







转载自:
- 苹果M1统一内存架构真的很厉害吗?从AMD APU的名存实亡谈起(上)
https://www.eet-china.com/news/202108190817.html - 苹果M1统一内存架构真的很厉害吗?稀松平常的UMA(下)
https://www.eet-china.com/news/202109080900.html
苹果M1芯片发布之际,在大众间普及了一个叫UMA(Unified Memory Architecture)的概念——这个词主要用以形容,M1平台之上的RAM内存,面向CPU和GPU等不同的处理器时,采用统一可访问的内存池:如此一来M1的各组成部分不需要像传统方案那样,在多个内存池之间来回复制数据。
这里UMA的基本假设是,传统的CPU和GPU虽然位于同一个SoC芯片上,但它们对于内存的不同访问习惯、数据结构,导致它们虽然使用相同的内存RAM,但其存取空间仍然是分开的。
而M1则打破了这种界限,提升了带宽、延迟和性能表现。当然这种“打破”是苹果和媒体的宣传。
事实上,UMA这个词也有挺久的历史了,英伟达、AMD等都做过宣传。
而且似乎在不同语境下,其含义是不一样的(比如维基百科将UMA等同于集成GPU;且UMA似有各种不同实现方式)。
这也给苹果M1的UMA是否真的领先,打了个问号。
我们不打算去追溯UMA究竟表示什么——不过无论如何,UMA都基于异构计算。
所谓异构计算,也就是把CPU、GPU、NPU、FPGA等通用、专用处理器集成到一起,大家协同计算、各司其职。
异构计算是后摩尔时代的基本趋势。
现在异构计算已经不新鲜了,因为如今遍地都是异构计算芯片,手机、PC的处理器普遍如此。
不过十多年前,异构计算还是相当新潮的。而AMD是提异构计算比较早且积极的选手。
对PC处理器熟悉的同学应该知道AMD有个产品线叫APU:我们现在对APU的大致理解,应该是把CPU、GPU集成到同一颗芯片上的处理器产品。
在这个时代,这种思路也太过稀松平常了。Intel、苹果、高通、Arm还有谁不是这么做的?
但在AMD提出Fusion项目的2006年,这可是个比较有趣的思路——当年即便是所谓的“集成显卡”也还都是在主板上单独的芯片。

APU是早践行了异构计算的处理器产品,而且也比苹果早很多年尝试去实现UMA——至于是否成功那是另一回事。现在的APU可能早就没了当初的使命。
本文分成上下篇来谈谈AMD当年提出的APU架构理念,以及到如今的苹果M1,世界又发生了怎样的变化;并尝试粗看看苹果M1的UMA有多大价值。
APU的历史,与推土机的渊源
AMD早年提出APU这个概念是有其历史原因的。
我们在《PC处理器市场在变天:Intel的王者宝座还能坐多久?》一文中曾详细谈到过AMD过去十多年,在技术上走过一条长长的弯路。
在Zen架构出现以前,AMD一直在做一种叫Bulldozer推土机的处理器架构。
这种架构的一大特点是,每两个处理器核心共享一个浮点运算单元(每两个核心组成一个模块-module)。
也就是说每一个推土机模块(module),对整数运算来说是2个核心,而对浮点运算而言有时是1个核心,有时又可以算2个核心。
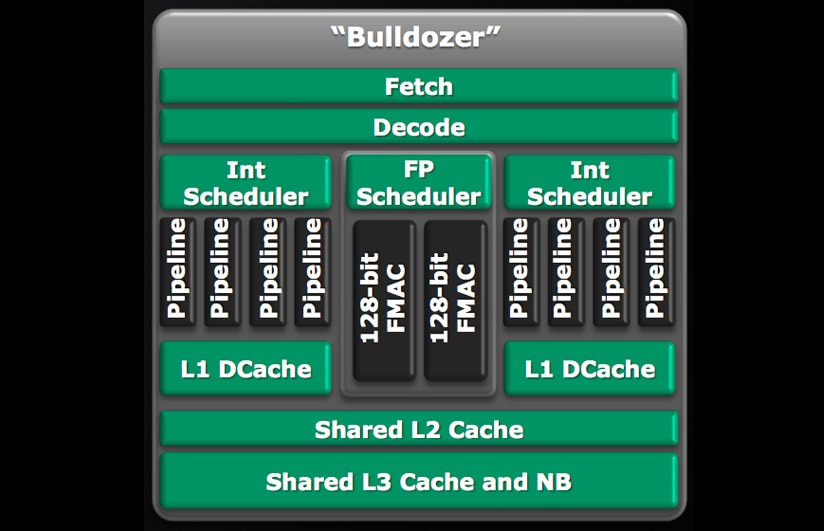
1个推土机模块
AMD当年表示,之所以采用这样的核心设计,是因为大部分操作系统工作都是基于整数运算;
而浮点运算日常没那么重要——真正需要浮点性能的时候,让GPU来干就行了。(好像和早年高通Kryo的思路完全相反)
我们现在当然知道,AMD推土机架构是彻彻底底地失败了。
不过如果顺着AMD当年的这个思路去想,AMD收购了ATI之后手握CPU、GPU两大资源。
那么搞个CPU、GPU融合的架构出来,矢量、浮点这些计算就可以欢乐地交给GPU去完成了。
完全不难想象当年的推土机CPU架构,可能就是为APU Fusion这个概念而生的。
事实上,AMD Fusion项目是2006年就提出的——AMD也是在这一年收购的ATI。
当时AMD表示要开发一种SoC芯片,将CPU和GPU集成到一颗die上。
不过要把CPU、GPU以当年的45nm工艺放在一起,难度还是相当大的。
所以第一颗APU问世已经是2011年的事情了。推土机CPU也是2011年发布的。
这套技术逻辑,感觉还是相当的圆满——至少从理论上来看是如此。
当年亦有分析师提出,“APU”这个概念恰是因为AMD在CPU市场上表现越来越差,推土机性能也远远落后于Intel同时代产品,所造出来的一个东西。
AMD期望藉由APU的新概念,来实现市场的突破。
这个观点可能也是有道理的,但实际上推土机的问世,比APU概念的诞生至少晚了5年。
所以我们更倾向于认为,APU是AMD一早就预备推广的一种技术。
APU生态,与HSA联盟的建立
AMD在2010年发布的一份APU技术白皮书中,大肆夸赞了APU在技术上的独到之处。
现在看来CPU+GPU的设定并没有什么可吹的,但这在当年也算是个壮举。
而且APU也不只是把CPU和GPU放在一起这么单纯,毕竟前文提到了AMD是期望让GPU在日常工作中也发挥作用的,而不只是充当图形计算加速器。
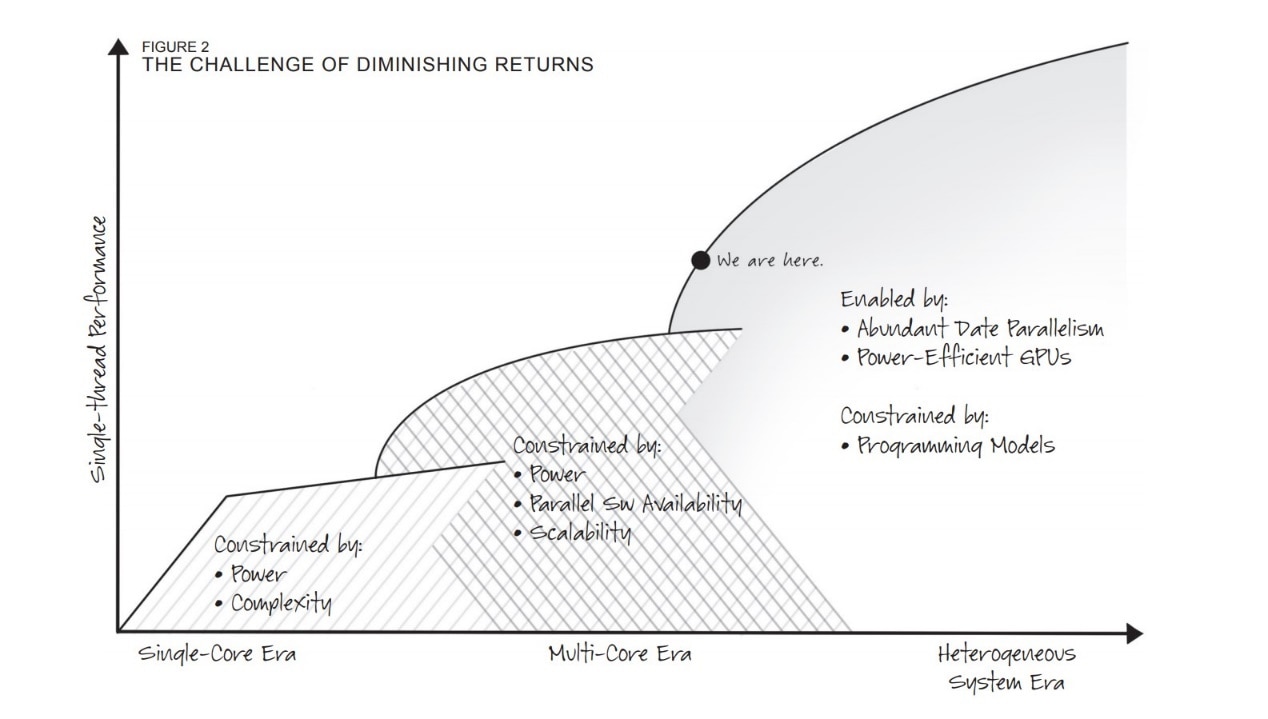
来源: APU 101: All about AMD Fusion Accelerated Processing Units
在理念宣传上,AMD画过一张图。AMD认为,处理器设计造成的性能提升,历史上分成了三个阶段,如上图所示。
这三个阶段分别是单核时期、多核时期,以及异构系统时期。
这种划分也算比较前瞻地谈到了未来各种专用处理器或单元对于行业的变革:我们现在身处的时代的确践行了这个理念。
AMD最初提APU一词的时候就谈到GPU之类的矢量处理器,对于大型数据集以及密集型数值计算任务是非常适用的;但对于很多问题来说,CPU也是不可或缺的。
异构计算融合CPU、CPU以及更多处理器的长处,实现更优的性能和效率表现。
当年的确还没有“核显”的概念,顶多就是“集显”IGP。
而且PC历史上的IGP性能孱弱,只用于解决最基本的图形计算问题。
IGP是独立存在于PCB板上的芯片,与内存通讯要通过CPU和PCIe总线,也存在高延迟、低效的问题。
AMD在早期APU宣传中也会特别提APU架构的速度比PCIe 2.0快4倍(如下图)。
另外AMD自然也不忘说独立显卡对于某些场景的通用计算(GPGPU)不够高效,尤其表现在CPU到GPU的PCIe数据搬迁上。
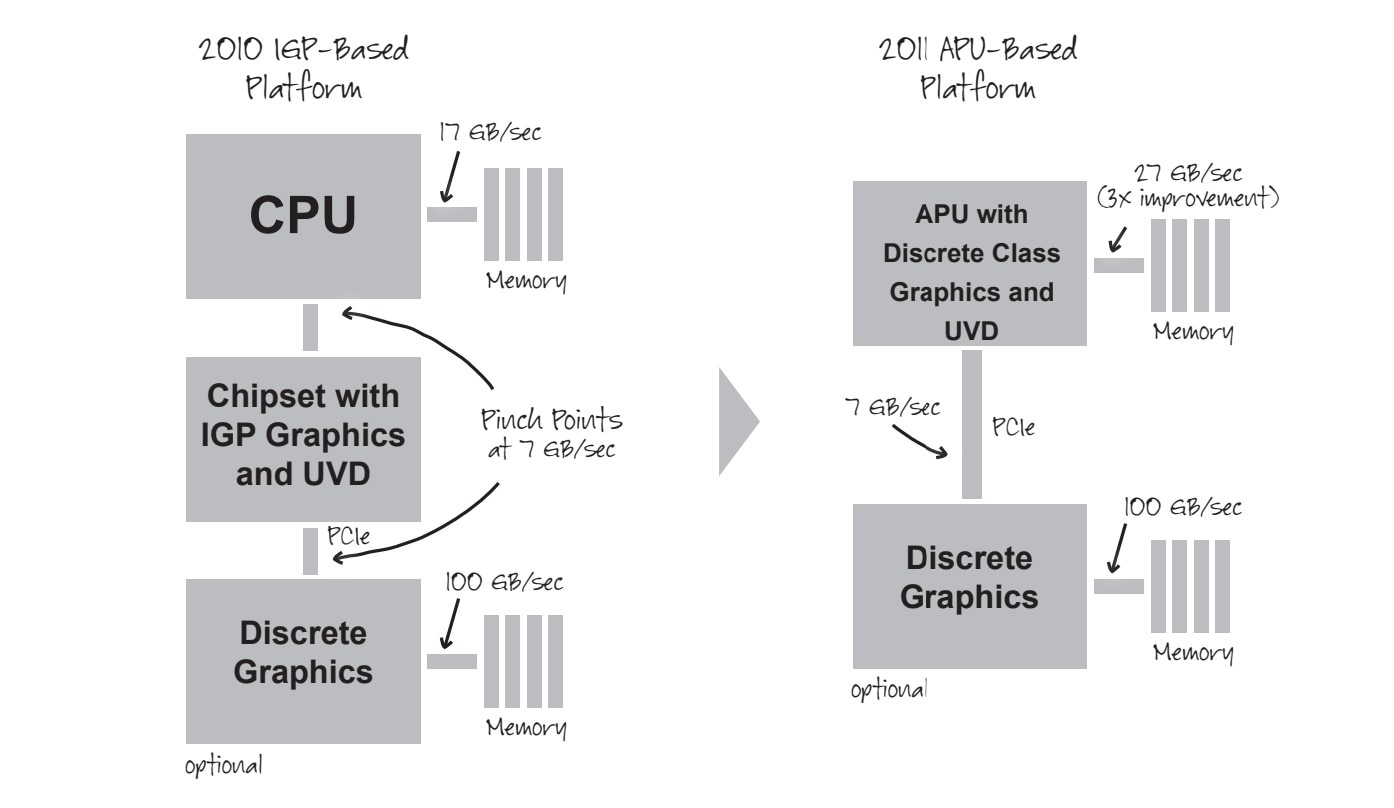
不过很显然,GPGPU这类思路是需要开发生态配合的:CPU不会平白无故地把任务分给GPU去做,远不是“上帝说要有光便有了光”这么简单的过程。
英伟达的CUDA生态也搞了很久。AMD自然需要配套打造各种工具,并维护标准和生态:一个可以跨不同处理器,做统一开发的生态;也需要更多合作伙伴的加入和开发者的响应。
AMD最初提过没有一家处理器厂商用真正可编程的GPU,来做CPU和GPU的融合,所以APU生态“用高层级行业标准工具如OpenCL、DirectCompute和DirectX 11让GPU可编程。”
AMD雄心壮志地说要让软件开发者能够将高性能矢量算法融入到自己的应用中,不再受制于标量处理器(CPU)的传统计算限制。
2012年,AMD牵头成立了HSA Foundation(Heterogeneous System Architecture,异构系统架构)。
这个组织当时还拉进了Arm、Imagination、联发科、高通、三星、德州仪器等。
AMD就是期望HSA架构能够真正推广开来,并推进APU这类形态处理器的软件生态建设。
另外,这一年AMD也把APU的“Fusion”平台改名为“HSA”。
不过虽然异构计算现在变得越来越流行,但在个人计算市场,HSA可没能如AMD预期般繁盛兴盛。AMD还是高估了自己在行业内的号召力。这是后话了。
APU 的完整形态:hUMA
从当年AMD的形容来看,APU这类芯片的终极理想,或许更靠近于此前索尼PS3游戏机的CELL处理器,或者富士通近年推的A64FX超算芯片——它们在硬件架构层面算是部分融合了CPU和GPU,而不只是把CPU、GPU做到一颗芯片上。
不过APU显然是无法这么激进的,毕竟它不像CELL、A64FX那样只面向某一个专门的市场。
Jim Keller还在AMD的时候也是HSA的重要倡导者。
Jim Keller多年前说过:“图形计算需要真正的高带宽内存系统。
以前图形单元有其专门的内存系统,而CPU和GPU对话,需借助于PCIe。
在HSA架构下,CPU与GPU共享内存,图形单元看得到内存,CPU也看得到内存,我们在两者间传递指针,两者有共同的地址空间。”
(貌似Lisa Su更是HSA的倡导者,CELL处理器时代,Lisa Su还在IBM)
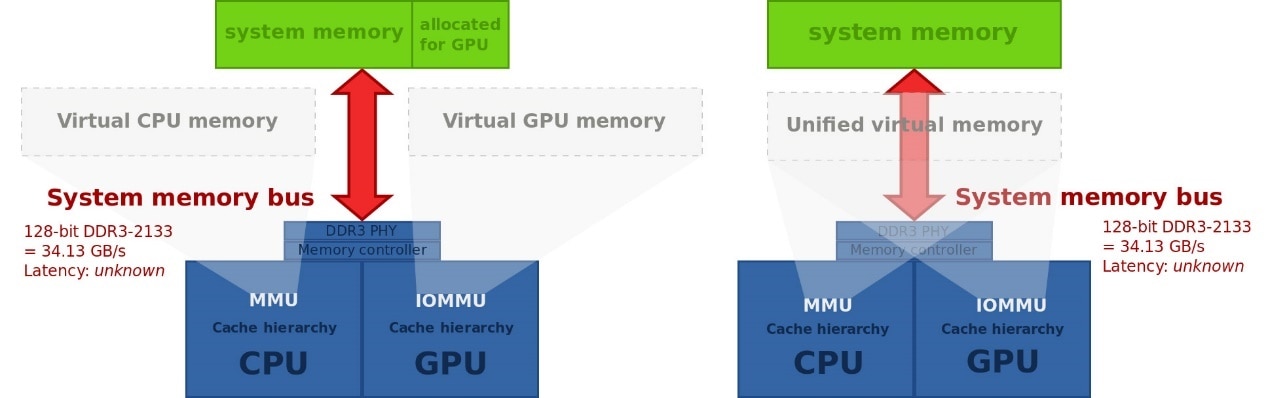
这听起来是不是和苹果M1的UMA已经十分类似了?
不过HSA的实现,在AMD的APU上也不是一蹴而就的。
至少我们在AMD 2010年发布的白皮书中还没有看到AMD大谈UMA。
从维基百科的资料来看,HSA特性包括很多分项,比如说共享电源管理、HSA-aware MMU(内存管理单元)、GPU Compute C++支持等。
Jim Keller口中提到的“共同地址空间”这一项,在实现上可能至晚是2014年PS4游戏机中的Kaveri APU——这项特性名为Heterogeneous Memory Management,CPU的MMU和GPU的IOMMU共享相同的地址空间。
不过2012年的Trinity APU上,也已经实现了HSA-aware MMU,即GPU可以通过HSA MMU的转译服务和页面错误管理,来访问整个系统内存…(在2013年以前,APU可能均未从硬件层面实现“共同地址空间”,但可能已经实现了对开发者而言CPU与GPU都看到“共同的数据”,并由中间层实现数据的同步)
2014年所推的APU另外也实现了CPU与GPU的所谓“完全一致存储”(fully coherent memory),以及GPU可以通过CPU pointer来使用可分页(pageable)的系统内存等等。
2015年的Carrizo APU又加入了GPU计算上下文切换、QoS等特性……

实际上,2013年AMD市场宣传中提出了一个名为hUMA(Heterogeneous Unified Memory Access)的概念,其本质应当也没有脱离广义上的UMA。
我们的理解,hUMA应该是AMD期望在APU上实现CPU、GPU(以及更多类型处理器)融合计算的完整特性的集合,包括“共享地址空间”“完全一致存储”这些特性。
从硬件层面实现存储一致性,相较于由程序标注数据修改,也更符合AMD构建HSA的初衷,对开发者也会更友好。
当年AMD还强调了hUMA的一项重要特性,即在内存资源仍然比较紧俏的时代,虚拟内存交换是很常见的——即将一部分内存数据放到硬盘上。
CPU如果要访问硬盘上的这些虚拟内存数据,则需要通过操作系统来获取数据。

前面提到一般CPU和GPU内存区域分开,两者间是要执行复制数据操作的,这个过程是由CPU独立进行的。
如此,CPU也就无法处理写入硬盘的虚拟内存部分,复制的数据只能放在RAM上,且要确保不会被写进硬盘的虚拟内存交换区。
hUMA当年也着力于解决这个问题,GPU不仅可以用CPU的地址,而且可以用按需分页的虚拟内存。
AMD说除了GPGPU编程以外,这对图形计算中,用到大型纹理的场景是很有价值的。
好了,花在HSA特性介绍上的笔墨有些过多了,这里就不再多做介绍了。其实谈这么多,都为了说明, APU 原本在设定上绝对不只是单纯地将CPU 和GPU 放到同一个die 上,硬件和生态层面其实还是作了比较大的努力,以期实现CPU 、GPU 协作的高效性的。
苹果几乎没有公开多少有关M 1 芯片 UMA 架构的信息,但AMD 对 类似思路的 践行 应该早了很多年 ,只是不知道苹果是否在实现上应用了什么独特技术 。
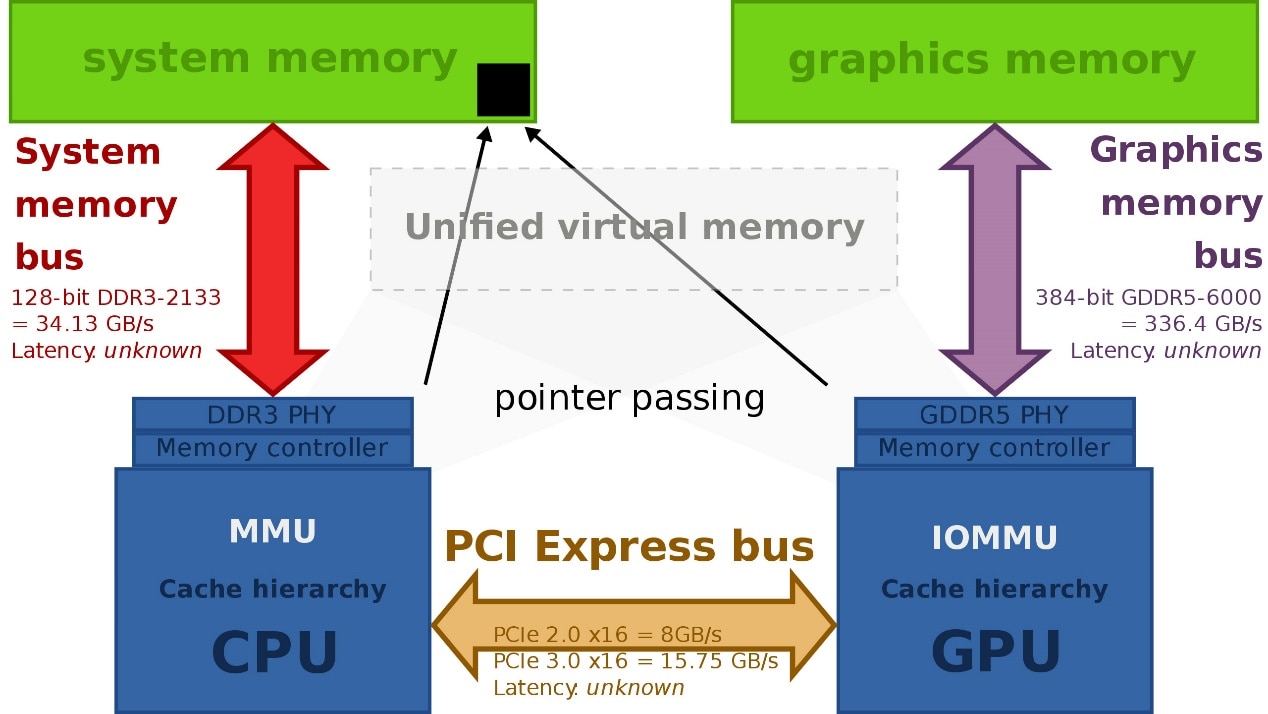
另外值得一提的是,AMD的APU、HSA、hUMA并不只是针对CPU和GPU,还包括其他处理器,AMD预想中的如加密加速器、FPGA等;
HSA在架构设计上也扩展到了(有VRAM的)独立显卡,其实现主要是通过PCIe传递指针(而不是完整复制数据)实现unified virtual memory(如上图)。
当代 APU 的名存实亡
完整践行了AMD APU这套思路的,应该就是游戏主机了,比如PS4开始对上述特性就有相对完整的实践。或许APU的完美适配领域,就在游戏机市场上——这也是AMD的主场。
不过在PC领域,像HSA这样的方案,说到底还是需要开发者响应的。
除了硬件支持之外,还需要在生态方面多做投入。为了实现互通性、简化开发,对于CPU和其他处理器而言,HSA实现是ISA无关的,同时要对高级语言实现支持。所以HSA生态上实际包含了什么HSAIL(中间层)、内存模型、dispatcher和运行时之类的组成部分。
HSA特性也需要受到操作系统内核、设备驱动的支持等等。
目前PC平台的HSA生态基本处在荒废状态,表明APU with HSA在PC平台是名存实亡的。
现在的APU,其本质大概也就是带GPU核显的AMD处理器产品。
其实即便只看今年AMD所推APU产品的GPU性能(Ryzen 7 5700G - RX Vega 8),也已经被隔壁Intel Xe核显超过,早就不复AMD开辟APU形态产品之初,要让高性能GPU与CPU协同工作的心思了。
APU现如今在PC市场上的角色,可能与带核显的面向笔记本一类低功耗移动市场的芯片产品并没有本质区别,这显然与AMD当初宣称APU/HSA是第三次性能革命的誓言背道而驰。
AMD对HSA生态的疏于维护,一方面是对这个方向的不再看好;以及鉴于AMD在PC市场上的号召力不足,开发者对AMD的这套方案始终也真的没有太大的兴趣。
而另一方面,AMD如今的Zen架构处理器,在性能和效率上早不再是当年推土机的模样,也对Intel酷睿处理器实现了超越,自然也不再需要藉由APU这样一个概念去为竞争找补。
不过说到生态,除了像游戏机这类AMD的固有主场,在PC市场上,苹果的号召力和AMD可不在一个次元。
苹果作为芯片设计商、操作系统开发商、PC设备OEM厂商多重角色,对生态的牢牢把控,以M1为硬件基础推行自己的异构计算和UMA架构,难度大概会小得多。苹果在此的主要成就,大概就是超强的生态掌控力了吧。
不过这则故事还没完,UMA在AMD/Intel的处理器上真的已经不复存在了吗?APU的传奇是否就此结束?是否只有苹果才能机会将UMA贯彻到底?这些将在本文的下篇中做解读。或许UMA只是以另一种方式存
在于x86和Arm世界,只是它不叫HSA而已。
本文的上篇大致解释了苹果M1实现的“统一内存架构(Unified Memory Architecture,UMA)”实际上并没有什么稀奇,AMD在十多年前就在APU产品上做这一理念更全面的实践了。
只不过AMD未能将APU with HSA的生态做起来,因为APU的理念是让GPU和CPU集成到一起,并同时处理日常工作,尤其是在CPU的矢量及其他大规模并行计算算力不足时,集成在同一片SoC上的GPU能立马顶上——这个思路固然是好,但也要求开发生态的配合,CPU不会无缘无故就将工作分给GPU去完成。
如上篇所述,AMD高估了自己的生态话语权,除了游戏主机这个主场,PC领域APU完全体的HSA联盟和生态未能如预期般强盛起来。
如今应用于PC的APU更像是单纯将CPU、GPU放在同一颗die上的普通处理器,HSA开发生态已经处在了荒废状态;
而且AMD的APU产品如今集成的GPU核显,在性能上也未能如十多年前APU刚诞生之时预期的那样,显著优于竞争对手;AMD处理器的UMA也就随之成为历史了…吗?

苹果虽然晚于其他市场竞争者很久才入世,在发布M1之时才提出了UMA统一内存架构,但凭借其在生态构建方面的独特话语权,却在CPU+GPU+其他加速器的异构计算方面,有着无与伦比的优势。
不过有关桌面处理器异构集成、UMA的故事并未就此结束。
本文的下篇,我们来补充谈谈各路竞争对手在UMA实现上的努力。
建议在阅读下篇之前,首先看一看本文的上篇——以便理清异构集成、HSA、hUMA、UMA等词汇表达的涵义差别。
Intel家 上古时期的 UMA
以“统一内存”这个说辞来做市场宣传的,其实远不只是AMD、苹果——毕竟异构集成是市场发展的总体趋势,市场的主要参与者普遍都能看到UMA这样的技术红利。
比如英伟达也在大约6、7年前就提到了Unified Memory,虽然在实现方法和阶段上,大家都是有差别的(比如是否真正实现了共同内存地址,还是部分实现,抑或对上层隐藏了更多复杂的实现细节)。
在下文谈UMA之前,我们首先来回顾一下苹果的UMA究竟是怎么回事。
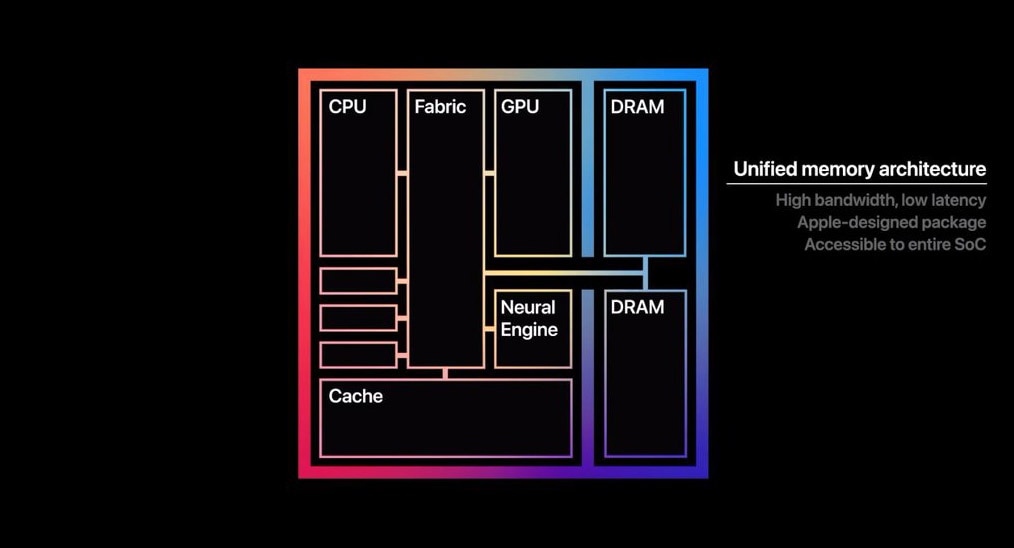
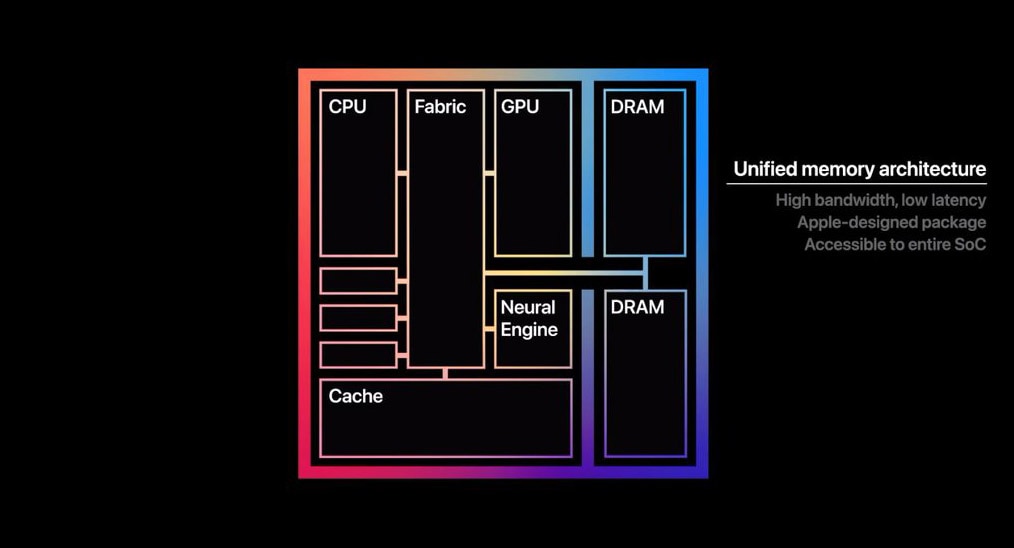
为普罗大众所知的是,苹果M1实现的UMA,主要是让RAM内存面向CPU、GPU时,采用统一可访问的内存池。
因为传统方案的CPU和GPU即便放在同一颗SoC上,且访问相同的物理内存,但由于它们对内存的不同访问习惯及数据结构,所以CPU和GPU针对内存的存取空间是分开的,需要在内存的不同空间之间来回复制数据。M1则不需要执行这种数据复制操作。
但苹果在其M1芯片的UMA实现上语焉不详,其新闻稿中只提到了两句:“M1采用统一内存架构(UMA)…”“这让SoC上所有的技术组成部分,不需要在多个内存池之间进行复制操作,就能访问相同的数据,进一步提升了性能和效率。”
其实“访问相同的数据”这一点,在硬件层面以及中间层实现方式上是多种多样的,且历史悠久。
这句话约等于什么也没说。至于“不需要”“进行复制操作”,这一点也不稀罕,后文会提到。
在此,苹果也并没有说清楚他们定义中的UMA究竟是什么概念,尤其硬件层面究竟要走到哪一步。
从苹果公布的这张图来观察,其实也看不出什么花样来。CPU、GPU、Cache(应该是SLC)、NPU都连接到Fabric上,两片DRAM亦如是。这种方案算不算得上高端呢?我们来看看别家是怎么做的。
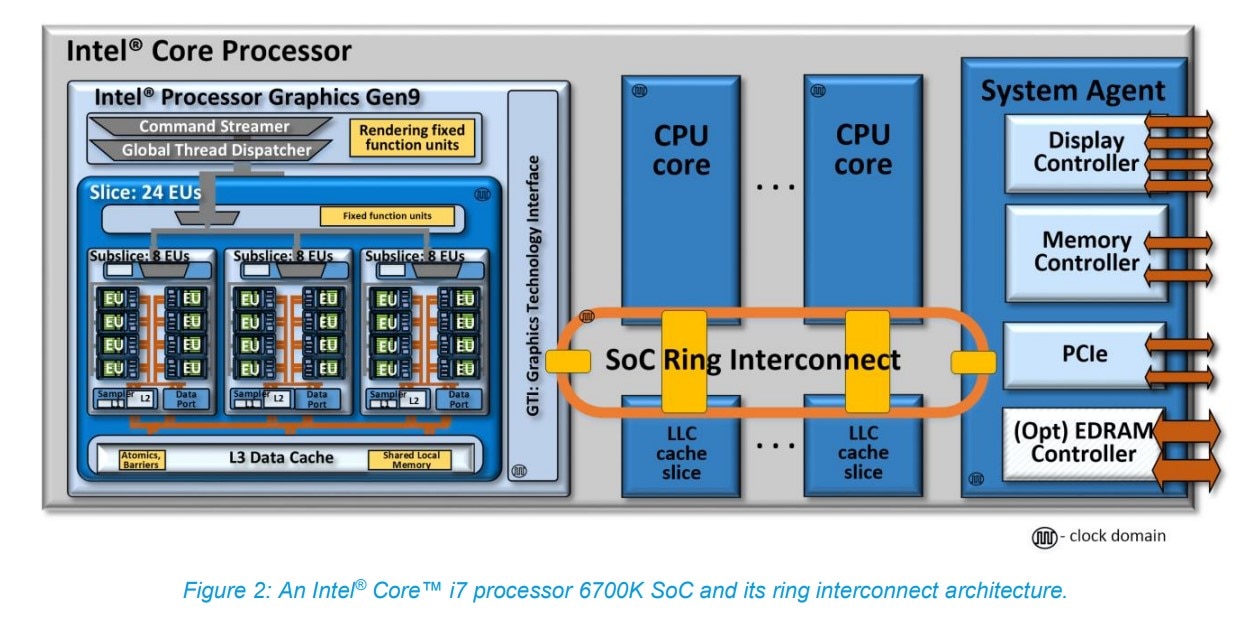
上面这张图是Intel第六代酷睿处理器(Skylake,2015年)i7-6700K的ring互联架构。
这一代的酷睿处理器集成了Intel Gen9核显(上图中的左边部分)。
从这张图就能看出来,CPU核心、LLC(last level cache)、GPU,还有System Agent之间有个片上总线,叫SoC Ring Interconnect,而且每个连接对象都有这个专门的本地接口。
这里的SoC Ring Interconnect是个双向ring环——对Intel处理器熟悉的同学对此应该也不会陌生。GPU在这个层面,就像是CPU的某个核心一样,也处在互联ring的一个agent环节上。
右边这一侧的System Agent包含了DRAM内存管理单元、显示控制器、其他芯片外的I/O控制器等。
内存控制器自然就要通往内存了。Intel在Gen9的计算架构介绍中特别提到了。
“所有来自或者去往CPU核心,以及来自或者去往Intel GPU的(片外)系统内存数据交换事务,都经由这条互联ring实施,通过System Agent以及统一DRAM内存控制器。”
仔细想一想这种结构,再回看苹果M1的那张图,是否感觉双方的差别并不大(只不过那会儿还没有NPU这种东西)?另外尤为值得一提的是,Gen9这张互联架构图中可见,LLC cache也作为单独的agent节点连在ring上。
Intel在文档中提到:“该LLC也与GPU共享。对于CPU核心与GPU而言,LLC着力于降低访问系统DRAM的延迟,提供更高的有效带宽。”
也就是说,从很多年前开始,Intel处理器内部的核显其实是连片内的LLC cache都是可以访问的,和CPU核心算是平起平坐。
这里面当然有更复杂的一些访问机制,包括存储一致性、分层级的存储访问问题,以及到系统内存如何实现CPU与GPU的“统一访问”等。
这其中似乎关系到很多奇技淫巧,对于“统一存储访问”的定义可能不是本文上篇提到的“共同地址空间”这么简单。
事实上我们也并不清楚苹果在M1芯片上究竟是怎么来定义和实施“统一内存架构UMA”的。
但我们起码也知道了,UMA这个东西是大家都在做的。
不光是AMD、Intel,其实还有Arm(所以苹果以前的芯片有没有在做呢?)。
虽然可能大家对于UMA的实现方法和效率都存在差异。
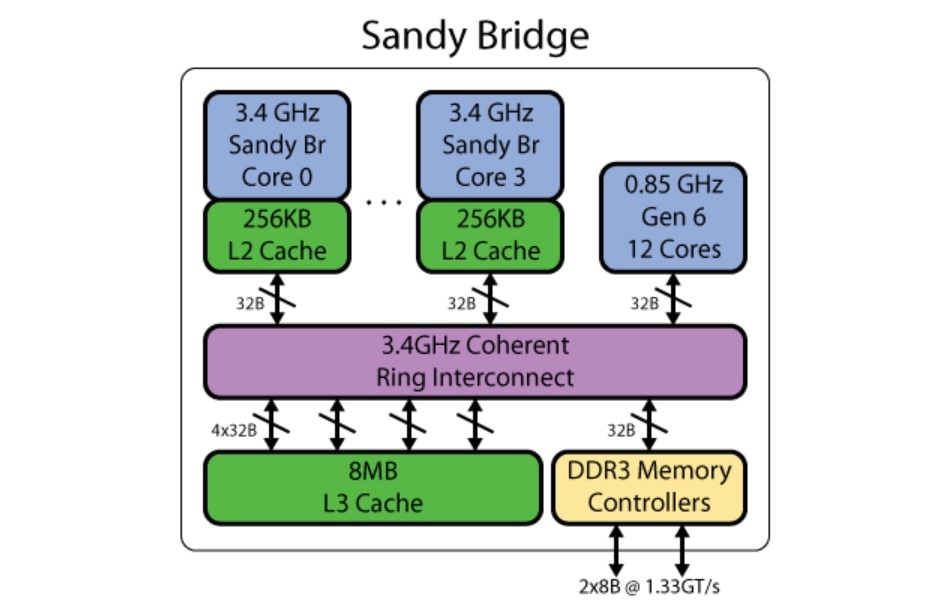
可能有同学会好奇,Intel最早是从什么时候开始搞类似的方案的?
我们简单查了一下:从维基百科的记录来看,Intel是从Gen5开始将主板上的“集显”,移往处理器SoC内部成为“核显”的(Arrandale/Clarkdale,2010年)。
不过Gen5时代的内部互联架构已经不大可考,但我们找到了前人总结的Gen6核显(Sandy Bridge,2011年)互联架构,如上图所示。
大体上看起来是不是还是那个味儿?或许Intel和AMD对于广义上UMA的实现差不多是同期。
这一刻是否感觉苹果M1的UMA也没什么大不了?
虽然还是那句话,我们不清楚苹果究竟是怎么去实施UMA的,或者从过去的A系列芯片到如今的M1,期间是否经历了什么。
以另一种方式延续的 HSA
回到AMD本身,上篇我们提到了AMD的HSA生态实现是分阶段、分步骤的——虽然现在PC领域的HAS生态和工具似乎已经“停更”了,不过在这其中我们关注的UMA统一内存架构/访问的问题,AMD从2012年以来的更新节奏还是比较清晰的。
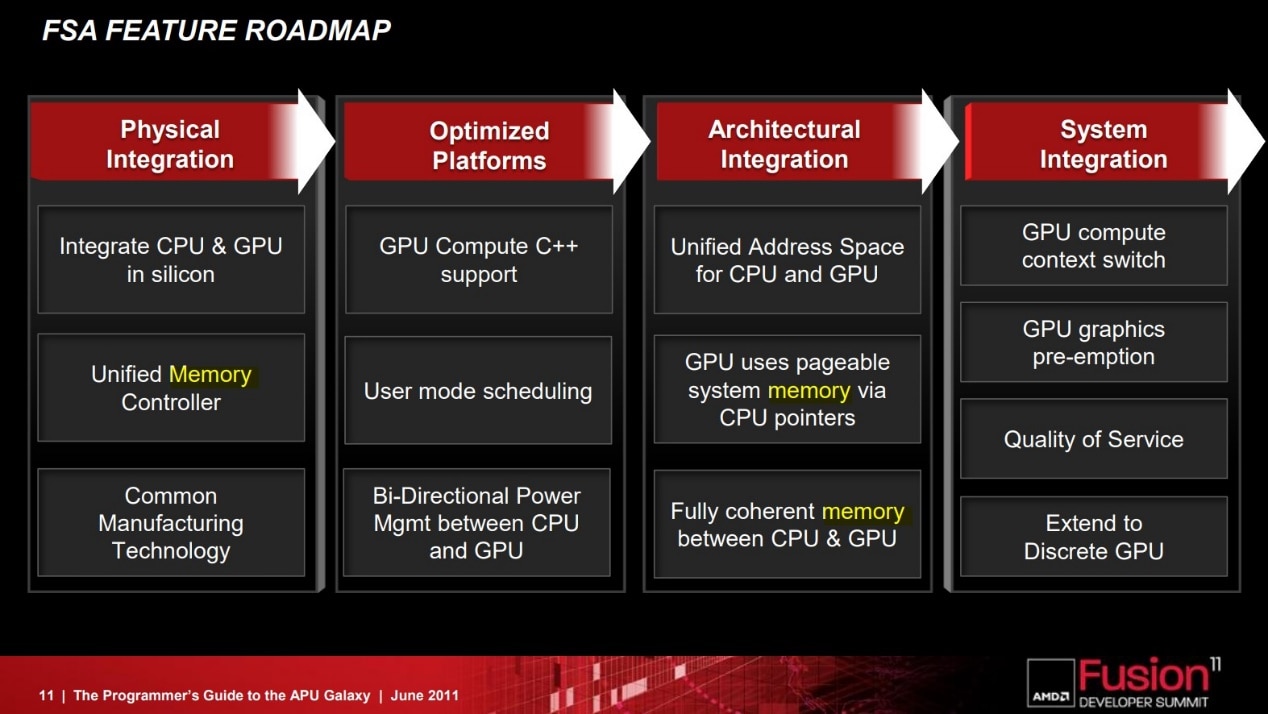
这是AMD当年给出的APU HSA特性更新,在上篇中我们也已经谈到了其中相关UMA的一些实现。
从2012年GPU能够通过HSA MMU访问整个系统内存,到后来CPU的MMU和GPU的IOMMU共享相同地址空间,指针能够在CPU和GPU之间传递,实现所谓的“zero-copy”零拷贝,这跟苹果所说不就是同一回事吗?
与此同时,2014年的APU也有了CPU和GPU之间的完全一致存储——这和前文提到Intel片内共享LLC的方案异曲同工,虽然实现上差别似乎不小;还有GPU能够使用页交换的虚拟内存——上篇中已经提到了这一点。
不过AMD在2011年就发布文章提过APU对开发者而言的zero-copy。
AMD APP SDK 2.5引入zero copy传输路径,在实现上似乎是在可访问的GPU内存区创建一个内存buffer,将其映射到CPU,CPU和GPU从逻辑上实现对这部分buffer的传输控制。
其更底层的实现不得而知。
不过极有可能,AMD对于“zero-copy”的实现在2011年之后,芯片设计或者说硬件层面又有新的变化——毕竟UMA的实现这么多年都有各层面的进步。
而2013年OpenCL 2.0带来了shared virtual memory特性,其中第一项就是共享虚拟地址空间。
Intel当时还特别在宣传中提到这项特性需要专门的硬件一致性支持,例如其当时的Gen8 GPU。
多提一嘴,从当年Llano系统架构分析来看,它在CPU与GPU的一致性存储实现上可能比Intel还稍稍晚了一点。
不过这种差距最晚于2014年补上,实现方式和Intel差别较大——此处或许还有许多问题值得商榷,因为时间有限,我们也没有再深入研究。
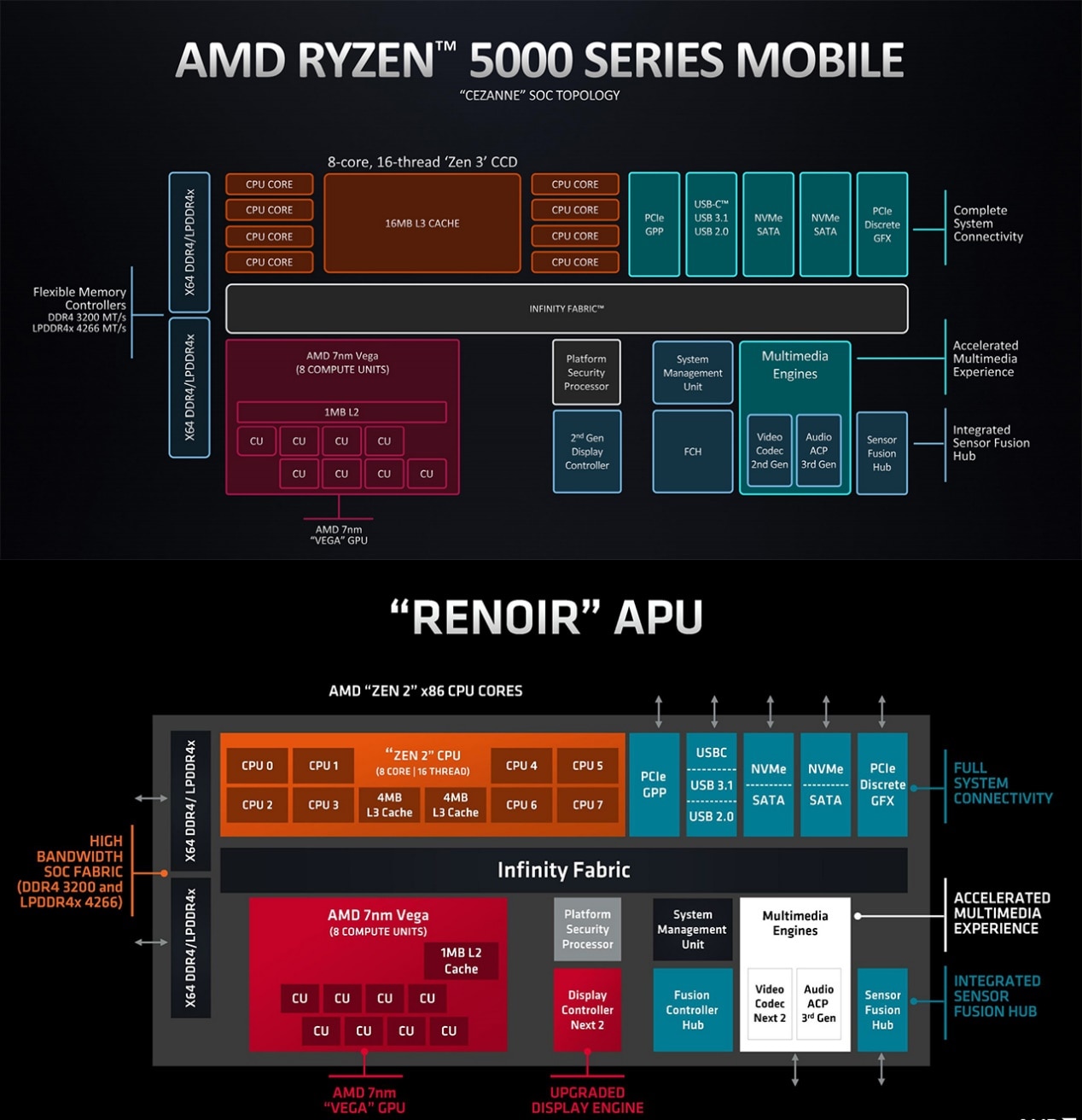
从时代的发展,以及当代AMD处理器架构图来看,大概能发现两件事。
其一是,桌面端APU核显,和笔记本移动端的核显,从构成和互联方式上也都没什么太大分别——这或许能够一定程度表明,“APU”如今也就剩个名字了,或者也可以说现在的移动处理器普遍也都发展成了APU那样。
另一点是UMA就处理器层面的实现,是个极其稀松平常的事情——看上图中的Infinity Fabric,再回顾下苹果M1的那张架构图,都是这么串联的。
UMA不是苹果一家在做,而是大家都在搞;只是或许每家每户的实现方式是不大一样的,在程度和效率上我们也无从得知谁高谁低。
如AMD如今的处理器这样,也是一堆东西都挂在Infinity Fabric互联上,包括CPU、GPU、内存控制器等。
与Intel和苹果的区别,大概就是LLC(或system level cache)并不共享;当然更多实现细节,我们是无从得知的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0TZr8k6c-1690976490149)(苹果M1统一内存架构真的很厉害吗?.assets/1831f3413050c3b138e495c0f385d12f.jpg)]
如上篇所说,从HSA最初的设定来看,AMD的APU with HSA理想和生态终未能实现。
这个时代若说算力,即便只是图形计算,也得依靠独立显卡和大容量的显存,APU with HSA又怎么谈得上第三阶段的性能飞跃(上篇提到的前两个阶段分别是单核时代、多核时代)?
不过UMA的实施和现状,其实都表明HSA的故事还在延续,即便UMA也只是HSA生态中的一环;即便这可能不单是AMD的HSA生态促成的。
只不过时代发展至今,即便UMA的硬件实现如此稀松平常,x86开发生态对于UMA的接受度仍然并不算高(此处仍能体现出苹果的生态优势)。
但AMD有一点没有料错,就是异构计算时代的到来,是算力的又一次飞跃。即便这个时代不叫HSA,或者与AMD牵头建立的HSA Foundation联盟关系不大,异构计算的发展却也从不曾停歇。
比如Intel的XPU和oneAPI ,比如Arm的Total Solution,比如 安谋科技的超域架构,还有英伟达的CUDA;
只不过不是以AMD期望的方式那样发展罢了——AMD自己现在不也有其他的异构计算发展方向吗?HSA正以各种方式延续着。
责编:Luffy Liu
2023-08-02(三)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









