




 本文详细介绍了链表这一数据结构,包括单向链表、双向链表、循环链表、跳跃链表和自组织链表。阐述了链表在解决数组局限性方面的优势,讨论了各种链表的插入、删除操作及其时间复杂度,并特别分析了自组织链表的四种方法及其效率。
本文详细介绍了链表这一数据结构,包括单向链表、双向链表、循环链表、跳跃链表和自组织链表。阐述了链表在解决数组局限性方面的优势,讨论了各种链表的插入、删除操作及其时间复杂度,并特别分析了自组织链表的四种方法及其效率。
前言
在学习了C++基础以及算法复杂度分析方法(NP完整性笔者也没有理清,待到吃透再更)后,我们开始学习第一种数据结构——链表。在学习链表之前,相信熟练使用C语言的各位已经掌握了数组这一数据结构 。其有两个局限:
- 编译前就需要知道大小。
- 数组中的每个元素占据的内存单元数是相同的。
链表就不存在这些问题,所以它可以分散存储于内存的任何位置,对于双向链表,每一个节点都存有两个地址,分别存放上一个节点和下一个节点的地址。链表的实现方法很多,指针的灵活运用是最为常用的做法。
单向链表
一言以蔽之,单向链表包含两个数据成员:info,next。info用于存储用户需要的数据,next存储维持链表结构的数据成员。标准代码如下:
class IntSLLNode
{
public:
IntSLLNode()
{next = NULL;}
IntSLLNode(int i, IntSLLNode *in = NULL)
{
info = i;
next = in;
}
int info; //数据成员-存储用户信息。
IntSLLNode *next; //数据成员-存储下一节点指针。
}
这里的构造函数分别实现了用户没有指定参数,以及指定了数据成员而缺省下一节点指针信息与用户指定全部信息的情形。
常见的声明方式为:
IntSLLNode *p = new IntSLLNode(10); //创建头节点。
p->next = new IntSLLNode(8); //创建下一节点。
大家很容易分析上面的代码,如果继续创建,就需要重复写入p->next->next费时费力,所以需要其他方式访问链表中的节点(关于是否是尾节点,可以通过next是否为NULL来判断)。方法之一是保存头节点和尾节点的地址。(也可以通过添加指向上一节点和下一节点的指针来维护链表结构,但此处只介绍单向链表,故稍后讲解。)
class IntSLLNode {
public:
IntSLLNode() {
next = NULL;
}
IntSLLNode(int el, IntSLLNode *ptr = NULL) {
info = el; next = ptr;
}
int info;
IntSLLNode *next;
};
class IntSLList {
public:
IntSLList() {
head = tail = NULL;
}
~IntSLList();
int isEmpty() {
return head == NULL;
}
void addToHead(int); //从头部添加节点。
void addToTail(int); //从尾部添加节点。
int deleteFromHead(); // 删除头节点。
int deleteFromTail(); // 删除尾节点。
void deleteNode(int); //删除某一节点。
bool isInList(int) const; //查询是否存在节点。
void printAll() const; //打印。
private:
IntSLLNode *head, *tail; //注意:头节点和尾节点信息也由该结构维护。
}; //特地声明一个类来对链表进行维护。
相关的.h文件可以将其声明为如上形式,对于相关的函数代码可以在接下来的.c文件中实现:
//以下实现代码摘自C++数据结构与算法第四版。注意类的声明尽可能参照上面的标准,链表维护实现方式可以略有区别。
IntSLList::~IntSLList() {
for (IntSLLNode *p; !isEmpty(); ) {
p = head->next;
delete head;
head = p;
}
}
void IntSLList::addToHead(int el) {
head = new IntSLLNode(el,head);
if (tail == NULL)
tail = head;
}
void IntSLList::addToTail(int el) {
if (tail != NULL) { // if list not empty;
tail->next = new IntSLLNode(el);
tail = tail->next;
}
else head = tail = new IntSLLNode(el);
}
int IntSLList::deleteFromHead() {
int el = head->info;
IntSLLNode *tmp = head;
if (head == tail) // if only one node on the list;
head = tail = NULL;
else head = head->next;
delete tmp;
return el;
}
int IntSLList::deleteFromTail() {
int el = tail->info;
if (head == tail) { // if only one node on the list;
delete head;
head = tail = NULL;
}
else { // if more than one node in the list,
IntSLLNode *tmp; // find the predecessor of tail;
for (tmp = head; tmp->next != tail; tmp = tmp->next);
delete tail;
tail = tmp; // the predecessor of tail becomes tail;
tail->next = NULL;
}
return el;
}
void IntSLList::deleteNode(int el) {
if (head != NULL) // if non-empty list;
if (head == tail && el == head->info) { // if only one
delete head; // node on the list;
head = tail = NULL;
}
else if (el == head->info) { // if more than one node on the list
IntSLLNode *tmp = head;
head = head->next;
delete tmp; // and old head is deleted;
}
else { // if more than one node in the list
IntSLLNode *pred, *tmp;
for (pred = head, tmp = head->next; // and a non-head node
tmp != NULL&& !(tmp->info == el);// is deleted;
pred = pred->next, tmp = tmp->next);
if (tmp != NULL) {
pred->next = tmp->next;
if (tmp == tail)
tail = pred;
delete tmp;
}
}
}
bool IntSLList::isInList(int el) const {
IntSLLNode *tmp;
for (tmp = head; tmp != NULL && !(tmp->info == el); tmp = tmp->next);
return tmp != NULL;
}
void IntSLList::printAll() const {
for (IntSLLNode *tmp = head; tmp != NULL; tmp = tmp->next)
cout << tmp->info << " ";
cout << endl;
}
简而言之,对于单向链表尤其要注意头节点,尾节点相关操作以及单节点或没有节点的操作。对于单向链表的基本操作不外乎增(插入)删查改。这类编程基础知识请查阅任何一门数据结构资料,下面只提几个注意事项:
删除:注意链表为空的情形应当加以if语句进行相应判断,建议采用异常控制块的方法对删除操作进行保护,否则容易发生不可预知的内存错误。另外只有一个节点的情况,注意对head和tail设置为null。
关于删除和查找某个特定节点的大O复杂度:
(1+2+..+(n−1))/n=(n−1)n/2n=(n−1)/2(1+2+..+(n-1))/n=(n-1)n/2n=(n-1)/2(1+2+..+(n−1))/n=(n−1)n/2n=(n−1)/2
根据代码,复杂度取决于查询操作的for循环迭代次数,最好情况为头节点或链表为空O(1) ,最差情况为最后一个节点O(n)。因此我们计算平均复杂度即总操作数➗操作序列数=平均操作数从而计算出我们所需的复杂度,查找操作同理。
双向链表
为了解决删除中间节点而使用的遍历成本,可以对链表进行优化,使得每个节点存储两个指针,分别指向前后节点。
下面比较形象地描述了双向链表的特点:
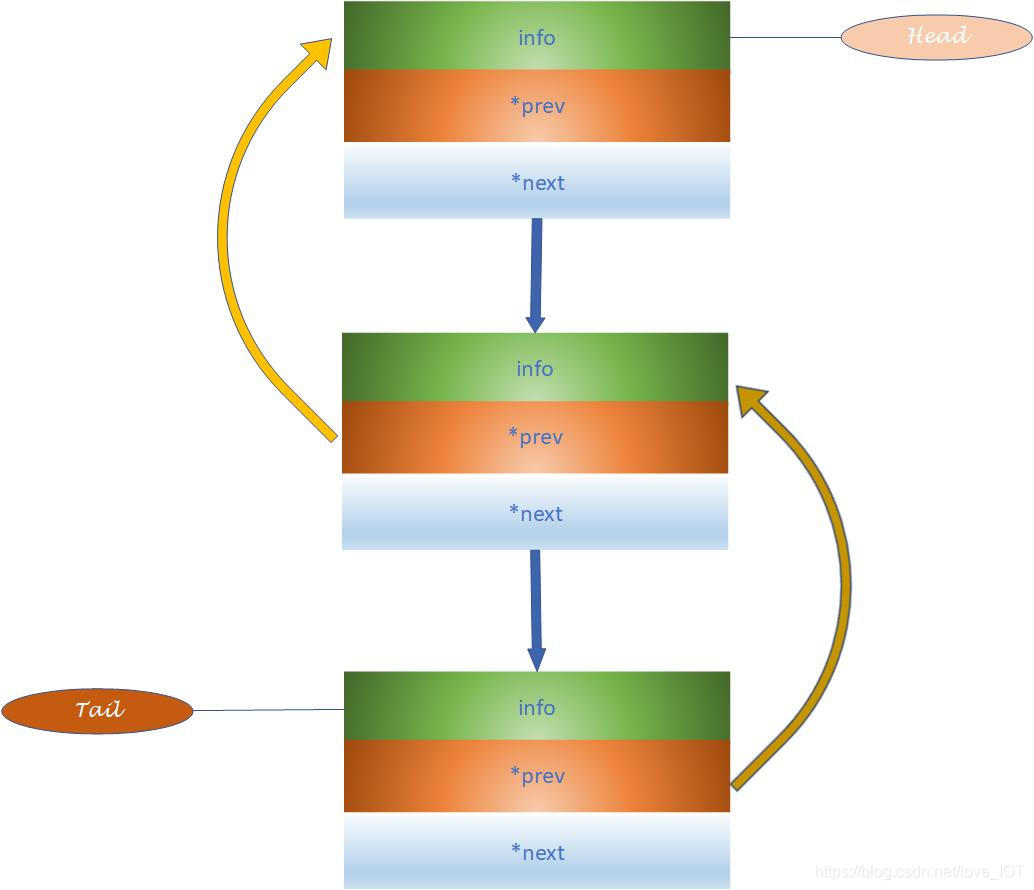
对比单向链表,维护双向链表的类成员函数中要多处理两个指针,因此会略微复杂。下面简单介绍处理双向列表的代码思路:
在非空队尾添加新的节点:
- 创建一个新的节点,并初始化数据成员,以及两个指针prev,next为
NULL。 - 将prev指针赋值为tail指针的值,令链表尾标识成为该节点的前驱节点。
- 将tail指针指向新创建的新节点,标志该节点为新的尾节点。
- 将前驱节点的next指针指向尾节点,完成操作。
非空双向链表删除队尾:
- 访问最后一个节点,并将tail指针指向它的前驱节点。
- 回收尾节点的空间。
- 将现在的tail节点的next指针设置为
NULL。
注意:请事先检查链表是否为空,如果为空请另行处理。另一种情况是单节点链表,head和tail指针最终都要设置为NULL。
循环链表
循环链表长度是有限的,每个节点都有后继节点。类似于单向链表,但不同的是循环链表不存在首尾节点,即首尾相连。形成一个圆环,通过一个current指针来访问循环链表。操作系统中,各进程依次占用时间片,即可以理解为一个循环链表。另一个与双向链表不同之处就是环链表只用一个tail指针来维护整个链表。
跳跃链表
链表有一个缺陷,即只能顺序查找,遍历整个链表直至找到或未找到。对链表排序是一个可行的方式。而跳跃链表则是一种非顺序查找方式,它是有序链表的一个变种。
我们用一个简单的图来表示跳跃链表的实际意义:
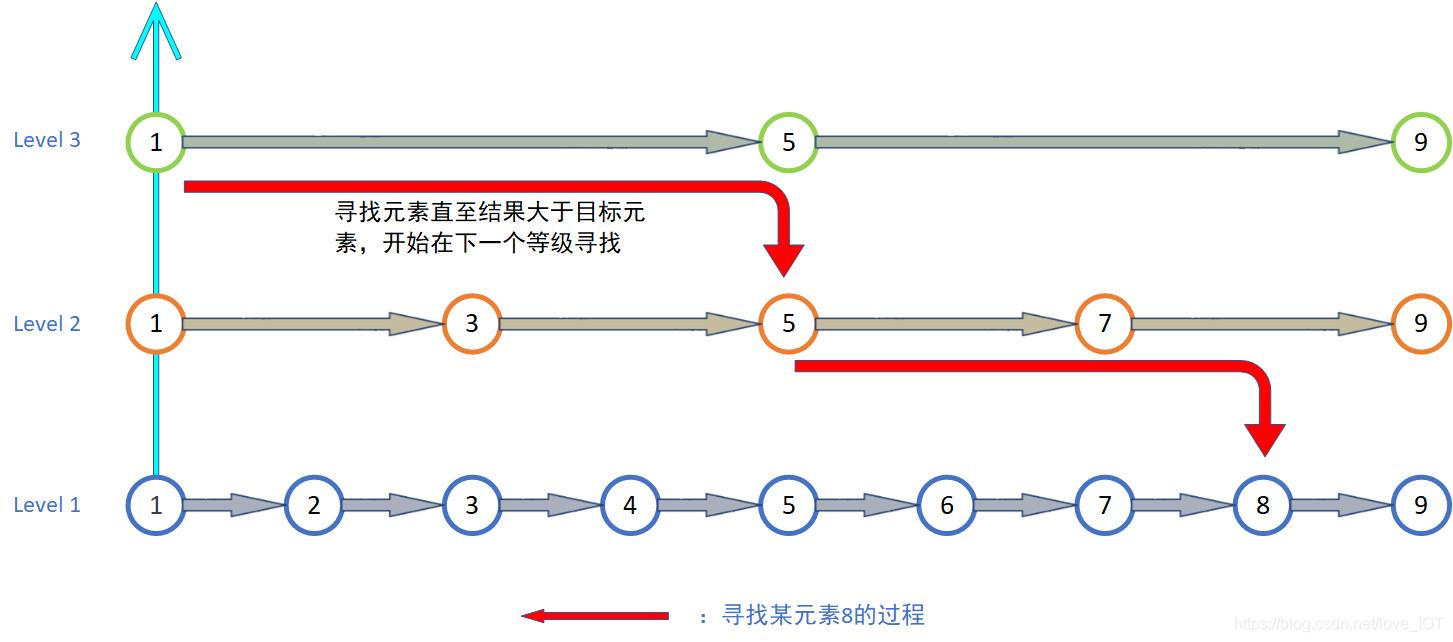
图中level1可以视为普通顺序链表,这里引入指针分级的概念,暂以log2nlog_2nlog2n作为分级的标准。如上图所示,顺序链表很容易看出找到元素8需要查找8次。复杂度O(n)。而跳跃链表的中心思想与二分查找有些类似,逐级通过最大跨度的查找逐渐缩小范围。其算法复杂度可表示为O(lgn)。一般来说,级的数量为Maxlevel=lgn+1Maxlevel=lgn+1Maxlevel=lgn+1。
如果需要对链表进行插入和删除就需要对级数以及新节点或者删除后的链表结构做动态调整。重点在于对新增或删除点的级操作,下面针对插入操作做一个讲解。假设Maxlevel=4且有15个元素很容易得到最接近的情况是log216=4log_216=4log216=4,所以只含有1个指针的元素有8个,含有2个指针的元素有4个,含有3个指针的元素有2个,含有4个指针的节点1个。根据概率统计,采用随机数的原理对链表进行插入:
| r | 被插入的节点的级 |
|---|---|
| 15 | 4 |
| 13-14 | 3 |
| 9-12 | 2 |
| 1-8 | 1 |
通过确定被插入节点的级可以将节点放到合适的位置,请结合图示进行理解。
自组织链表
动态组织链表的方法,即将查找过的或者被检索期望高的元素向前移动,常见的自组织链表有四种形式:
1. 前移法:
在找到需要的元素之后,就把它放到链表的开头。
2. 换位法:
在找到需要的元素之后,只要该元素不在链表开头,就将该元素与其前驱元素调换位置。
3. 计数法:
增加数据域来记录每个元素的被访问次数,每次访问元素后按访问次数重新排列该元素的位置。
4. 排序法:
根据元素的自身属性,对链表进行排序。
注意:自组织链表的要点是每次查找或者新增操作都会对链表进行自组织。例如处理数据流:ACBC,按照前移法产生的链表:A➡AC➡ACB➡CAB。如果新增的节点在链表中不存在,则补充到节点末尾。如果存在,则按照四种方法相应处理。
对以上四种方法的效率分析通常通过与最佳静态排序的效率进行对比。在最佳静态排序中,所有数据都根据在数据体中出现的频率排序,因而只适用于查找,不用于新增。此方法需要将要处理的对象扫描两次,第一次建立链表,第二次进行查找。
根据实验可以得出计数法和前移法的开销最多可达最佳静态排序法的两倍,换位法的开销接近前移法。根据摊销分析,前移法与最佳静态排序的开销关系可以得到验证。
运用摊销分析的证明:
对于包含相同元素的两个链表,逆序定义为其中的两个元素在两个链表中的前后位置不同。例如对于链表(A,B,C,D)和(C,B,D,A)而言逆序数量为4,分别为(C,A),(B,A),(D,A),(C,B)。摊销成本定为实际成本与前后逆序数目之差的和:
amCost(x)=cost(x)+[inversionbeforeaccess(x)−inversionbeforeaccess(x)]amCost(x)=cost(x)+[inversionbeforeaccess(x)-inversionbeforeaccess(x)]amCost(x)=cost(x)+[inversionbeforeaccess(x)−inversionbeforeaccess(x)]
为了得到结论,考虑最佳链表OL=(A,B,C,D)和前移链表MTF=(C,B,D,A)。对元素的访问经常打破逆序平衡。设displaced(x)是MTF中在x之前但OL中在x之后的元素的数目。可以得到
displaced( A)=3
displaced( B)=1
displaced( C)=0
displaced( D)=0
设posMTF(x)pos_{MTF}(x)posMTF(x)是x在MTF中的当前位置,则posMTF(x)−1−displaced(x)pos_{MTF}(x)-1-displaced(x)posMTF(x)−1−displaced(x)就是在两个链表中都在x之前的元素的数目对于本例,D元素对应的值是2,其他元素是0。访问x元素并将其移到MTF的前面。就会产生posMTF(x)−1−displaced(x)pos_{MTF}(x)-1-displaced(x)posMTF(x)−1−displaced(x)个新逆序。同时消除了displaced(x)个其他的逆序。
所以访问x的摊销时间可以表示为:
amCost(x)=posMTF(x)+posMTF(x)−1−displaced(x)−displaced(x)=2(posMTF(x)−displaced(x))−1amCost(x)=pos_{MTF}(x)+pos_{MTF}(x)-1-displaced(x)-displaced(x)=2(pos_{MTF}(x)-displaced(x))-1amCost(x)=posMTF(x)+posMTF(x)−1−displaced(x)−displaced(x)=2(posMTF(x)−displaced(x))−1
对于上式cost(x)=posMTF(x)cost(x)=pos_{MTF}(x)cost(x)=posMTF(x)。如果考虑对A进行访问,则MTF将转化为(A,C,B,D),解得amcost(a)=1amcost(a)=1amcost(a)=1。同理amcost(b)=1,amcost(c)=1,amcost(d)=5amcost(b)=1,amcost(c)=1,amcost(d)=5amcost(b)=1,amcost(c)=1,amcost(d)=5。
由于这两个链表中在x之前相同元素数不能超过OL中之前的元素总数。所以posMTF(x)−1−displaced(x)≤posOL(x)−1pos_{MTF}(x)-1-displaced(x)≤pos_{OL}(x)-1posMTF(x)−1−displaced(x)≤posOL(x)−1。
等效为amcost(x)≤2posOL(x)−1amcost(x)≤2pos_{OL}(x)-1amcost(x)≤2posOL(x)−1。
由此证明访问MTF中元素x的摊销成本比在OL上的访问开销超出了posOL(x)−1pos_{OL}(x)-1posOL(x)−1
需要强调的是,对于单次操作,自组织方法相对于静态排序法增加了开销,对于足够多的访问中,平均每次访问花费的时间最多为2posOL(x)−12pos_{OL}(x)-12posOL(x)−1对于包含大量操作时,对于高频率访问,自组织链表的优势才能凸显。对于次数较少的操作则会造成负担。
稀疏表
我们时常通过二维数组记录800名学生25门课程的成绩。但存在一些情况,例如每名学生只能选择8门课且选课随机,那么不仅是对数组的空间极大地浪费,不论是查找还是新增都会对数组的使用效率造成麻烦。
这里提供一种高效的链表
struct Node
{
int StuId; //学生
int ClassId; //课程号
Node *nextStuId; //指向下一个学生
Node *nextClassId; //指向下一个课程
}
这里将二维数组引申为二维链表。即可以通过课程或者学生来索引节点,避免了空间的浪费以及查询效率的低下。具体效果如下:
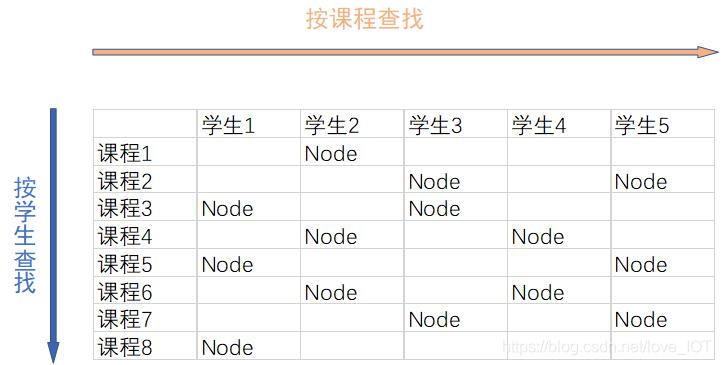
对于学生没有选择的课程(或者课程没有学生选择),可以不占用内存,而根据指针索引可以很明显地避免空间浪费以及查找效率。

















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









