







集群模式
一台RabbitMQ的处理能力终究是有限的,同时容灾性很差。那么我们RabbitMQ的集群的出发点就在与扩大程序的规模以提高程序的负载能力,同时提高集群的容灾性,当一台宕机后,仍有其他服务器进行处理业务请求。
集群架构
我们了解了RabbitMQ的交换器exchange以及队列queue和路由键Routing key以及如何将他们绑定到一起,那么在RabbitMQ中是如何记录我们使用的各个基础的组件,以及把他们配置成为服务器呢。
RabbitMQ会始终记录一下四中元数据类型
- 队列元数据—–队列的名称和他们的属性(是否可持久化、是否自动删除)
- 交换器元数据—–交换器的名称、类型和属性(是否可持久化)
- 绑定元数据—–一张简单的表格展示如何将消息路由到队列
- vhost元数据—–为vhost内的队列、交换器和绑定提供命名空间和安全属性
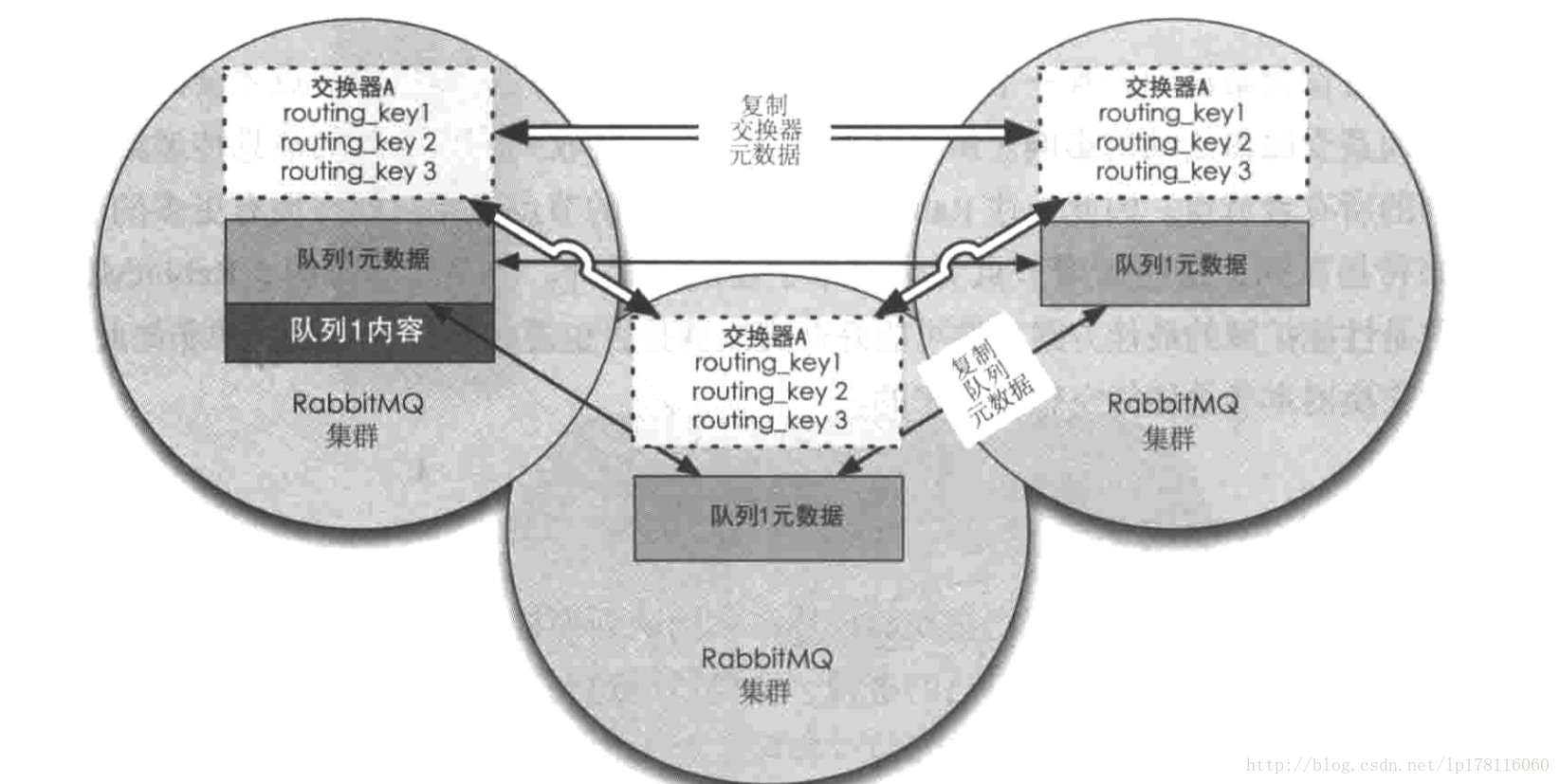
在单一节点中, RabbitMQ会将这些信息存储在内存中,同时将标记为可持久化的交换器以及队列(以及他们的绑定)持久化到硬盘上,持久化可以确保RabbitMQ在重启之后自动创建交换器以及队列,当我们引入节点时,那么就需要增加新的元数据类型:集群节点的位置,以及节点与已记录的其他元数据之间的关系。
集群中的队列
在两个节点创建集群的那一刻,并不是每个节点都有所有队列的信息,而是每个节点知道自己拥有队列的信息,而非本节点只知道队列的元数据以及指向该队列存在的节点的指针。因此当集群中的某个节点崩溃之后,附加在该队列的消费者丢失订阅信息,并且节点的消息也丢失。
我们可以让消费者重新链接集群,然后让消费者重新创建队列,但是这种方式仅在队列在初始创建时为非可持久化的才生效,否则报404-not-found错误。这样确保了可持久化节点在恢复时数据不会丢失。
为什么不是节点将所有数据复制到自己的节点上面:
- 存储空间,如果每个节点都有所有队列的完整拷贝,那么新添加的节点不会带来更多的存储空间,会带来更多的消息冗余。
- 性能,消息的发布需要将消息复制到每个一个集群的节点上面,对于持久化的消息来说会触发更多的磁盘IO
内存节点或者是磁盘节点
在RabbitMQ中每个节点不是磁盘节点就是内存节点,在单节点中必须为磁盘节点,在RabbitMQ集群中则必须至少有一个节点为磁盘节点。
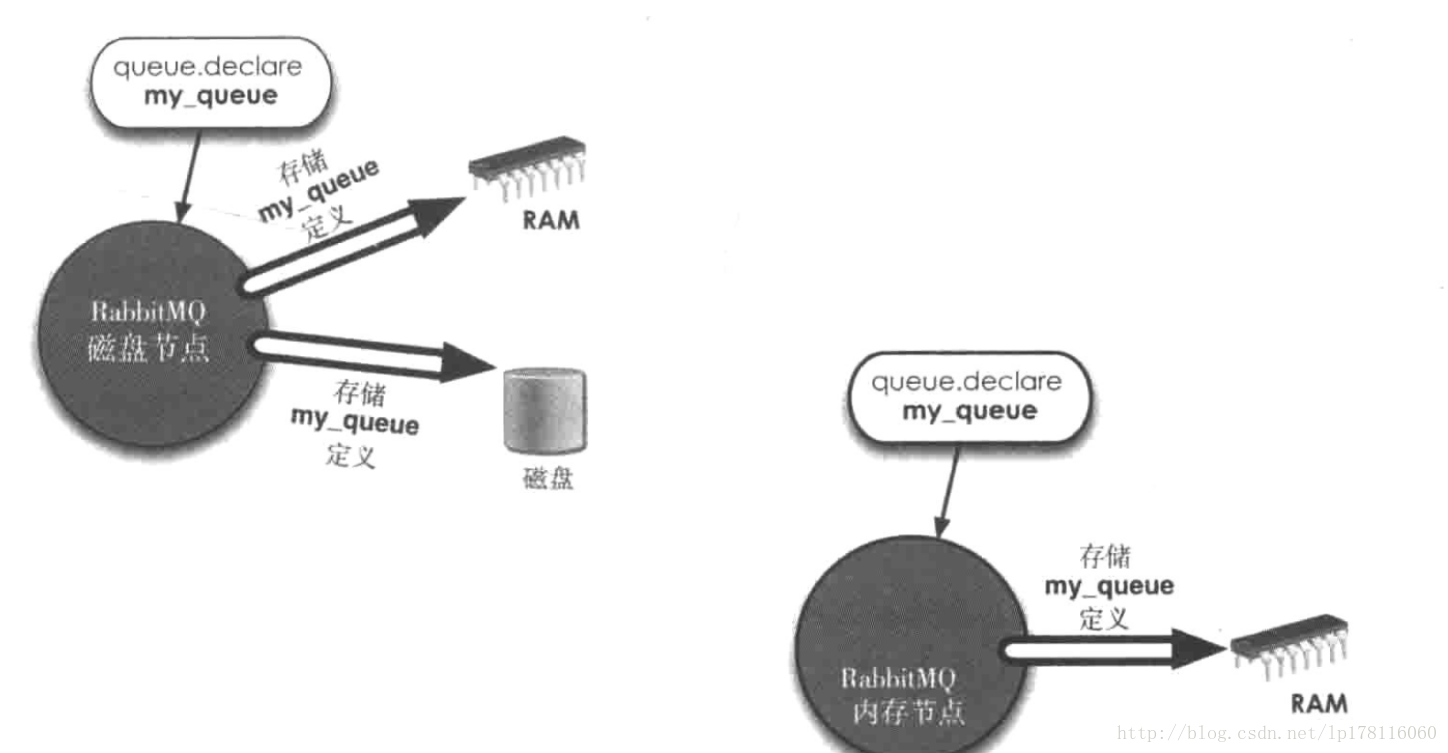
因此在繁重的RPC任务中,需要大量的创建删除节点,如果使用磁盘节点,将大量增加非常耗时的磁盘IO,导致性能下降,但是磁盘节点可以保障集群的稳定性,宕机恢复时可以保证完整性。
当我们的RabbitMQ集群只有一个磁盘节点,但是磁盘节点刚刚好发生宕机,那么会导致:
- 无法创建队列
- 无法创建交换器
- 无法进行绑定
- 无法添加用户
- 无法更改权限
- 无法添加删除节点
因此当集群中的唯一磁盘节点宕机,那么我们的系统仍然可以进行消息的路由,但是我们无法更改任何东西,解决办法是适当增加集群磁盘节点的个数,当内存节点连入集群会与磁盘节点进行通信,copy集群的信息,因此我们要确保磁盘节点知道内存节点的信息,当内存节点重启后,可以找到磁盘节点复制元数据,从而添加到集群中。
创建集群
查询系统中运行的RabbitMQ:
ps -ef|grep rabbitmq首先我们关闭系统内的单节点:
rabbitmqctl stop采用模拟集群的方式,在一台虚拟机上面开启3个RabbitMQ的进程,因此我们需要对端口以及节点名称进行设置。
在启用集群的时候我们确保RabbitMQ的插件进行禁用,否则插件监听的端口将会发生冲突。














 8489
8489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









