










一、基本信息
官网 https://nifi.apache.org/
下载地址 https://www.apache.org/dyn/closer.lua?path=/nifi/1.12.1/nifi-1.12.1-bin.tar.gz
下载链接
https://mirror.bit.edu.cn/apache/nifi/1.12.1/nifi-1.12.1-bin.tar.gz
https://mirrors.bfsu.edu.cn/apache/nifi/1.12.1/nifi-1.12.1-bin.tar.gz
https://mirrors.tuna.tsinghua.edu.cn/apache/nifi/1.12.1/nifi-1.12.1-bin.tar.gz
二、核心概念整理
https://www.cnblogs.com/ronnieyuan/p/11935871.html
NiFi——Apache NiFi是由美国国家安全局(NSA)贡献给Apache基金会的开源项目,其设计目标是自动化系统间的数据流。基于其工作流式的编程理念,NiFi非常易于使用、强大、可靠、高可配置。两个最重要的特性是其强大的用户界面和良好的数据回溯工具。堪称大数据工具箱里的瑞士军刀。NiFi的主要用途是对数据进行处理,可汇总、分流、过滤、筛选、组合…等等
简单地说,NiFi是为了自动化系统之间的数据流而构建的。虽然术语“数据流”在各种环境中使用,但我们在此处使用它来表示系统之间自动化和管理的信息流。这个问题空间一直存在,因为企业有多个系统,其中一些系统创建数据,一些系统消耗数据。已经讨论并广泛阐述了出现的问题和解决方案模式。企业集成模式 中提供了一个全面且易于使用的表单。
NiFi的诞生,要致力于解决的问题:
(1)因为网络故障、磁盘故障、软件崩溃、人们犯错导致的系统错误。
(2)数据读写超出了自身系统的处理能力。
(3)获取的数据不具有规范性。
(4)数据结构的优先级变化很快,启用新流和更改现有流的速度必须非常快。
(5)数据结构化管理的可移植性与不同数据格式之间的依赖性。
nifi内部功能强大,它的一个优点就是大大减少了编程量!它有很多内置的处理模块,只需用户修改条件或变量便可实现其功能,此外还有一些模块可执行程序代码来进行更灵活的自定义的操作。
nifi中最常用到的就是正则表达式,偶尔会用到一些代码(java),其次就是数据源的格式(xml、csv、txt、pdf等)
所以nifi对有一定编程基础的人来说还是很好上手的,只需要多看看文档上对各个模块的释义以及一些函数规则,了解各个模块的功能即可顺畅使用。
nifi对于没有编程基础的人的门槛设置也不是很高,逻辑思维需要通过多个case来练习,训练对nifi的熟悉度,体会其中的逻辑。此外还要学习正则表达式的语法。
三、基础环境
1、安装OpenJDK1.8 并查看安装位置
https://blog.csdn.net/llwy1428/article/details/111144659
2、Centos7.x 安装部署 Hadoop 3.x HDFS基础环境(非高可用集群)
https://blog.csdn.net/llwy1428/article/details/111144524
3.NiFi 1.12.1
4.使用root用户操作
5.集群未启用Kerberos
四、安装、部署
1、创建目录,以供 Nifi 监听服务器内部文件
[root@slave3 ~]# mkdir -p /opt/data/nifi
2、创建实例文件
[root@slave3 ~]# touch /opt/data/nifi1.txt
[root@slave3 ~]# touch /opt/data/nifi2.txt
[root@slave3 ~]# touch /opt/data/nifi3.txt
3、向实例文件写入内容
[root@slave3 ~]# echo 'Hello Nifi 1 !' >> /opt/data/nifi1.txt
[root@slave3 ~]# echo 'Hello Nifi 2 !' >> /opt/data/nifi2.txt
[root@slave3 ~]# echo 'Hello Nifi 3 !' >> /opt/data/nifi3.txt
4、查看每个实例文件
[root@slave3 ~]# cat /opt/data/nifi1.txt
Hello Nifi 1 !
[root@slave3 ~]# cat /opt/data/nifi2.txt
Hello Nifi 2 !
[root@slave3 ~]# cat /opt/data/nifi3.txt
Hello Nifi 3 !
5、启动 HDFS 服务
[root@master ~]# /usr/bigdata/hadoop-3.3.0/sbin/start-dfs.sh
6、在 HDFS 上创建 nifi 存放文件的目录
[root@slave3 ~]# hdfs dfs -mkdir /user/nifi
7、给创建的目录赋权
[root@slave3 ~]# hdfs dfs -chmod 777 /user/nifi
8、下载 nifi 的安装包
[root@slave3 ~]# wget -P /usr/bigdata/ https://mirror.bit.edu.cn/apache/nifi/1.12.1/nifi-1.12.1-bin.tar.gz
9、进入已下载安装包的目录
[root@slave3 ~]# cd /usr/bigdata/
10、解压安装文件
[root@slave3 bigdata]# tar zxf nifi-1.12.1-bin.tar.gz
11、进入 nifi 目录查看文件目录
[root@slave3 bigdata]# cd nifi-1.12.1
12、进入 nifi 的配置文件目录
[root@slave3 nifi-1.12.1]# cd conf/
13、查看文件列表
[root@slave3 conf]# ll
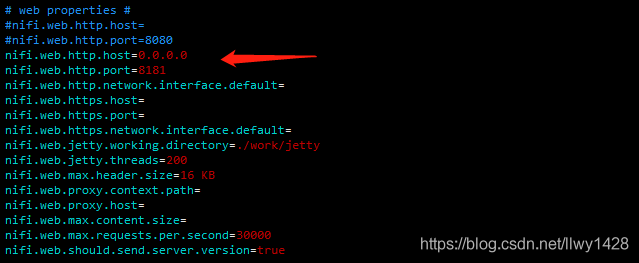
14、编辑 nifi 的配置文件 nifi.properties (我更改了 nifi 的 web 端口,因为其默认端口是 8080 ,我有一些其他服务已使用了 8080)
此处我把 web 的端口改成了 8181
并配置所有 IP 均可访问
[root@slave3 conf]# vim nifi.properties
编辑内容
#nifi.web.http.host=
#nifi.web.http.port=8080
nifi.web.http.host=0.0.0.0
nifi.web.http.port=8181
如下图:
15、启动 nifi 服务
[root@slave3 ~]# /usr/bigdata/nifi-1.12.1/bin/nifi.sh start

16、查看 nifi 的web 服务启动后所占用的端口情况
[root@slave3 ~]# netstat -lntp
tcp 0 0 0.0.0.0:8181 0.0.0.0:* LISTEN 2041/java
17、停止 nifi 服务
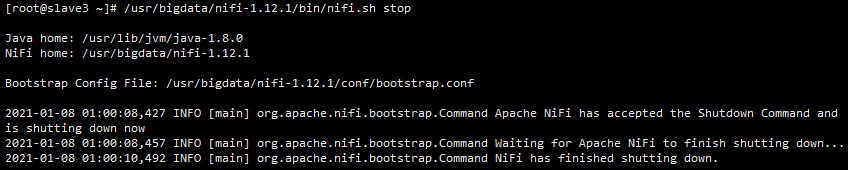
[root@slave3 ~]# /usr/bigdata/nifi-1.12.1/bin/nifi.sh stop
五、浏览器查看、配置
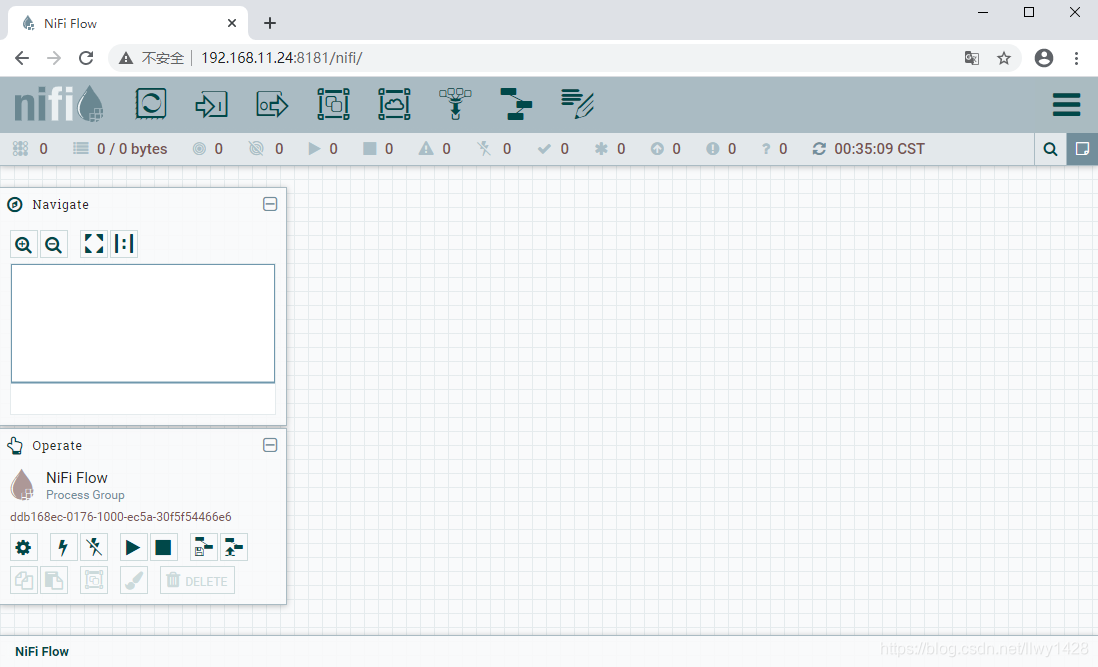
1、在浏览器地址栏录入 http://192.168.11.24:8181/ ( 192.168.11.24 是我安装部署 nifi 所用服务的 IP )
首页
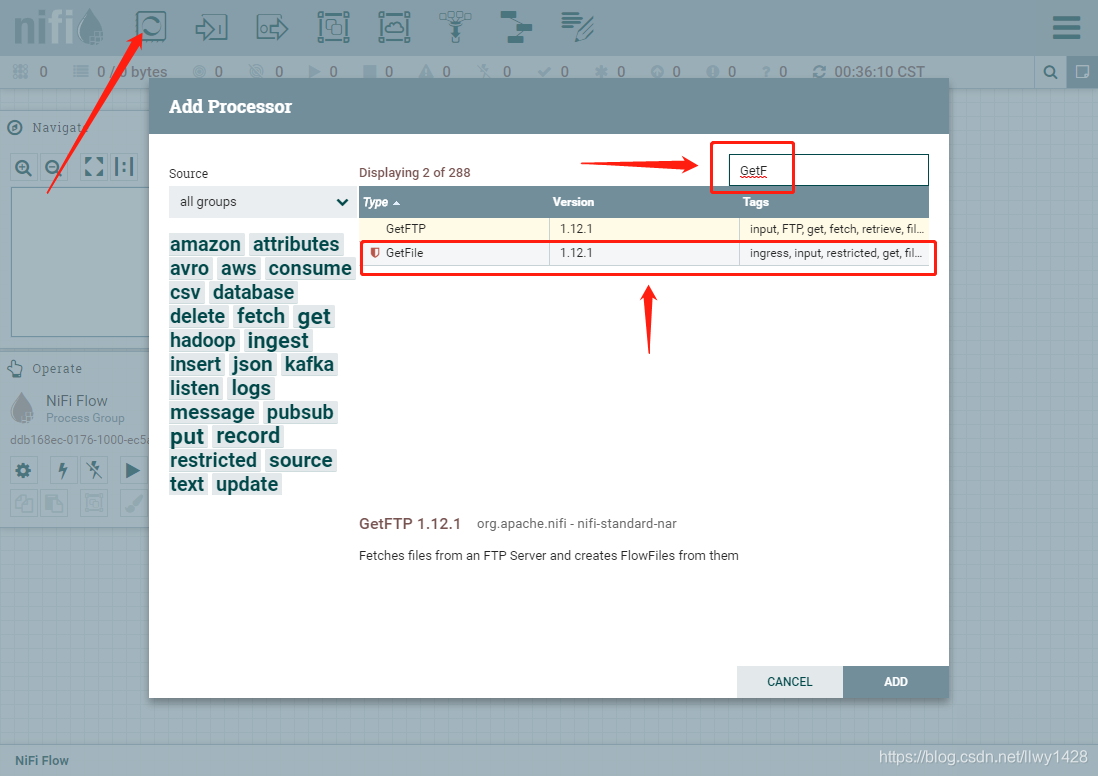
2、拖入一个处理器到画布中
搜索、选择 GetFile 处理器
3、双击 GetFile 窗口,进行编辑
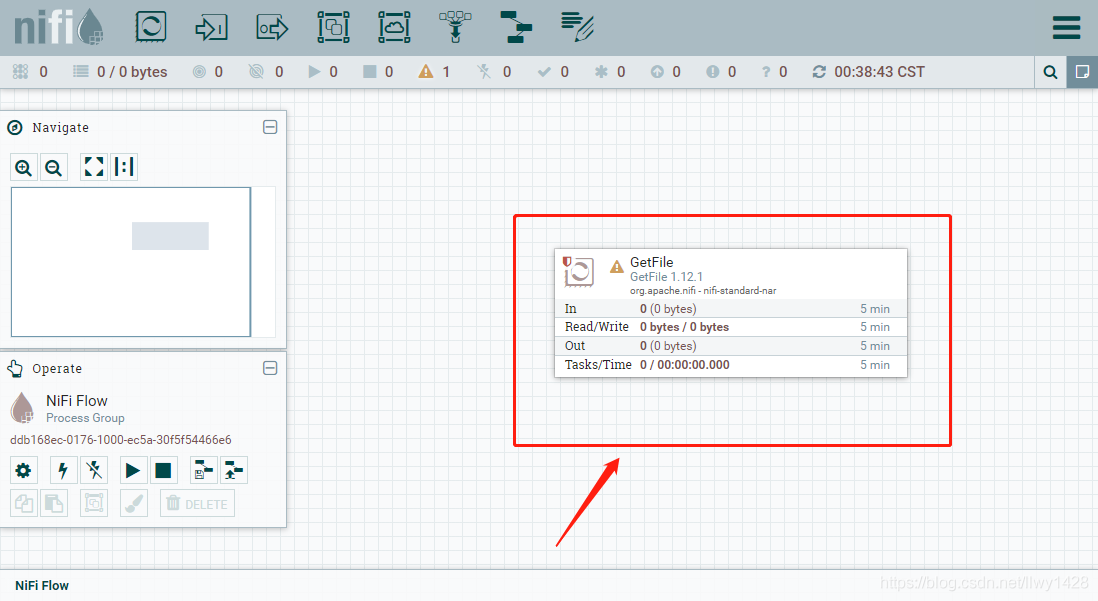
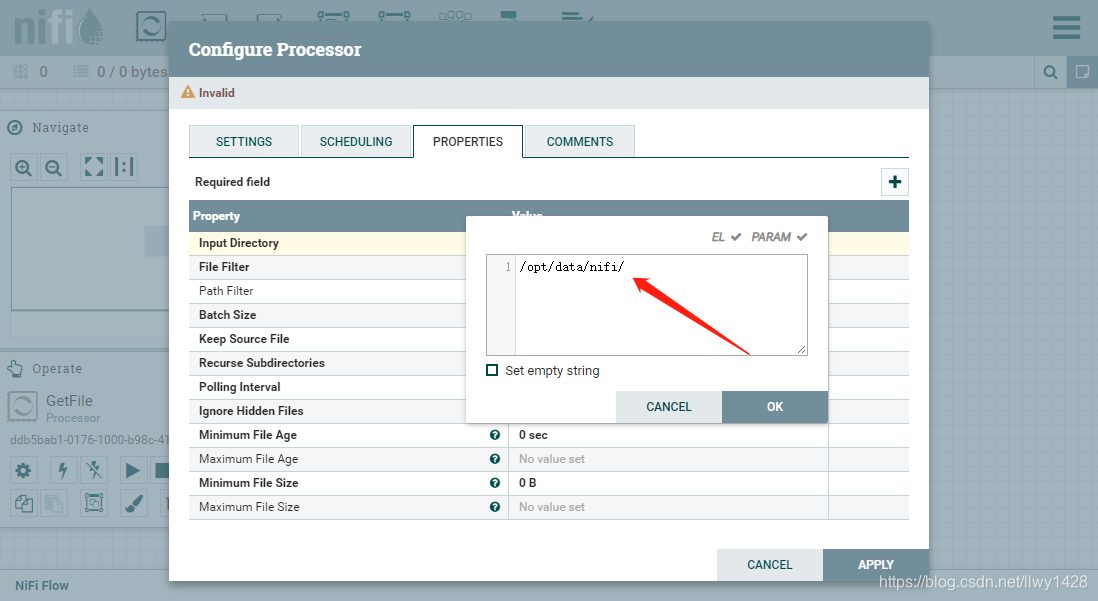
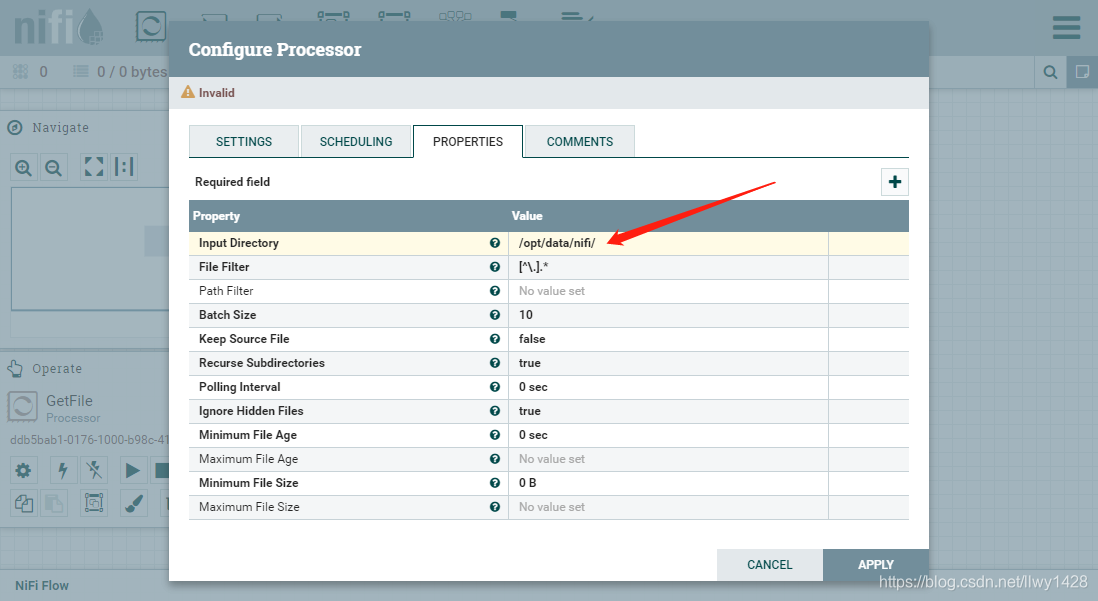
4、编辑 GetFile 处理器的属性,将 “Input Directory” 属性值改为前面创建的服务器数据目录的绝对路径 /opt/data/nifi ,点击“APPLY”保存。
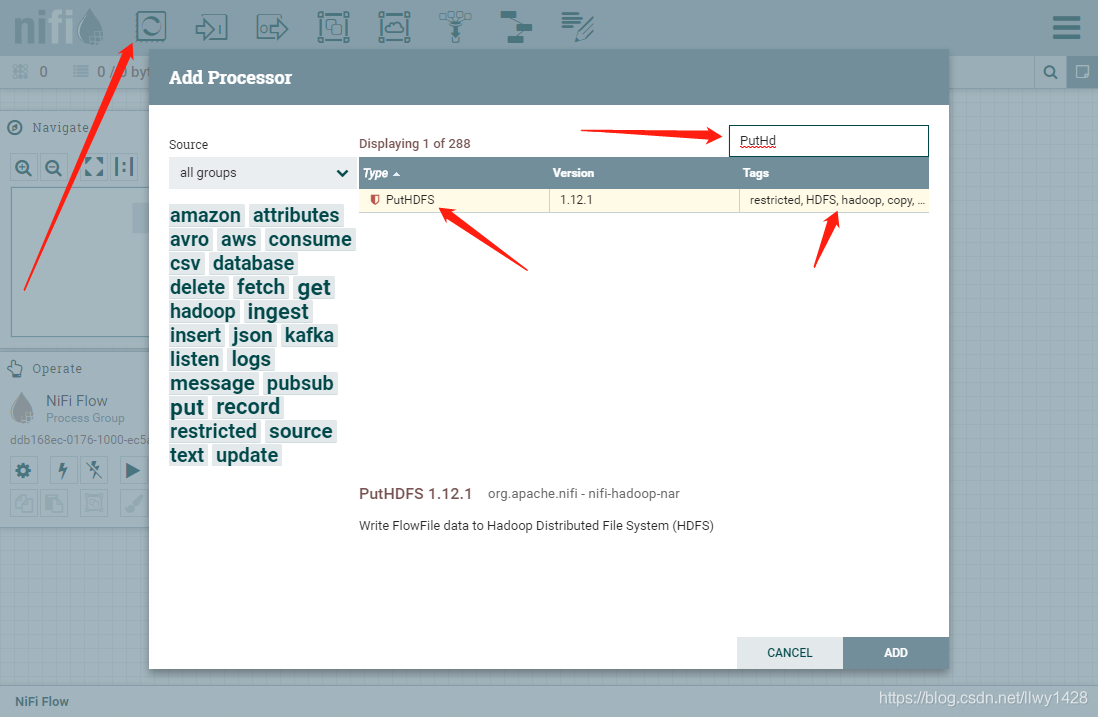
5、再拖入一个处理器到画布中,搜索、选择 PutHDFS 处理器,点击 “ADD”。
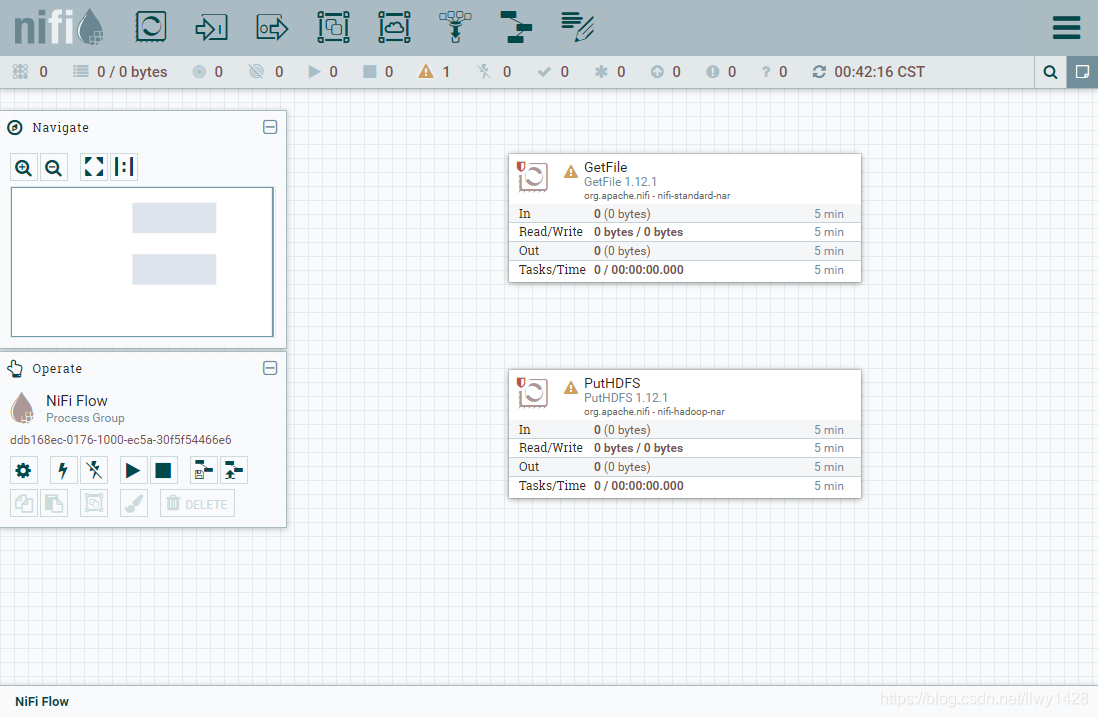
6、双击 PutHDFS 窗口,进行编辑
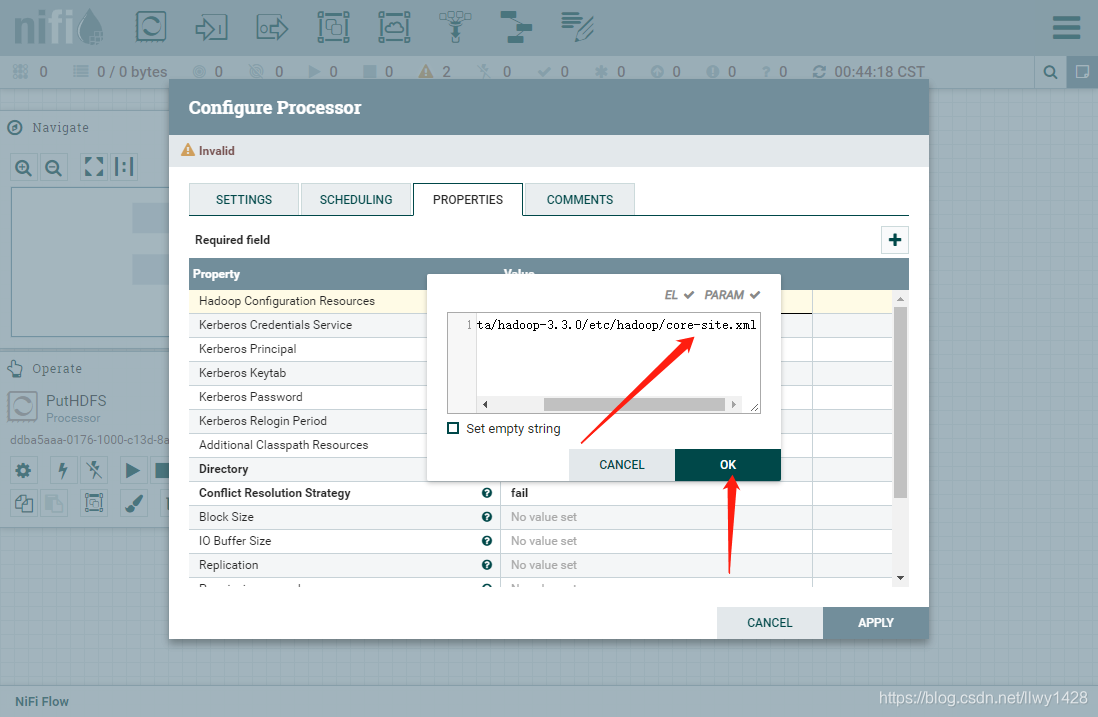
7、在指定位置填写 hadoop 的配置文件 core-site.xml 的绝对路径及文件名,如下图
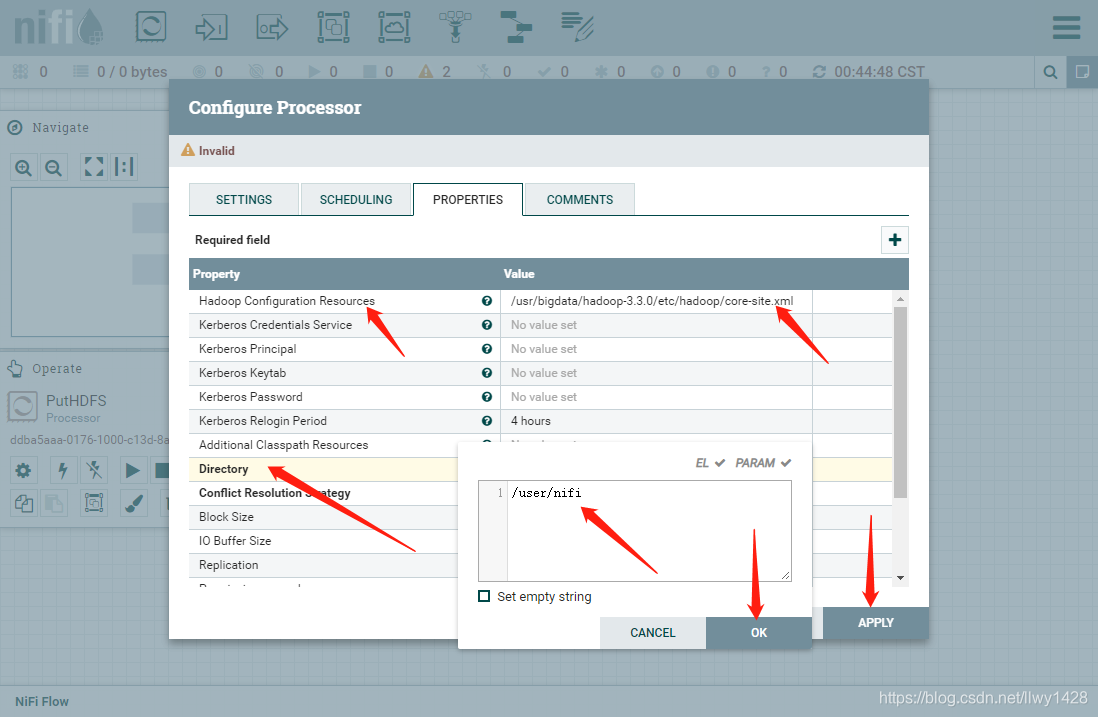
8、在 Directory 处填写 在 HDFS 中创建的用来存放文件的地址 /user/nifi
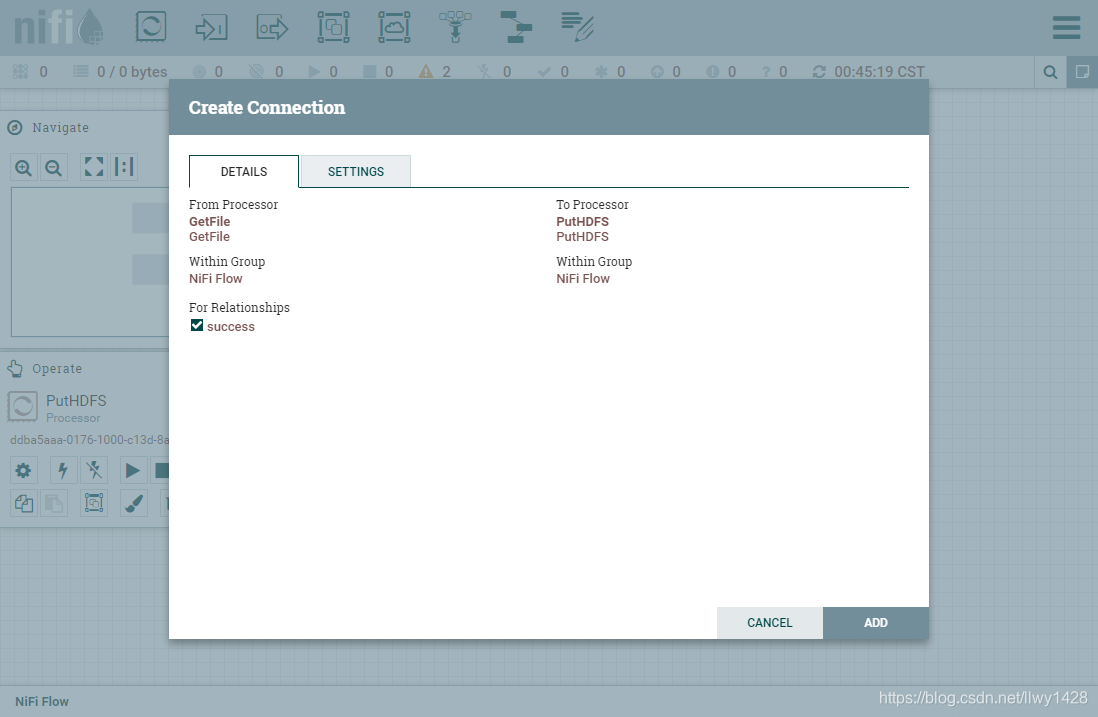
9、连接 GetFile 处理器到 PutHDFS 处理器
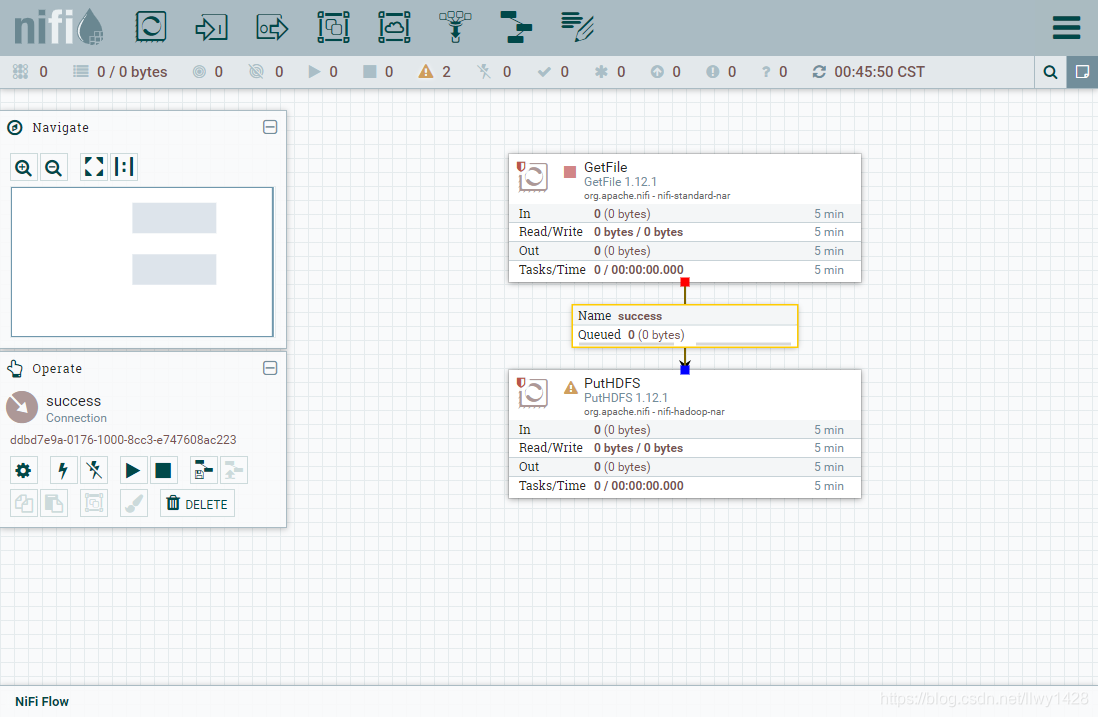
10、勾选PutHDFS处理器中 Automatically Terminate Relationships 下的 success 和 failure 两项配置,点击“APPLY”保存。
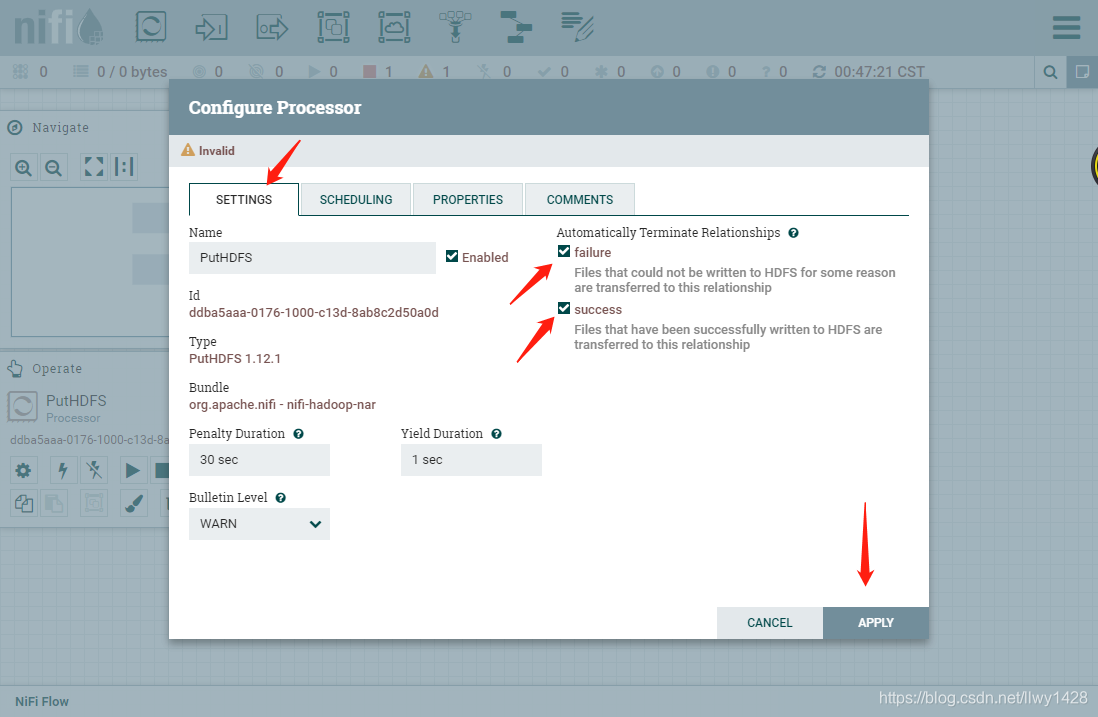
11、左键单击选中 GetFile 处理器,按住 shift 再次选中 PutHDFS 处理器,点击 “Start” 。
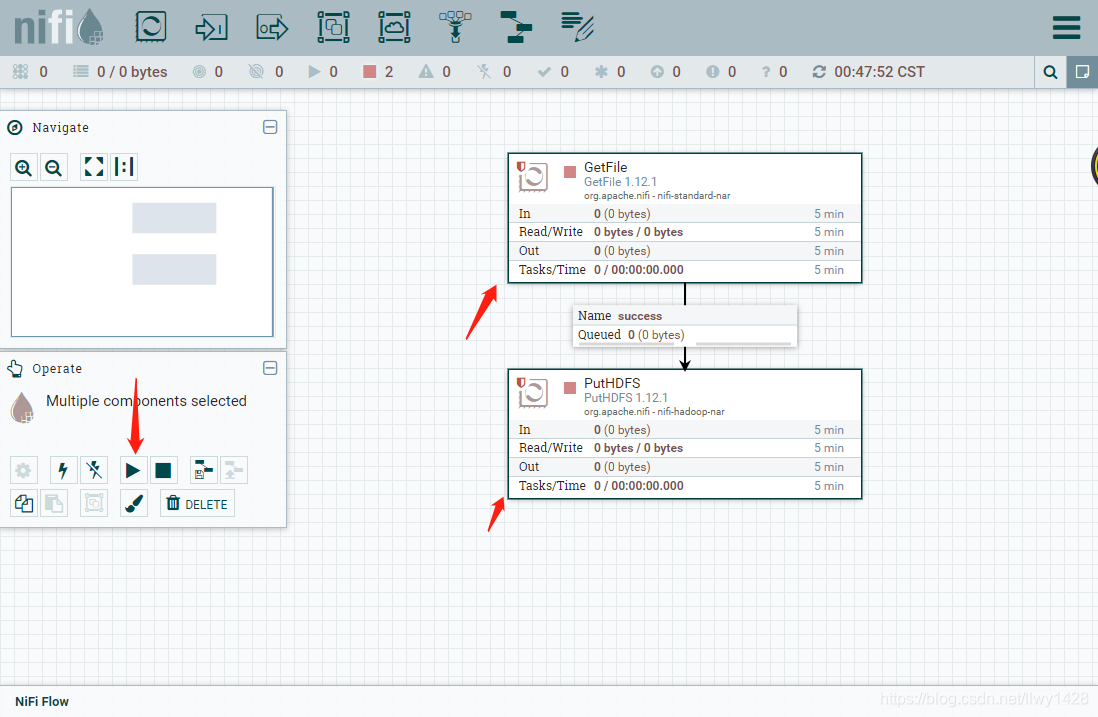
六、文件操作、HDFS 查看
1、先确保服务器物理地址和 HDFS 中没有文件
服务器物理地址
[root@slave3 ~]# hdfs dfs -ls /user/nifi
HDFS 中
[root@slave3 ~]# ll /opt/data/nifi
总用量 0
2、把上文创建好的实例文件移到到监听目录 /opt/data/nifi 下
[root@slave3 ~]# mv /opt/data/nifi1.txt /opt/data/nifi
[root@slave3 ~]# mv /opt/data/nifi2.txt /opt/data/nifi
[root@slave3 ~]# mv /opt/data/nifi3.txt /opt/data/nifi
3、再到 HDFS 中查看 nifi 的文件存储目录
节点:slave1
[root@slave1 ~]# hdfs dfs -ls /user/nifi/
Found 3 items
-rw-r--r-- 3 root supergroup 15 2021-01-08 00:53 /user/nifi/nifi1.txt
-rw-r--r-- 3 root supergroup 15 2021-01-08 00:53 /user/nifi/nifi2.txt
-rw-r--r-- 3 root supergroup 15 2021-01-08 00:53 /user/nifi/nifi3.txt
节点:slave2
[root@slave2 ~]# hdfs dfs -ls /user/nifi/
Found 3 items
-rw-r--r-- 3 root supergroup 15 2021-01-08 00:53 /user/nifi/nifi1.txt
-rw-r--r-- 3 root supergroup 15 2021-01-08 00:53 /user/nifi/nifi2.txt
-rw-r--r-- 3 root supergroup 15 2021-01-08 00:53 /user/nifi/nifi3.txt
节点:slave3
[root@slave3 ~]# hdfs dfs -ls /user/nifi/
Found 3 items
-rw-r--r-- 3 root supergroup 15 2021-01-08 00:53 /user/nifi/nifi1.txt
-rw-r--r-- 3 root supergroup 15 2021-01-08 00:53 /user/nifi/nifi2.txt
-rw-r--r-- 3 root supergroup 15 2021-01-08 00:53 /user/nifi/nifi3.txt
4、HDFS WEB 查看 nifi 文件列表
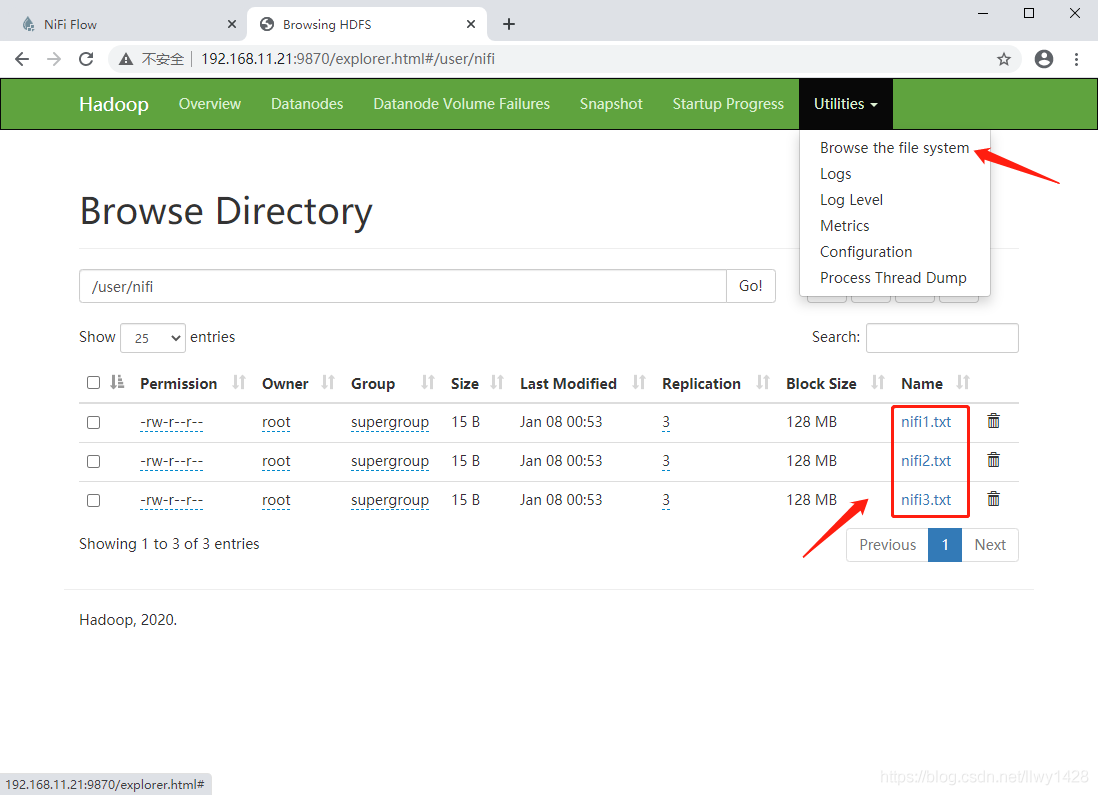
5、查看 HDFS 中文件 nif1.txt

6、查看 HDFS 中文件 nif2.txt
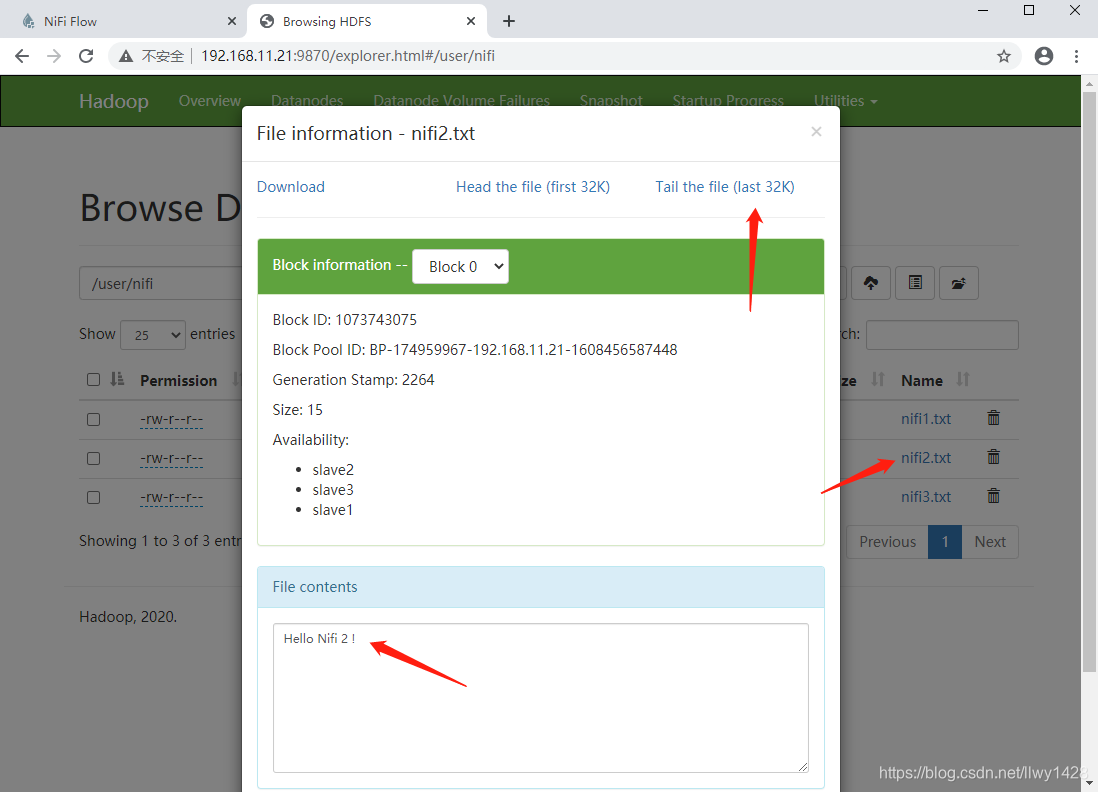
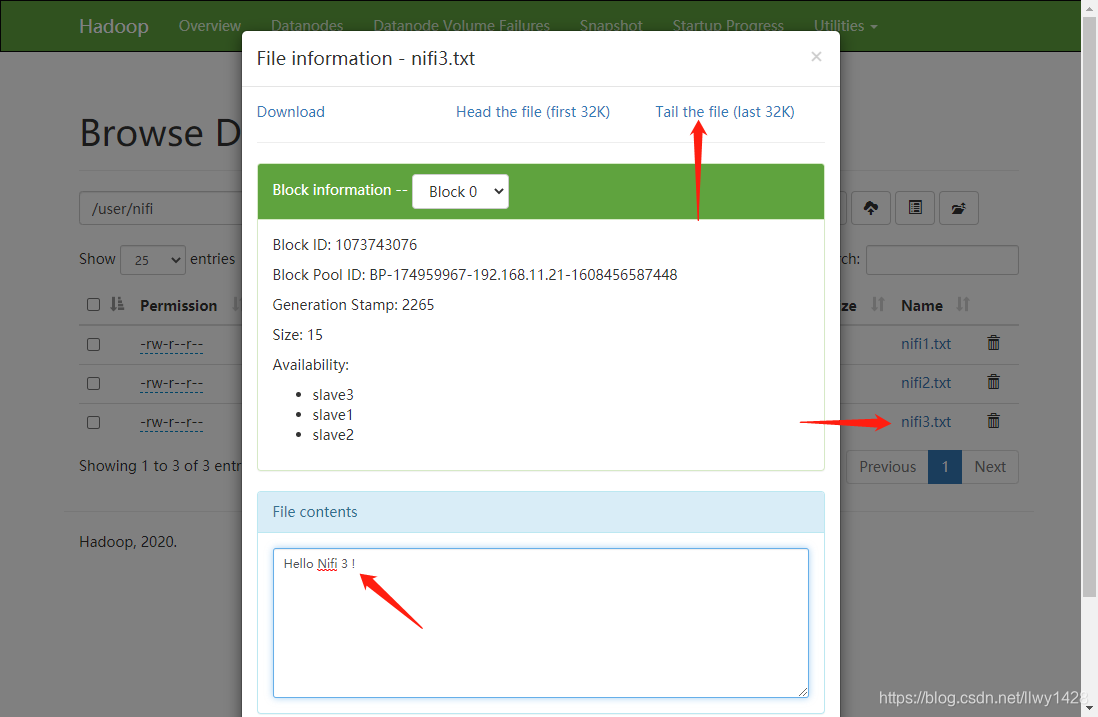
7、查看 HDFS 中文件 nif3.txt
参考
开源中国 https://www.oschina.net/p/nifi
实例 https://my.oschina.net/u/4016761/blog/4577005
入门 https://www.jianshu.com/p/62b7e44cfd0b
至此,基于 Hadoop 3.3.0 集群 安装、部署 Nifi 1.12.1 操作完毕,希望能够对您有所帮助!














 748
748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









