







文章目录
关于 联邦学习
相关教程
- KnowingAI知智: 什么是联邦学习(Federated Learning)?【知多少】 (1min)
https://www.bilibili.com/video/BV1ub4y1Z7aM/ - 王树森:技术角度讲联邦学习 (37min)
https://www.bilibili.com/video/BV1YK4y1G7jw?p=7
https://www.youtube.com/watch?v=STxtRucv_zo
https://github.com/wangshusen/DeepLearning/blob/master/Slides/14_Parallel_4.pdf 课件
相关论文
- Communication-Efficient Learning of Deep Networks from Decentralized Data
https://arxiv.org/abs/1602.05629
https://proceedings.mlr.press/v54/mcmahan17a - Federated Optimization:Distributed Optimization Beyond the Datacenter
https://arxiv.org/abs/1511.03575 - On the Convergence of FedAvg on Non-IID Data
https://arxiv.org/abs/1907.02189
第一个 证明了 FedAvg 收敛 而且 不需要独立同分布的假设
联邦学习 起源:
2016 年,Google 为了解决安卓系统更新问题,提出让用户在自己的设备中训练模型,以上传模型参数,取代直接上传个人数据;保证了个人数据的私密,这是联邦学习的初衷。
目标:解决数据的协作和隐私问题,这个概念比较新,仍在发展中。
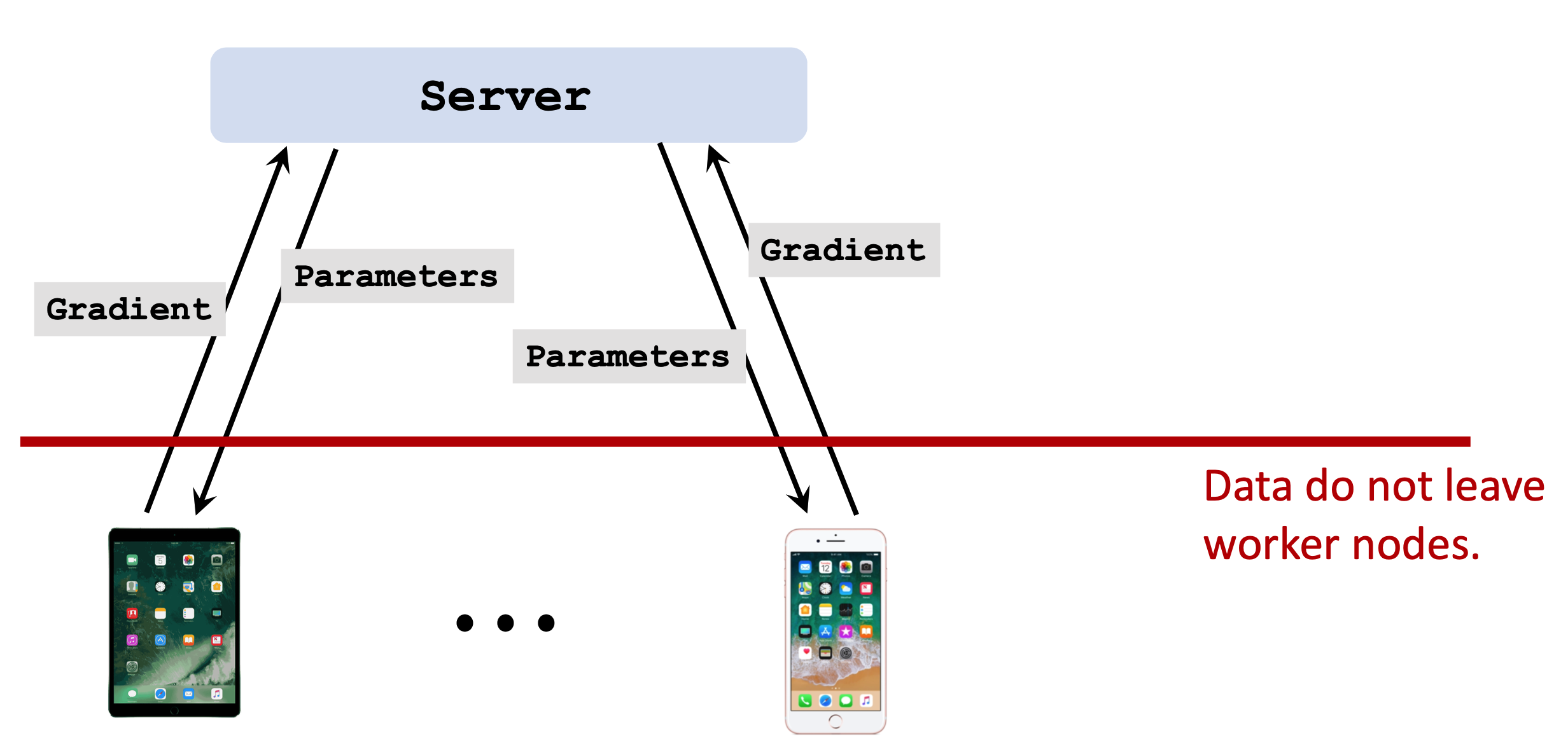
联邦学习,本质就是分布式机器学习。
传递的是模型的梯度和参数。
相比传统分布式学习
- 联邦学习 的 worker 不受 server 绝对控制;
- worker 设备各不相同,连接不稳定,计算性能不同;
- 通信代价 远大于 计算代价;
- 联邦学习的数据并非独立同分布;已有的减少通讯次数的算法,不再适用;
- 不同用户数据量不同,节点负载不平衡;没法做负载均衡
由于第2、3条,设计联邦算法,最重要的是减少通信次数。
分类
- 横向联邦学习(特征对齐的联邦学习): 如果联邦学习的业务相似,数据特征重叠多,样本重叠少(如都是银行),可以上传模型参数,在服务器中 聚合,更新模型。再将最新的参数下放,完成模型效果的提升。
- 纵向联邦学习(样本对齐的联邦学习):如果参与者的数据中,样本重叠多,特征重叠少(如不同业务),就需要先将样本对齐,由于不能直接比对,需要加密算法的帮助,让参与者在不暴露不重叠的样本的情况下,找出相同的样本后,联合她们的特征进行学习。
- 联邦迁移学习:如果样本和数据,重合的都不多,希望利用数据,提升模型能力,就需要将参与者的模型 和 数据 迁移到同一空间中运算。

关于 Flower
- 官网: https://flower.dev
- github : https://github.com/adap/flower
- docs : https://flower.dev/docs/
- blog : https://flower.dev/blog/
Hugging + Flower
- Federated Learning using Hugging Face and Flower
https://huggingface.co/blog/fl-with-flower - Federated HuggingFace Transformers using Flower and PyTorch
https://github.com/adap/flower/tree/main/examples/quickstart_huggingface
安装 Flower
Via PyTorch
pip install flwr torch torchvision
Via HuggingFace
pip install datasets evaluate flwr scikit-learn torch transformers
使用 - PyTorch
1、client.py
from collections import OrderedDict
import warnings
import flwr as fl
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.transforms import Compose, ToTensor, Normalize
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR10
# #############################################################################
# Regular PyTorch pipeline: nn.Module, train, test, and DataLoader
# #############################################################################
warnings.filterwarnings("ignore", category=UserWarning)
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class Net(nn.Module):
"""Model (simple CNN adapted from 'PyTorch: A 60 Minute Blitz')"""
def __init__(self) -> None:
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.fc3(x)
def train(net, trainloader, epochs):
"""Train the model on the training set."""
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for _ in range(epochs):
for images, labels in trainloader:
optimizer.zero_grad()
criterion(net(images.to(DEVICE)), labels.to(DEVICE)).backward()
optimizer.step()
def test(net, testloader):
"""Validate the model on the test set."""
criterion = torch.nn.CrossEntropyLoss()
correct, total, loss = 0, 0, 0.0
with torch.no_grad():
for images, labels in testloader:
outputs = net(images.to(DEVICE))
loss += criterion(outputs, labels.to(DEVICE)).item()
total += labels.size(0)
correct += (torch.max(outputs.data, 1)[1] == labels).sum().item()
return loss / len(testloader.dataset), correct / total
def load_data():
"""Load CIFAR-10 (training and test set)."""
trf = Compose([ToTensor(), Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = CIFAR10("./data", train=True, download=True, transform=trf)
testset = CIFAR10("./data", train=False, download=True, transform=trf)
return DataLoader(trainset, batch_size=32, shuffle=True), DataLoader(testset)
# #############################################################################
# Federating the pipeline with Flower
# #############################################################################
# Load model and data (simple CNN, CIFAR-10)
net = Net().to(DEVICE)
trainloader, testloader = load_data()
# Define Flower client
class FlowerClient(fl.client.NumPyClient):
def get_parameters(self, config):
return [val.cpu().numpy() for _, val in net.state_dict().items()]
def set_parameters(self, parameters):
params_dict = zip(net.state_dict().keys(), parameters)
state_dict = OrderedDict({k: torch.tensor(v) for k, v in params_dict})
net.load_state_dict(state_dict, strict=True)
def fit(self, parameters, config):
self.set_parameters(parameters)
train(net, trainloader, epochs=1)
return self.get_parameters(config={}), len(trainloader.dataset), {}
def evaluate(self, parameters, config):
self.set_parameters(parameters)
loss, accuracy = test(net, testloader)
return float(loss), len(testloader.dataset), {"accuracy": float(accuracy)}
# Start Flower client
fl.client.start_numpy_client(server_address="127.0.0.1:8080", client=FlowerClient())
2、server.py
import flwr as fl
# Start Flower server
fl.server.start_server(
server_address="0.0.0.0:8080",
config=fl.server.ServerConfig(num_rounds=3),
)
使用 - HuggingFace
1、client.py
import random
from collections import OrderedDict
import flwr as fl
import torch
from datasets import load_dataset, load_metric
from torch.utils.data import DataLoader
from transformers import (
AdamW,
AutoModelForSequenceClassification,
AutoTokenizer,
DataCollatorWithPadding,
)
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def load_data():
"""Load IMDB data (training and eval)"""
raw_datasets = load_dataset("imdb")
raw_datasets = raw_datasets.shuffle(seed=42)
# remove unnecessary data split
del raw_datasets["unsupervised"]
tokenizer = AutoTokenizer.from_pretrained("albert-base-v2")
# random 10 samples
population = random.sample(range(len(raw_datasets["train"])), 10)
tokenized_datasets = raw_datasets.map(
lambda examples: tokenizer(examples["text"], truncation=True), batched=True
)
tokenized_datasets["train"] = tokenized_datasets["train"].select(population)
tokenized_datasets["test"] = tokenized_datasets["test"].select(population)
tokenized_datasets = tokenized_datasets.remove_columns("text")
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
trainloader = DataLoader(
tokenized_datasets["train"],
shuffle=True,
batch_size=32,
collate_fn=data_collator,
)
testloader = DataLoader(
tokenized_datasets["test"], batch_size=32, collate_fn=data_collator
)
return trainloader, testloader
def train(net, trainloader, epochs):
optimizer = AdamW(net.parameters(), lr=5e-5)
net.train()
for _ in range(epochs):
for batch in trainloader:
batch = {k: v.to(DEVICE) for k, v in batch.items()}
outputs = net(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
def test(net, testloader):
metric = load_metric("accuracy")
loss = 0
net.eval()
for batch in testloader:
batch = {k: v.to(DEVICE) for k, v in batch.items()}
with torch.no_grad():
outputs = net(**batch)
logits = outputs.logits
loss += outputs.loss.item()
predictions = torch.argmax(logits, dim=-1)
metric.add_batch(predictions=predictions, references=batch["labels"])
loss /= len(testloader.dataset)
accuracy = metric.compute()["accuracy"]
return loss, accuracy
net = AutoModelForSequenceClassification.from_pretrained(
"albert-base-v2", num_labels=2
).to(DEVICE)
trainloader, testloader = load_data()
# Flower client
class IMDBClient(fl.client.NumPyClient):
def get_parameters(self, config):
return [val.cpu().numpy() for _, val in net.state_dict().items()]
def set_parameters(self, parameters):
params_dict = zip(net.state_dict().keys(), parameters)
state_dict = OrderedDict({k: torch.Tensor(v) for k, v in params_dict})
net.load_state_dict(state_dict, strict=True)
def fit(self, parameters, config):
self.set_parameters(parameters)
print("Training Started...")
train(net, trainloader, epochs=1)
print("Training Finished.")
return self.get_parameters(config={}), len(trainloader), {}
def evaluate(self, parameters, config):
self.set_parameters(parameters)
loss, accuracy = test(net, testloader)
return float(loss), len(testloader), {"accuracy": float(accuracy)}
# Start client
fl.client.start_numpy_client(server_address="127.0.0.1:8080", client=IMDBClient())
2、server.py
Copy
import flwr as fl
# Start server
fl.server.start_server(
server_address="0.0.0.0:8080",
config=fl.server.ServerConfig(num_rounds=3),
)
2023-04-07


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









