








本学习笔记来自于阅读 Brendan Gregg的《BPF Performance Tools》
BPF编译器集合(BCC)是一个开放源代码项目,其中包含用于构建BPF软件的编译器框架和库。 它是BPF的主要前端项目,受到BPF开发人员的支持. BCC还包含70多个现成的BPF性能分析和故障排除工具
BCC 组件: BCC包含有关工具,手册页和示例文件的文档,以及有关使用BCC工具的指南,以及有关BCC工具开发的指南和参考指南。 它提供了用于在Python,C ++中开发BCC工具的接口; 将来可能会添加更多接口
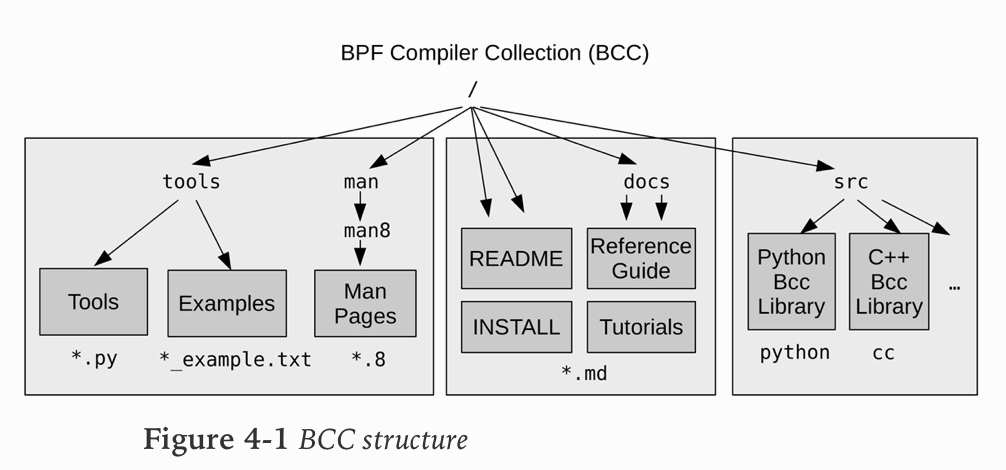
BCC工具使用的主要语言是Python(用于用户级组件)和C(用于内核级BPF)。指南中的建议之一是 “编写工具即可解决问题,而无需更多”. 这鼓励在可能的情况下开发单一用途的工具,而不是多功能的工具
一、 单一目的工具
Unix的哲学是做一件事并做好, 其中一种方式是创建较小的高质量工具,可以使用管道将它们连接在一起以完成更复杂的任务,例如grep, cut等
考虑一下如何为跟踪open系列syscall的一项任务自定义选项和输出:
$ opensnoop -h
usage: opensnoop [-h] [-T] [-U] [-x] [-p PID] [-t TID] [-u UID]
[-d DURATION] [-n NAME] [-e] [-f FLAG_FILTER]
Trace open() syscalls
optional arguments:
-h, --help show this help message and exit
-T, --timestamp include timestamp on output
-U, --print-uid print UID column
-x, --failed only show failed opens
-p PID, --pid PID trace this PID only
[...]
- 便于初学者学习:默认输出通常就足够了。这意味着初学者可以立即使用这些工具,而无需对命令行使用做出任何决定或知道要检测哪些事件
- 易于维护:对于工具开发人员来说,要维护的代码量应该更少,并且需要更少的测试
- 代码示例:每个小型工具都提供了一个简洁实用的代码示例
- 自定义参数和输出:工具参数,位置参数和输出不需要容纳其他任务,可以针对一个目的进行自定义。 这样可以提高可用性和可读性
二、多功能工具
BCC包含可以执行各种不同任务的多功能工具。 这些很难学习,但是一旦学习就会更强大。 如果您仅偶尔使用这些内容,则可能无需深入学习它们。 您可以收集一些单行代码以在需要时执行
- 更高的可见性:您无需一次分析单个任务或目标,而是可以一次查看各种组件
- 减少代码重复:不用多个具有相似代码的工具
1. FUNCCOUNT
对事件(尤其是函数调用)进行计数,并且可以回答以下问题:
- 是否调用了此内核级或用户级函数?
- 每秒此函数调用的速率是多少?
为了提高效率, funccount使用BPF map 在内核上下文中维护事件计数,并且仅将总数发送给用户空间。 尽管与转储和后处理工具相比,这大大减少了funccount的开销,但如果事件的发生频率很高,则事件的选择仍会导致相当大的开销。 例如,内存分配(malloc(),free())每秒可能发生数百万次,使用 funccount 进行跟踪可能会花费超过30%的CPU开销
语法
funccount [options] eventname
参数解释: eventname
name or p:name: kprobe, 称为name()的内核函数lib:name or p:lib:name:: uprobe, 在库lib中称为name()的用户级函数path:name: uprobe, 在路径中的文件中称为name()的用户级函数t:system:name: instrument the tracepoint 称为system:nameu:lib:name: instrument the USDT probe, 在库lid中称为name*: a: 通配符可匹配任何字符串, -r 选项允许使用正则表达式代替
单行用法
# 计算VFS内核调用次数
funccount 'vfs_*'
# 计算TCP内核调用次数
funccount 'tcp_*'
# 计算每秒TCP发送调用次数
funccount -i 1 'tcp_send*'
# 显示每秒的块I/O事件的速率
funccount -i 1 't:block:*'
# 显示每秒新进程的速率
funccount -i 1 t:sched:sched_process_fork
# 显示每秒libc getaddrinfo() (名称解析)的速率
funccount -i 1 c:getaddrinfo
# 计算所有 os.* 在libgo中的调用次数”
funccount 'go:os.*'
# 系统范围内从libc调用频率最高的字符串函数
funccount 'c:str*'
# 最频繁的系统调用是
funccount 't:syscalls:sys_enter_*'
[...]
示例: 曾经调用过tcp_drop()内核函数吗?是的, 此调用仅跟踪tcp_drop()内核函数,在追踪时,它被调用了三遍
$ funccount tcp_drop
Tracing 1 functions for "tcp_drop"... Hit Ctrl-C to end.
^C
FUNC COUNT
tcp_drop 3
2. STACKCOUNT
事件的堆栈跟踪。 与funccount一样,事件可以是内核或用户级函数,跟踪点或USDT探测器
- 为什么调用这个事件?代码路径是什么?
- 调用此事件的所有不同代码路径及其频率是什么?
为了提高效率,stackcount完全在内核上下文中使用堆栈跟踪的特殊BPF map 执行此摘要。 用户空间读取堆栈ID和计数,然后获取堆栈跟踪以进行符号转换和打印。 与funccount一样,开销取决于所检测事件的发生率,并且随着stackcount对每个事件进行更多工作:遍历和记录堆栈跟踪,开销会明显更高
语法
同FUNCCOUNT一样
单行用法
# 计算创建块I/O的堆栈跟踪
stackcount t:block:block_rq_insert
# 计算导致发送IP数据包的堆栈跟踪
stackcount ip_output
# 使用相应的PID对导致发送IP数据包的堆栈跟踪进行计数
stackcount -P ip_output
# 计算导致线程阻塞和移出CPU的堆栈跟踪
stackcount t:sched:sched_switch
# 计算导致read()系统调用的堆栈跟踪
stackcount t:syscalls:sys_enter_read
示例
我注意到使用funccount在一个空闲系统上,我似乎有很高的ktime_get()内核函数调用率,每秒超过八千次。 这些获取时间,但是为什么我的空闲系统需要如此频繁地获取时间?使用stackcount识别导致ktime_get()的代码路径.
如下所示: 输出长达数百页,包含一千多个堆栈跟踪。 每个堆栈轨迹在每个功能上打印一行,然后出现次数.
最频繁调用ktime_get()的堆栈来自CPU空闲路径
$ stackcount ktime_get
Tracing 1 functions for "ktime_get"... Hit Ctrl-C to end.
^C
[...]
ktime_get
tick_nohz_idle_enter
do_idle
cpu_startup_entry
start_secondary
secondary_startup_64
1077
[...]
stackcount火焰图
有时,您会发现只为一个事件打印了一个或几个堆栈跟踪,可以在stackcount输出中轻松浏览。 对于ktime_get()这样的情况,其中输出长达数百页,可以使用火焰图来可视化输出. stackcount可以使用 -f 生成此格式。
$ stackcount -f -P -D 10 ktime_get > out.stackcount01.txt
# 使用火焰图软件,生成svg
$ git clone http://github.com/brendangregg/FlameGraph
$ cd FlameGraph
$ ./flamegraph.pl --hash --bgcolors=grey < ../out.stackcount01.txt > out.stackcount01.svg
3. TRACE
可从许多不同的来源进行事件跟踪
- 调用内核级或用户级函数时,参数是什么?
- 该函数的返回值是多少? 失败了吗?
- 这个函数怎么调用? 用户或内核级堆栈跟踪是什么?
由于它为每个事件打印一行输出,因此它适合于很少调用的事件。 诸如网络数据包,上下文切换和内存分配之类的非常频繁的事件每秒可能发生数百万次,而trace会产生如此多的输出,以至于将花费大量的开销。 使用trace的解决方案是使用过滤器表达式仅打印感兴趣的事件。 频繁发生的事件通常更适合于使用其他进行内核汇总的工具进行分析,例如funccount,stackcount和argdist
4. 其他
其他工具可自行查看, 工具文档
如果您的工具是通过软件包安装的,则可能会发现man opensnoop命令有效, 可以使用nroff来格式化手册页
$ nroff -man man/man8/opensnoop.8















 1683
1683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









