








 超级会员免费看
超级会员免费看

 RapidFuzz是一个C++和Python的字符串匹配库,提供多种相似性计算方法,如Simple Ratio、Partial Ratio等。相比FuzzyWuzzy,RapidFuzz具有MIT许可、更丰富的度量、更快的速度以及错误修复等优势。支持通过pip、conda或源码安装,适用于Windows、MacOS和Linux等平台。
RapidFuzz是一个C++和Python的字符串匹配库,提供多种相似性计算方法,如Simple Ratio、Partial Ratio等。相比FuzzyWuzzy,RapidFuzz具有MIT许可、更丰富的度量、更快的速度以及错误修复等优势。支持通过pip、conda或源码安装,适用于Windows、MacOS和Linux等平台。

文章目录
关于 RapidFuzz
- github : https://github.com/maxbachmann/RapidFuzz#description
- 官网: https://maxbachmann.github.io/RapidFuzz/
RapidFuzz是一个用于Python和C++的快速字符串匹配库,它使用FuzzyWuzzy的字符串相似性计算。
然而,有几个方面使RapidFuzz与FuzzyWuzzy不同:
1、RapidFuzz 是 MIT 授权的,所以它可以用于任何你想为你的项目选择的许可证,而你在使用FuzzyWuzzy时被迫采用GPL许可证;
2、它提供了许多字符串度量,如 hamming 或 jaro_winkler,这些FuzzyWuzzy中都没有;
3、它主要是用C++编写的,除此之外,它还进行了许多算法改进,使字符串匹配更快,同时仍然提供相同的结果。有关详细的基准测试,请查看文档: https://maxbachmann.github.io/RapidFuzz/
4、修复了partial_ratio实现中的多个错误
FuzzyWuzzy : https://github.com/seatgeek/fuzzywuzzy
安装
依赖:
- Python 3.7 or later
- On Windows the Visual C++ 2019 redistributable is required
方式一:pip
RapidFuzz can be installed with pip the following way:
pip install rapidfuzz
There are pre-built binaries (wheels) of RapidFuzz for MacOS (10.9 and later), Linux x86_64 and Windows.
Wheels for armv6l (Raspberry Pi Zero) and armv7l (Raspberry Pi) are available on piwheels.
✖️ failure “ImportError: DLL load failed”
If you run into this error on Windows the reason is most likely, that the Visual C++ 2019 redistributable is not installed, which is required to find C++ Libraries (The C++ 2019 version includes the 2015, 2017 and 2019 version).
方式二: conda
RapidFuzz can be installed with conda:
conda install -c conda-forge rapidfuzz
方式三:git
RapidFuzz can be installed directly from the source distribution by cloning the repository. This requires a C++17 capable compiler.
git clone --recursive https://github.com/maxbachmann/rapidfuzz.git
cd rapidfuzz
pip install .
使用
下面展示一些简单的用法,更详细的方法可见文档:https://maxbachmann.github.io/RapidFuzz/Usage/index.html 。
Scorers
Scorers in RapidFuzz can be found in the modules fuzz and string_metric.
Simple Ratio
> fuzz.ratio("this is a test", "this is a test!")
96.55171966552734
Partial Ratio
> fuzz.partial_ratio("this is a test", "this is a test!")
100.0
Token Sort Ratio
> fuzz.ratio("fuzzy wuzzy was a bear", "wuzzy fuzzy was a bear")
90.90908813476562
> fuzz.token_sort_ratio("fuzzy wuzzy was a bear", "wuzzy fuzzy was a bear")
100.0
Token Set Ratio
> fuzz.token_sort_ratio("fuzzy was a bear", "fuzzy fuzzy was a bear")
83.8709716796875
> fuzz.token_set_ratio("fuzzy was a bear", "fuzzy fuzzy was a bear")
100.0
Process
Process 模块 将 字符串与 字符串列表 进行比较。
这通常比直接从Python中使用 scorers 更具性能。
以下是关于RapidFuzz中使用 processors 的一些示例:
> from rapidfuzz import process, fuzz
> choices = ["Atlanta Falcons", "New York Jets", "New York Giants", "Dallas Cowboys"]
> process.extract("new york jets", choices, scorer=fuzz.WRatio, limit=2)
[('New York Jets', 100, 1), ('New York Giants', 78.57142639160156, 2)]
> process.extractOne("cowboys", choices, scorer=fuzz.WRatio)
("Dallas Cowboys", 90, 3)
processors 详细文档可见: https://maxbachmann.github.io/RapidFuzz/Usage/process.html
Benchmark
下面的 benchmark 给出了RapidFuzz和FuzyWuzzy之间的快速性能比较。
更多字符串metrics 的 benchmarks 可见文档:https://maxbachmann.github.io/RapidFuzz
对于这个简单的比较,我生成了一个长度为 10 的 10.000 个字符串的列表,并将其与该列表中的100个元素的样本进行了比较:
words = [
"".join(random.choice(string.ascii_letters + string.digits) for _ in range(10))
for _ in range(10_000)
]
samples = words[:: len(words) // 100]
第一个 benchmark 比较了FuzzyWuzzy和RapidFuzz中的scorers ,在直接从Python中使用时的性能,方法如下:
for sample in samples:
for word in words:
scorer(sample, word)
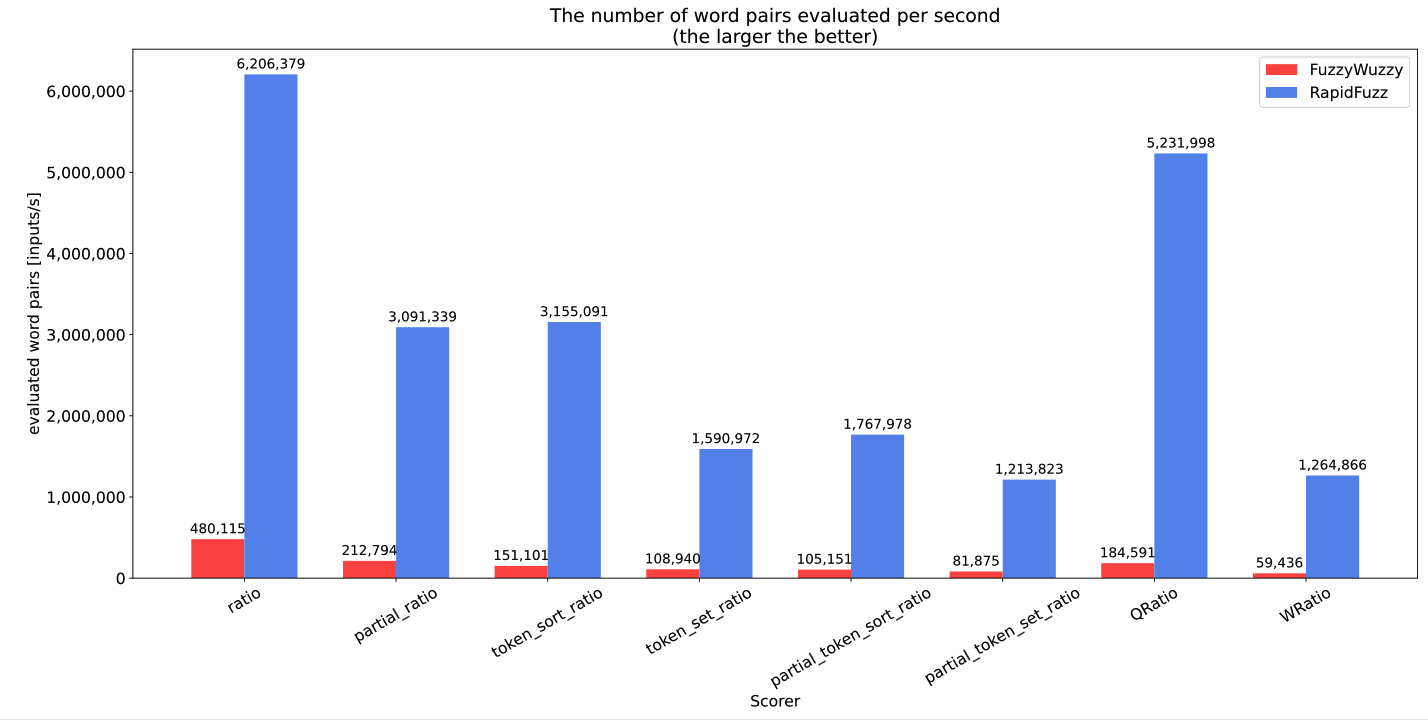
下图显示了每个 scorers 每秒处理的元素数量。
不同的 scorers 之间有很大的表现差异。
然而,在RapidFuzz中,每个scorers 都更快
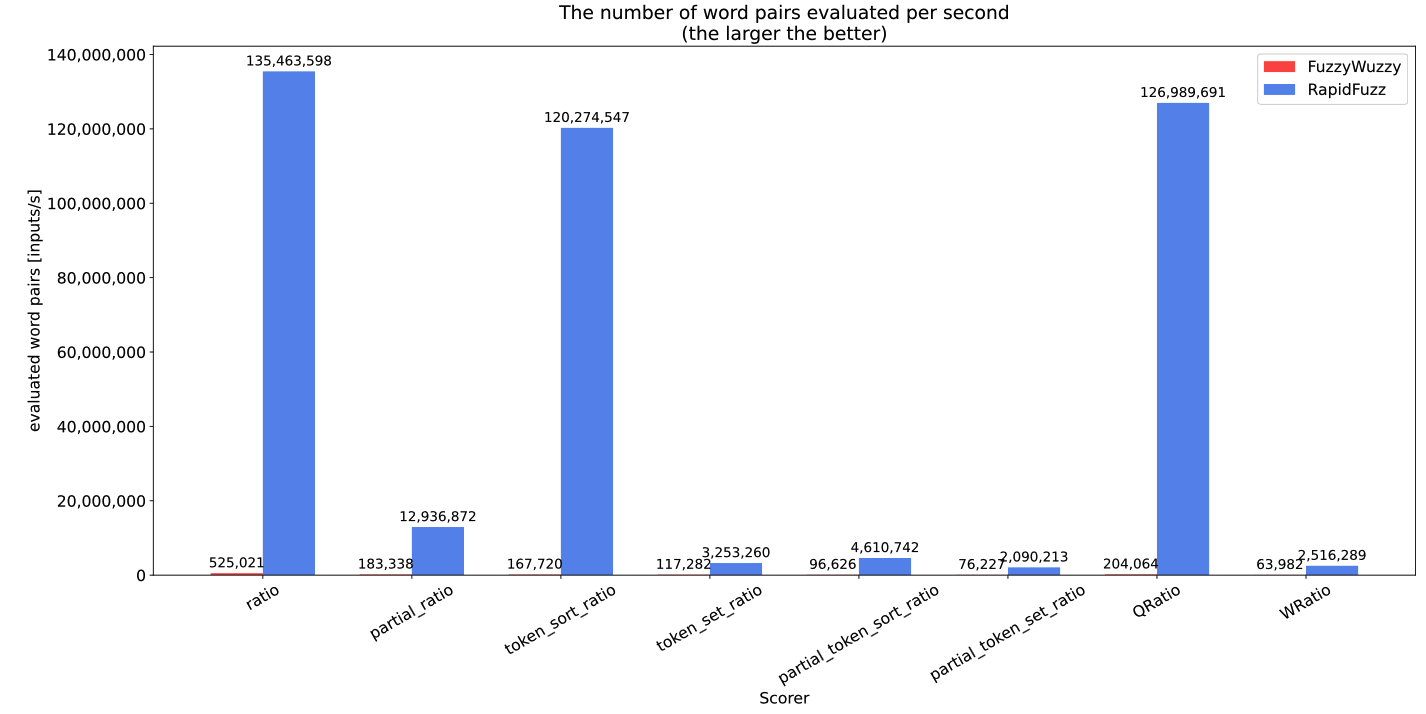
第二个benchmark 以以下方式 将 scorers 与 cdist 结合使用时的性能进行比较:
cdist(samples, words, scorer=scorer)
下图显示了每个记分器每秒处理的元素数量。
在RapidFuzz中,通过像 cdist 这样的处理器使用 scorers 要比直接使用它快得多。
这就是为什么应该尽可能使用它们的原因。
2023-04-04(二)

















 3898
3898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









