allowed and no actions of committed transactions are lost while undoing aborted transactions <-- locking protocol allows only safe interleaving of transactions
strict two-phase locking: (1) if a transaction T wants to read (modify) an object, it first requests a shared (exclusive) lock on the object; (2) all locks held by a transaction are released when the transaction is completed
deadlock --> DBMS must prevent or detect and resolve deadlocks: e.g. timeout and abort
performance of locking: blocking and aborting --> lock thrashing: when adding another active transaction actually reduces throughput
increase throughput: (1) lock the smallest sized objects possible (2) reduce the time that transaction hold locks (3) reduce hot spots
transaction support in SQL: savepoint, rollback to savepoint; chained transactions
granularity: row-level locks instead of entire table
phantom problem: a transaction retrieves a collection of objects twice and sees different results, even though it does not modify any of these tuples itself <-- prevent by locking entire table or locking indexes
transaction characteristics: access mode (READ ONLY, READ WRITE), isolation level (READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, SERIALIZABLE)

serializable: obtain locks before reading or writing, including locks on sets of objects that it requires to be unchanged, and holds until the end
repeatable read: lock only individual objects, not set of objects (does not do index locking)
read committed: obtain shared locks before reading but release immediatly
read uncommitted: does not obtain shared locks before reading (such transaction is required to have access mode of READ ONLY)
most transactions use SERIALIZABLE isolation level, but e.g. a statistical query (average) can be run at the READ COMMITTED or even READ UNCOMMITTED level
crash recovery:
steal: if a frame is dirty and chosen for replacement, the page it contains in buffer pool is written to disk even if the modifying transaction is still alive
force: pages in the buffer pool that are modified by a transaction are forced to disk when transaction commits
simplest (not realistic) recovery manager implementation: use a buffer manager with no-steal, force approach: no steal --> no need to undo aborted transaction; force --> no need to redo committed transaction
most systems use steal, no-force approach
recovery steps: a log of all modifications to the database is saved on stable storage (implemented by maintaining multiple copies of information on nonvolatile storage devices)
write-ahead log (WAL): log entries are written to stable storage before change is made
checkpointing --> reduce time taken to recover from a crash
ARIES (work with steal, no-force): analysis, redo, undo
rollback (== undo): all log records for a given transaction are organized in a linked list and can be efficiently accessed in reverse order
Chapter 17. Concurrency control
conflict actions: if they operate on the same data object and at least one of them is write --> outcome of a schedule depends only on the order of conflicting operations
conflict serializable: if it is conflict equivalent to some serial schedule (every pair of conflicting actions ordered in the same way) --> serializable; but some serializable schedules are not conflict serializable

precedence graph (serializability graph): a node for each committed transaction; an arc from Ti to Tj if action of Ti precedes and conflicts with one of Tj's actions
acyclic precedence graph == conflict serializable (equivalent serial schedule is given by any topological sort)
strict 2PL ensures the precedence graph for any schedule that it allows is acyclic
(nonstrict) two-phase locking: second rule relaxed --> (2) a transaction cannot request additional locks once it releases any locks (growing phase + shrinking phase)
nonstrict 2PL still ensures acyclicity: equivalent serial order is given by the order in which transactions enter their shrinking phase
strict 2PL --> improve over 2PL by guaranteeing every allowed schedule is conflict serializable and strict (a value written by T is not read or overwritten by other transactions until T aborts or commits) --> recoverable, no cascading aborts, aborted transactions can be undone by restoring the original values of modified objects
conflict serializability is sufficient but not necessary for serializability --> more general sufficient condition: view serializability (but no efficient algorithms)
every conflict serializable schedule is view serializable (the converse is not true; any view serializable schedule that is not conflict schedule contains a blind write)
lock manager: maintains a lock table, which is a hash table with data object (page, record, etc.) identifier as the key
lock table entry: number of transactions currently holding a lock on the object + nature of the lock (shared or exclusive) + pointer to a queue of lock requests
transaction table: the entry contains a pointer to a list of locks held by the transaction
implement lock request: transaction issues a lock request to the lock manager -- shared lock: empty queue, not exclusively locked --> grant lock and update lock table entry; exclusive lock: no transaction currently holds a lock --> grant lock and update lock table entry; otherwise --> add to queue, suspend transaction
atomicity of locking and unlocking: entire sequence of actions in a lock request call (checking to see if the request can be granted, updating lock table, etc.) must be atomic
latches: setting a latch before reading or writing a page ensures physical read or write operation is atomic
convoy: most of cpu cycles are spent on process switching --> a transaction holding a heavily used lock may be suspended by OS; until T is resumed, every other transaction that needs this lock is queued (such queues, called convoys, can quickly become very long) <-- one of drawbacks of building a DBMS on top of general-purpose OS with preemptive scheduling
lock upgrade: hold shared lock, request exclusive lock --> favoring lock upgrades (insert request to the front of the queue if no other transaction holds shared lock) does not prevent deadlocks (e.g. two transactions hold shared lock both request an upgrade to exclusive lock)
==> better approach: obtain exclusive locks initially, and downgrade to shared lock (this does not violate 2PL) --> reduce concurrency by obtaining write locks, improves throughput by reducing deadlocks
update lock: compatible with shared locks but not other update locks and exclusive locks --> initially update lock, then downgrade/upgrade (prevent conflicts with other read operations, and no deadlock because no other transaction can have upgrade or exclusive lock on the object)
waits-for graph: to detect deadlock cycles (precedence graph involves only committed transactions) --> deadlock resolved by aborting a transaction in cycle and release its locks: the one with the fewest locks / has done least work / farthest from completion / etc.
alternative: timeout mechanism
empirically deadlocks are rare --> detection-based schemes work well, but high level of contention for locks would use deadlock prevention
prevention: give each transaction a priority, and ensure lower-priority transactions are not allowed to wait for higher-priority transactions (or vice versa)
e.g. timestamp: oldest transaction has highest priority ==> wait-die (lower-priority transactions never wait for higher-priority transactions), or wound-wait
wait-die (nonpreemptive): when Ti requests a lock held by Tj, if Ti higher priority, it is allowed to wait; otherwise, it is aborted
wound-wait: if Ti higher priority, abort Tj; otherwise, Ti waits
higher-priority transactions never aborted in both schemes
reissuing timestamp after aborting and restarting: give the same timestamp it had originally
disadvantage of wait-die: younger transaction that conflicts with older transaction may be repeatedly aborted; advantage: transaction that has all locks it needs is never aborted
another way to prevent deadlocks --> conservative 2PL: obtain all locks needed when a transaction begins, or blocks waiting for these locks
phantom problem: if new items are added to the database, conflict serializability does not guarantee serializability
==> solution: (1) if no index --> scan, ensure no new page added in addition to locking all existing pages; (2) index locking (if no such data entries, the page that would contain the data entry is locked) <-- special case of predicate locking
B+ tree locking: (1) search: a shared lock on a node can be released as soon as a lock on a child node is obtained
(2) insert: when we lock a child node, we can release the lock on the parent if the child is not full (because splits can only propagate up to the child)
lock-coupling (crabbing): lock a child node and (if possible) release the lock on the parent
improve performance for inserts: obtain shared locks instead of exclusive locks, except for the leaf; if leaf if full, need upgrade to exclusive locks for all nodes to which the split propagates (may lead to deadlocks)
multiple-granularity locking: database --> files --> collection of pages --> collection of records
different granularity: locking overhead vs. concurrency
(contains hierarchy: a lock on a node locks that node and all its descendants -- very different from B+ tree locking, where locking a node does not lock any descendants)
intention shared (IS): conflict only with X locks
intention exclusive (IX): conflict with S and X locks
to lock a node in S (X) mode, a transaction must first lock all its ancestors in IS (IX) mode. locks must released in leaf-to-root order --> use with 2PL to ensure serializability
lock escalation: begin by obtaining fine granularity locks (e.g. at the record level) and after the transaction requests a certain number of locks at that granularity, start obtaining locks at the next higher granularity (e.g. at page level)
optimistic concurrency control: basic premise is most transactions do not conflict with other transactions (light contention for data objects)
three phases: (1) read, and write to private workspace; (2) validation at commit time: if there is possible conflict, abort and clear private workspace and restart; (3) write
each transaction is assigned a time stamp at the beginning of its validation phase, and the validation criterion checks whether the timestamp-ordering is an equivalent serial order: for every pair Ti and Tj such that TS(Ti) < TS(Tj), one of the following validation conditions must hold
(1) Ti completes all three phases before Tj begins
(2) Ti completes before Tj starts write phase, and Ti does not write any database object read by Tj
(3) Ti completes its read phase before Tj completes its read phase, and Ti does not write any database object that is either read or written by Tj
when one transaction is being validated, no other transaction can be allowed to commit
the write phase of a validated transaction must also be completed before other transactions can be validated
use critical section to ensure at most one transaction in its combined validation + write phase at any time
use a level of indirection (switch pointers) to keep these phases short
improved conflict resolution: fine-grained locking on individual data items
timestamp-based concurrency control: each transaction is assigned a timestamp at startup and at execution time, if action ai of Ti conflicts with action aj of Tj, ai occurs before aj if TS(Ti) < TS(Tj). if action violates this ordering, the transaction is aborted and restarted
every database object is given a read timestamp RTS(O) and a write timestamp WTS(O) --> write operation of object time stamp is significant overhead)
restart: new larger timestamp --> different from the use of timestamps in 2PL for deadlock prevention
read: if TS(T) < WTS(O), abort; if TS(T) > WTS(O), read and set RTS(O) to max(RTS(O), TS(T))
write: if TS(T) < RTS(O), abort; if TS(T) < WTS(O), ignore such writes; otherwise, write and set WTS(O) to TS(T)
Thomas write rule --> some schedules are permitted that are not conflict serializable
but the above timestamp protocol permits schedules that are not recoverable ==> modification: buffering all write actions until transaction commits (and block other transactions that read the object)
overhead --> used mainly in distributed database systems
multiversion concurrency control: timestamps assigned at startup time; a transaction never has to wait to read a database object (reads never blocked); and maintain several versions of each database object, each with a write timestamp, and let transaction Ti read the most recent version whose timestamp precedes TS(Ti)
every object also has read timestamp --> if Ti wants write, TS(Ti) < RTS(O), abort; otherwise, create new version and set read/write timestamps to TS(Ti)
Chapter 18. Crash recovery
recovery manager: atomicity (undoing actions of transactions that do not commit) and durability (all actions of committed transactions survive system crashes and media failures)
ARIES: recovery algorithm designed to work with steal, no-force approach
(1) analysis: identify dirty pages in the buffer pool (changes not written to disk yet) and active transactions at crash time
(2) redo: repeats all actions, starting from appropriate point in the log, and restores database state to what it was at crash time
(3) undo: undoes actions of transactions that did not commit
write-ahead logging: any change to database object is first recorded in the log; the record in the log must be written to stable storage before change to database object is written to disk
repeating history during redo; logging changes during undo
log: a file of records stored in stable storage (two or more copies of the log on different disks)
log tail: the most recent portion of the log, kept in main memory and is periodically forced to stable storage (log records and data records are written to disk at same granularity, e.g. pages or sets of pages)
log sequence number (LSN): a unique id --> monotonically increasing, e.g. address of the first byte of the log record
pageLSN: every page in database contains the LSN of the most recent log record that describes a change to this page
log record types: update (and set pageLSN), commit (force-write log tail to stable storage, up to and including the commit record), abort (and undo), end (additional actions beyond abort or commit), undo (compensation log record, CLR)
log record: prevLSN + transID + type --> maintained as a linked list
update log record:

compensation log record: written before the change recorded in an update log record is undone; also contains a field called undoNextLSN (next log record to be undone)
CLR describes an action that will never be undone --> the number of CLRs that can be written during undo <= the number of update log records for active transactions at crash time
transaction table: one entry for each active transaction -- transaction id + status (in progress, committed, or aborted) + lastLSN (LSN of most recent log record)
dirty page table: one entry for each dirty page in the buffer pool -- recLSN (LSN of first log record that caused the page to become dirty --> earliest log record that might have to be redone for this page during restart from a crash)
these tables are maintained by transaction/buffer manager, and reconstructed in the analysis phase of restart

write-ahead log protocol --> forcing all log records up to and including the one with LSN equal to the pageLSN to stable storage before writing the page to disk
committed transaction: all log records including a commit record have been written to stable storage (even if no-force approach is used)
cost of forcing log tail is much smaller than cost of writing all changed pages to disk: (1) size of update log record is much smaller than size of changed pages; (2) sequential files --> sequential writes
checkpoint periodically: reduce amount of work to be done during restart
three steps: (1) begin_checkpoint record; (2) end_checkpoint record, including in it current (at begin_checkpoint time) transaction table and dirty page table; (3) a special master record containing LSN of begin_checkpoint log record is written to a known place on stable storage
this kind of checkpoint is called fuzzy checkpoint --> no need to quiesce system or write out pages in buffer pool, must redo changes starting from log record equal to recLSN
three phases of restart in ARIES: (relative order of A, B, C may differ)
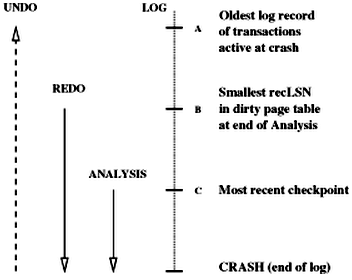
analysis phase: (1) determine the point in log at which to start redo; (2) determine a conservative superset of pages in buffer pool that were dirty at crash time; (3) identify active transactions at crash time and must be undone
at the end of analysis phase, transaction table contains an accurate list of active transactions at crash time; the dirty page table includes all pages that were dirty at crash time buy may also contain some pages that were written to disk
redo phase (repeating history paradigm, including CLR): begins with the oldest update that may not have been written to disk prior the crash (smallest recLSN in dirty page table); for each redoable log record (update or CLR), checks whether logged action must be redone; reply logged action, reset pageLSN, no additional log record written
no need to redo action if one of the following conditions holds:
(1) the affected page is not in dirty page table
(2) the affected page is in dirty page table, but recLSN for the entry is greater than the LSN of the log record being checked
(3) the pageLSN (stored on page, which must be retrieved to check this condition) >= LSN of the log record being checked <-- because either this page or a later update to the page was written to disk (assume write to a page is atomic)
loser transactions: all transactions active at crash in the transaction table, with their lastLSN fields --> ToUndo set: set of lastLSN values for all losers
undo repeatedly chooses the largest (most recent) LSN value from ToUndo and processes it until ToUndo is empty
undo: to process a log record --> if it is a CLR, add undoNextLSN to ToUndo or end record is written; if it is a update record, a CLR is written and undo corresponding action and add prevLSN to ToUndo
aborting a transaction: a special case of undo phase of Restart in which a single transaction (rather than a set of transactions) is undone
crashes during restart: ensure that undo action for an update log record is not applied twice

media recovery: periodically making a copy of database, similar to taking a fuzzy checkpoint
when a database object (file or page) is corrupted, the copy of that object is brought up-to-date by using the log (and most recent complete checkpoint): redo and undo
ARIES support fine-granularity locks (record-level locks) and logging of logical operations rather than just byte-level modifications <-- because redo repeats history
--> record-level locks require logical operations, because undoing may not be inverse of physical (byte-level) actions of, say, inserting the entry (the entry may be on a different physical page when transaction T aborts from the one that T inserted it into, since there are other concurrent transactions doing inserts and deletes)
System R prototype takes different approach: pages accessed through a page table, which maps page ids to disk addresses --> when a transaction makes change to a data page, it makes a copy of the page (shadow page) and changes shadow page and copies table page with modified entry, until itcommits
--> abort transaction: discard its shadow versions of page table and data pages















 6721
6721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









