







DEFINITION:
As described semi-join in previous forum (Tip#25), a semi-join between two tables returns rows from the outer table where one or more matches are found in the inner table. The difference between a semi-join and a conventional join is that rows in the outer table will be returned at most once. Even if the outer table contains one or more matches for a row in the inner table, only one copy of the row from the outer table will be returned. Outer table is nothing but the table mentioned in the outer query of the statement and inner table is nothing but the table mentioned in the inner query of the statement. Semi-joins are written using the EXISTS or IN constructs (or operators).
As mentioned in the earlier tips, semi join can be achieved by 3 different joining techniques. But, from Oracle 10g onwards, Oracle has started to provide the fourth joining technique to handle the semi join.
• Nested loop semi join
• Hash semi join
• Hash semi right join (from Oracle 10g onwards)
• Merge semi join
We will discuss about Hash Semi Right Join in this forum.
Hash semi right join is preferred over hash semi join only if the inner table is semi-joined with the outer table and the latter is bigger than the former either in terms of number of records or the number of distinct values in the joining column(s)) . In this case, hash semi right join would perform more efficiently than hash semi join and that’s the reason oracle will opt for the former instead of the latter from 10g onwards.
As you aware, in hash semi join, deciding which table is going to be the hash table is immaterial and the outer table is always selected as the hash table irrespective of its size. This shows the design flaw in hash semi join as the outer table would be used as the hash table, if it is big, all the records from the big outer table can’t be processed in a single pass, allocated memory space in RAM might not be big enough to hold all the required records of the big outer table, so it has to do multiple passes and takes a lot of time. This design flaw has been overcome in hash semi right join. If that small inner table was selected as the hash table, none of these issues won’t need to be addressed and that’s what hash semi right join exactly does.
In a conventional semi-join, the nested loops algorithm is desirable when the predicate(s) on the first table(outer table) are very selective and the join column(s) in the second table(inner table) are selectively indexed. The merge and hash join algorithms, meanwhile, are more desirable when predicates are not very selective in the first table(outer table) or the join columns in the second table(inner table) are not selectively indexed. In hash semi right join, Oracle uses RAM memory to speed up the join. In this, Oracle does a scan of the inner table, builds a RAM hash table, and then probes for matching rows from the outer table. For certain types of SQL, the hash semi right join will execute faster than the hash semi join, and the former also uses less RAM resources in that scenario.
To perform this hash semi right join, Oracle follows these steps (assume, a small inner table has to be semi-joined with a big outer table):
1. Oracle chooses the small inner table as the hash table.
2. Oracle build the hash table in RAM after applying the hash function on the joining column(s) of the inner table but make sure that only one record gets inserted in memory for each distinct value of joining column(s).
3. Oracle chooses the big outer table as the probe table (or probing table). It traverse through all the records of this probe table, applies the same hash function on the joining column(s) [column(s) used to join these two tables] and will hit the corresponding entry in the hash table.
4. Oracle returns the probe table’s record in the output if a record from the inner table is already present with the same hash key else the probe table’s record will be skipped.
The logical activity diagram for this methodology will be like this,
Loop (for all the required records in the inner table)
• Apply the hash function for each record to get the address [hashed value] in RAM
• Hit RAM in the corresponding address
• Insert the record only if that hash key location is empty else skip it => [Semi join requirement is met]
End loop
Loop (for all the required records in the outer table)
• Apply the hash function for each record to get the address [hashed value] in RAM
• Hit RAM in the corresponding address
• If this probe table record hits the hash table where a record from the inner table is already available, then the probe table’s record is returned in the output else skip to the next probe table’s record.
End loop
In the above logical activity diagram, the step highlighted in red is the important step where the hash semi right join meets the semi join requirement. In hash semi right join, if there are more than 1 record is available for the same value of the joining column(s) in the inner table, all those records will be skipped except anyone record getting inserted into the hash table. By this, displaying the same outer table record (in case of hits) again & again is being avoided and thus meet the requirement of semi join.
LITTLE-KNOWN FACTS TO BE REMEMBERED:
• /*+ HASH_SJ */ is the hint that can be used to impose this hash semi right join. But this hint has to be applied inside the subquery of the EXISTS or IN clause, not in the main query itself.
• From 10g version onwards, oracle can consider inner table as the hash table in imposing hash semi right join if either the number of records or the number of distinct values on the joining column(s) is lesser in inner table. The hash table and probe table was fixed in hash semi join till 9i. This has been overcome in an extended version of hash semi join which is named “hash right semi join” from 10g version onwards.
• An in-line view with NO_MERGE hint could be used to isolate the ill effect of DISTINCT keyword so the semi-join access paths would not be defeated. This is applicable for all type of semi-joins.
• In general (or atleast till Oracle9i), Oracle transforms a subquery with semi-join into a conventional equi-join if at all possible. Oracle does not consider “cost” when deciding whether or not to do this transformation. So Oracle can execute a query with EXISTS (or) IN clause either by opting for any semi-join access path or conventional join access path followed by an unique operation to remove duplicate rows if the transformation happens. Implementation of Hash Semi Right join has been getting improved in each Oracle version. So higher the version, Oracle may not be opting to do this transformation and just go with any semi-join access path if EXISTS (or) IN clause is used in the query. This is applicable for all type of semi-joins.
• In RAM, hash semi right join will be carried out only in the allocated memory space which is nothing but HASH_AREA_SIZE component of PGA.
• Only the inner table records will be inserted as the hash table in RAM and the outer table records will never be written into RAM. Hash function will be applied in the probe table (outer table here) only to locate the corresponding memory entry in the hash table to look for the matching entry from the inner table there.
• No column(s) from the subquery can be returned in the output.
• If the query contains DISTINCT clause, then Oracle cannot impose this semi-join though EXISTS (or) IN clause is mentioned in the query.
• If the query contains UNION set operator, then Oracle cannot impose this semi-join though EXISTS (or) IN clause is mentioned in the query.
• If the EXISTS (or) IN clause is part of an OR branch in the query, then Oracle cannot impose this semi-join.
• However this semi-join can be imposed in queries that contain OR clause(s) in the WHERE clause, just as long as the EXISTS (or) IN is not part of the OR.
• Even the operator, “=ANY” can be used to impose this semi-join apart from IN & EXISTS constructs.
• The statement must have a subquery in the IN (or) EXISTS clause in order to invoke this semi-join. It means, usual IN clause wherein hardcoded value(s) mentioned in R.H.S (Right Hand Side) of this clause cannot invoke this semi-join.
• This methodology is opted by Oracle only if a small inner table is semi-joined with a big outer table. So this is very successful when inner table is smaller and outer table is bigger. In this case, it outplays the hash semi join.
• If the inner table cannot be hashed in RAM in single pass (i.e., at one shot or one go), then a portion of the hash-table spills to disk(actually, TEMP tablespace will be used here to hold that spilled dataset from the inner table). When the hash table is probed by the outer table, the rows with join keys that match those parts of the in-memory hash table are joined immediately; the rest [of the outer table] are also written into TEMP tablespace and joined in the subsequent passes. The bigger inner table is, the smaller the proportion of it in RAM, the remaining data will be spilled into TEMP tablespace and have to go through the subsequent passes till it processes all the records spilled into TEMP tablespace from both these inner and outer tables. This slows down Hash Semi Right Join considerably and also makes the join non-scalable in this scenario.
ADVANTAGE:
• This is very successful when many records of the outer table doesn’t have the matching records in the inner table, only some records in the outer table has lots of matching records in the inner table, and both the tables are not properly indexed. In this scenario, it outperforms both nested loop semi join and hash semi join.
• If a query is the best candidate for hash semi right join, then this semi join can reduce logical reads, CPU time & elapsed time dramatically but will increase physical reads (with no harm).
• Still nested loop semi join will be the fastest way to retrieve the first matching record [since hash semi right join takes some time to build the hash table in RAM for the inner table as it applies hash function] but hash semi right join will be the fastest way to get all the matching records quickly when compared to nested loop semi join. In general, hash function (in hash semi right join) will perform better and more efficiently.
DISADVANTAGE:
• If hash semi right join is imposed in a query wherein if all the records in the outer table has lots of matching records in the inner table and the inner table is properly indexed, then it will behave badly than the nested loop semi join. The reason is, as per hash semi right join, all the records in the inner table will be hashed and thus unnecessarily waste time there instead of stopping once the first matching record is seen. In this scenario, it will be better if nested loop semi join is used.
• If the allocated space in RAM memory is not large enough to hold the entire hash table, Oracle will use the temporary tablespace, and then complete the join operation. If this join uses the temporary tablespace, then the execution time of the query will get affected. This scenario makes hash semi right join more non-scalable as it has to go through subsequent passes to join these spilled dataset (available in TEMP tablespace) from both these tables
HOW TO VERIFY:
How to verify whether Oracle follows hash semi right join or not while executing SQL. If a query follows this, then you will find similar execution plan like this,
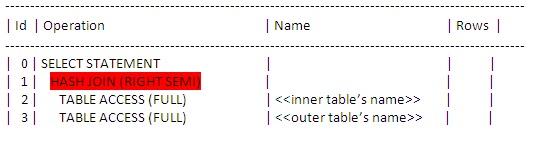 In the explain plan, whenever it chooses this methodology, it displays the keyword [HASH JOIN (RIGHT SEMI)] in the operation column. Whichever the table name that is getting displayed immediately after this word is nothing but the inner table and the next one is the outer table.
In the explain plan, whenever it chooses this methodology, it displays the keyword [HASH JOIN (RIGHT SEMI)] in the operation column. Whichever the table name that is getting displayed immediately after this word is nothing but the inner table and the next one is the outer table.
EXAMPLE:
In order to understand how the design flaw of hash semi join has been overcome by hash semi right join, we will first discuss the example with the hash semi right join. Then we would discuss how it would behave badly if the same was done with hash semi join.
Create 2 tables.
One table is store the information about all the employees and inserts 6 records.
Another table is store the information of the sales done by the employees and inserts 9 records.
The tables will look like this,
DATA TABLE:
EMP:
 SALES:
SALES:
 Fire this query against these tables where the requirement is to display the employee’s id & name of all the employess who has done atleast single sales transaction,
Fire this query against these tables where the requirement is to display the employee’s id & name of all the employess who has done atleast single sales transaction,
Select a.empid, a.empname
from emp a
where exists (select 1 from sales b where b.empid = a.empid);
Assume, Oracle can hold 3 records at a time in the allocated memory space(defined by HASH_AREA_SIZE global parameter) in RAM.
For easy understanding, pls assume MOD function to the base 10 will be used as hash function here. In real world, the hash function would be much more complex and hard to decode it.
Case-I: (for hash semi right join)
========================
We will discuss what would happen if hash semi right join was imposed. You would see this behavior only from Oracle 10g as this semi join has been implemented from this version only. As per this join, sales is the hash table and emp is the probe table since the number of distinct values in joining column (empid) is lesser in sales table.
EMPTY HASH TABLE:
=================
 As per the design of hash semi right join, the following steps will be followed while executing this query,
As per the design of hash semi right join, the following steps will be followed while executing this query,
1. Since SALES has less number of distinct values (on joining column) than EMP, SALES is considered as the hash table and EMP is considered as the probing table.
2. Since the memory can hold 3 records at a time, only 3 distinct values (on joining column) is available in SALES table, everything will get processed in a single pass.
3. For the first record in SALES, hash function is applied and it returns 1 as the hashed value
As described semi-join in previous forum (Tip#25), a semi-join between two tables returns rows from the outer table where one or more matches are found in the inner table. The difference between a semi-join and a conventional join is that rows in the outer table will be returned at most once. Even if the outer table contains one or more matches for a row in the inner table, only one copy of the row from the outer table will be returned. Outer table is nothing but the table mentioned in the outer query of the statement and inner table is nothing but the table mentioned in the inner query of the statement. Semi-joins are written using the EXISTS or IN constructs (or operators).
As mentioned in the earlier tips, semi join can be achieved by 3 different joining techniques. But, from Oracle 10g onwards, Oracle has started to provide the fourth joining technique to handle the semi join.
• Nested loop semi join
• Hash semi join
• Hash semi right join (from Oracle 10g onwards)
• Merge semi join
We will discuss about Hash Semi Right Join in this forum.
Hash semi right join is preferred over hash semi join only if the inner table is semi-joined with the outer table and the latter is bigger than the former either in terms of number of records or the number of distinct values in the joining column(s)) . In this case, hash semi right join would perform more efficiently than hash semi join and that’s the reason oracle will opt for the former instead of the latter from 10g onwards.
As you aware, in hash semi join, deciding which table is going to be the hash table is immaterial and the outer table is always selected as the hash table irrespective of its size. This shows the design flaw in hash semi join as the outer table would be used as the hash table, if it is big, all the records from the big outer table can’t be processed in a single pass, allocated memory space in RAM might not be big enough to hold all the required records of the big outer table, so it has to do multiple passes and takes a lot of time. This design flaw has been overcome in hash semi right join. If that small inner table was selected as the hash table, none of these issues won’t need to be addressed and that’s what hash semi right join exactly does.
In a conventional semi-join, the nested loops algorithm is desirable when the predicate(s) on the first table(outer table) are very selective and the join column(s) in the second table(inner table) are selectively indexed. The merge and hash join algorithms, meanwhile, are more desirable when predicates are not very selective in the first table(outer table) or the join columns in the second table(inner table) are not selectively indexed. In hash semi right join, Oracle uses RAM memory to speed up the join. In this, Oracle does a scan of the inner table, builds a RAM hash table, and then probes for matching rows from the outer table. For certain types of SQL, the hash semi right join will execute faster than the hash semi join, and the former also uses less RAM resources in that scenario.
To perform this hash semi right join, Oracle follows these steps (assume, a small inner table has to be semi-joined with a big outer table):
1. Oracle chooses the small inner table as the hash table.
2. Oracle build the hash table in RAM after applying the hash function on the joining column(s) of the inner table but make sure that only one record gets inserted in memory for each distinct value of joining column(s).
3. Oracle chooses the big outer table as the probe table (or probing table). It traverse through all the records of this probe table, applies the same hash function on the joining column(s) [column(s) used to join these two tables] and will hit the corresponding entry in the hash table.
4. Oracle returns the probe table’s record in the output if a record from the inner table is already present with the same hash key else the probe table’s record will be skipped.
The logical activity diagram for this methodology will be like this,
Loop (for all the required records in the inner table)
• Apply the hash function for each record to get the address [hashed value] in RAM
• Hit RAM in the corresponding address
• Insert the record only if that hash key location is empty else skip it => [Semi join requirement is met]
End loop
Loop (for all the required records in the outer table)
• Apply the hash function for each record to get the address [hashed value] in RAM
• Hit RAM in the corresponding address
• If this probe table record hits the hash table where a record from the inner table is already available, then the probe table’s record is returned in the output else skip to the next probe table’s record.
End loop
In the above logical activity diagram, the step highlighted in red is the important step where the hash semi right join meets the semi join requirement. In hash semi right join, if there are more than 1 record is available for the same value of the joining column(s) in the inner table, all those records will be skipped except anyone record getting inserted into the hash table. By this, displaying the same outer table record (in case of hits) again & again is being avoided and thus meet the requirement of semi join.
LITTLE-KNOWN FACTS TO BE REMEMBERED:
• /*+ HASH_SJ */ is the hint that can be used to impose this hash semi right join. But this hint has to be applied inside the subquery of the EXISTS or IN clause, not in the main query itself.
• From 10g version onwards, oracle can consider inner table as the hash table in imposing hash semi right join if either the number of records or the number of distinct values on the joining column(s) is lesser in inner table. The hash table and probe table was fixed in hash semi join till 9i. This has been overcome in an extended version of hash semi join which is named “hash right semi join” from 10g version onwards.
• An in-line view with NO_MERGE hint could be used to isolate the ill effect of DISTINCT keyword so the semi-join access paths would not be defeated. This is applicable for all type of semi-joins.
• In general (or atleast till Oracle9i), Oracle transforms a subquery with semi-join into a conventional equi-join if at all possible. Oracle does not consider “cost” when deciding whether or not to do this transformation. So Oracle can execute a query with EXISTS (or) IN clause either by opting for any semi-join access path or conventional join access path followed by an unique operation to remove duplicate rows if the transformation happens. Implementation of Hash Semi Right join has been getting improved in each Oracle version. So higher the version, Oracle may not be opting to do this transformation and just go with any semi-join access path if EXISTS (or) IN clause is used in the query. This is applicable for all type of semi-joins.
• In RAM, hash semi right join will be carried out only in the allocated memory space which is nothing but HASH_AREA_SIZE component of PGA.
• Only the inner table records will be inserted as the hash table in RAM and the outer table records will never be written into RAM. Hash function will be applied in the probe table (outer table here) only to locate the corresponding memory entry in the hash table to look for the matching entry from the inner table there.
• No column(s) from the subquery can be returned in the output.
• If the query contains DISTINCT clause, then Oracle cannot impose this semi-join though EXISTS (or) IN clause is mentioned in the query.
• If the query contains UNION set operator, then Oracle cannot impose this semi-join though EXISTS (or) IN clause is mentioned in the query.
• If the EXISTS (or) IN clause is part of an OR branch in the query, then Oracle cannot impose this semi-join.
• However this semi-join can be imposed in queries that contain OR clause(s) in the WHERE clause, just as long as the EXISTS (or) IN is not part of the OR.
• Even the operator, “=ANY” can be used to impose this semi-join apart from IN & EXISTS constructs.
• The statement must have a subquery in the IN (or) EXISTS clause in order to invoke this semi-join. It means, usual IN clause wherein hardcoded value(s) mentioned in R.H.S (Right Hand Side) of this clause cannot invoke this semi-join.
• This methodology is opted by Oracle only if a small inner table is semi-joined with a big outer table. So this is very successful when inner table is smaller and outer table is bigger. In this case, it outplays the hash semi join.
• If the inner table cannot be hashed in RAM in single pass (i.e., at one shot or one go), then a portion of the hash-table spills to disk(actually, TEMP tablespace will be used here to hold that spilled dataset from the inner table). When the hash table is probed by the outer table, the rows with join keys that match those parts of the in-memory hash table are joined immediately; the rest [of the outer table] are also written into TEMP tablespace and joined in the subsequent passes. The bigger inner table is, the smaller the proportion of it in RAM, the remaining data will be spilled into TEMP tablespace and have to go through the subsequent passes till it processes all the records spilled into TEMP tablespace from both these inner and outer tables. This slows down Hash Semi Right Join considerably and also makes the join non-scalable in this scenario.
ADVANTAGE:
• This is very successful when many records of the outer table doesn’t have the matching records in the inner table, only some records in the outer table has lots of matching records in the inner table, and both the tables are not properly indexed. In this scenario, it outperforms both nested loop semi join and hash semi join.
• If a query is the best candidate for hash semi right join, then this semi join can reduce logical reads, CPU time & elapsed time dramatically but will increase physical reads (with no harm).
• Still nested loop semi join will be the fastest way to retrieve the first matching record [since hash semi right join takes some time to build the hash table in RAM for the inner table as it applies hash function] but hash semi right join will be the fastest way to get all the matching records quickly when compared to nested loop semi join. In general, hash function (in hash semi right join) will perform better and more efficiently.
DISADVANTAGE:
• If hash semi right join is imposed in a query wherein if all the records in the outer table has lots of matching records in the inner table and the inner table is properly indexed, then it will behave badly than the nested loop semi join. The reason is, as per hash semi right join, all the records in the inner table will be hashed and thus unnecessarily waste time there instead of stopping once the first matching record is seen. In this scenario, it will be better if nested loop semi join is used.
• If the allocated space in RAM memory is not large enough to hold the entire hash table, Oracle will use the temporary tablespace, and then complete the join operation. If this join uses the temporary tablespace, then the execution time of the query will get affected. This scenario makes hash semi right join more non-scalable as it has to go through subsequent passes to join these spilled dataset (available in TEMP tablespace) from both these tables
HOW TO VERIFY:
How to verify whether Oracle follows hash semi right join or not while executing SQL. If a query follows this, then you will find similar execution plan like this,
EXAMPLE:
In order to understand how the design flaw of hash semi join has been overcome by hash semi right join, we will first discuss the example with the hash semi right join. Then we would discuss how it would behave badly if the same was done with hash semi join.
Create 2 tables.
One table is store the information about all the employees and inserts 6 records.
Another table is store the information of the sales done by the employees and inserts 9 records.
The tables will look like this,
DATA TABLE:
EMP:
Select a.empid, a.empname
from emp a
where exists (select 1 from sales b where b.empid = a.empid);
Assume, Oracle can hold 3 records at a time in the allocated memory space(defined by HASH_AREA_SIZE global parameter) in RAM.
For easy understanding, pls assume MOD function to the base 10 will be used as hash function here. In real world, the hash function would be much more complex and hard to decode it.
Case-I: (for hash semi right join)
========================
We will discuss what would happen if hash semi right join was imposed. You would see this behavior only from Oracle 10g as this semi join has been implemented from this version only. As per this join, sales is the hash table and emp is the probe table since the number of distinct values in joining column (empid) is lesser in sales table.
EMPTY HASH TABLE:
=================
1. Since SALES has less number of distinct values (on joining column) than EMP, SALES is considered as the hash table and EMP is considered as the probing table.
2. Since the memory can hold 3 records at a time, only 3 distinct values (on joining column) is available in SALES table, everything will get processed in a single pass.
3. For the first record in SALES, hash function is applied and it returns 1 as the hashed value















 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









