










1、问题提出
基于RNN(LSTM、GRU)的Seq2Seq模型在自然语言处理领域取得了巨大成功,特别是对机器翻译领域,神经机器翻译(NMT)已经完全替代了以前的统计(SMT)。但基于RNN的Seq2Seq有2个致命缺点:1、基于sequence中t-i的context计算t时刻估计,不适合并行计算,因此计算效率低;2、基于attention来计算source language与target language之间的对齐关系(alignment relation),但对中文省略部分词语,特别是口语中,attention计算并不准确,attention会把target中的词对应到省略词的上一个词或下一个词上,此时,会出现漏译情况。比如:
今天(我们)一起去逛街吧 -> Today go shopping together
正确的翻译应该是:Today, We go shopping together。我们被省略掉了,attention把对齐关系把主语对齐到今天上面了。
FaceBook提出了完全基于Convolution的Seq2Seq模型,采用非局部的层叠卷积方式来建模输入sequence中词与词的dependency关系。但基于传统卷积的seq2seq模型也有两个明显缺点:1、参数多,计算复杂度高,Batchsize、隐层神经元数目都不能设大,特别在decoder端非常明显;2、模型不容易训练:encoder或decoder层叠卷积层数目超过10层,模型很容易训飞,收敛时间长。
为了处理这个问题,基于Xception结构和mobileNets的Depthwise separable convolution结构,处理这个问题。
获取最新消息链接:获取最新消息快速通道 - lqfarmer的博客 - 博客频道 - CSDN.NET
2、本文的主要贡献
(1)、在本文中,采用一种深度可分离卷积的网络结构,搭建Seq2Seq模型,用于神经机器翻译(NMT)。深度可分离卷积(Depthwise Separable Convolution)减少了卷积操作中所需参数数目,降低模型的计算量(computation),同时提升了模型的表述能力(representational efficiency)。最近,Convolutional Seq2Seq在机器翻译领域取得不错的结果。
(2)、提出了一种新的网络结构SliceNet,其设计原理受到Xception 和ByteNet启发。优点:尽可能减少模型的参数,降低计算量。当与ByteNet对比,同样参数量情况下,SliceNet取得更好的结果。
(3)、将Depthwise Separable Convolution结构用于机器翻译,发现:深度分离特性(Depthwise separability)可以增大卷积窗口的大小,去除掉filter dilation的需求。
(4)、引入新的卷积操作:super-separable(超分离),进一步减少参数和计算量成本(computation cast)。
获取最新消息链接:获取最新消息快速通道 - lqfarmer的博客 - 博客频道 - CSDN.NET
3、分离卷积和组卷积(Separable convolution and grouped convolution)
深度可分离卷积与组卷积(grouped convolution)和Inception卷积网络中的inception module相关。Separable convolution由Depthwise convolution和Pointwise convolution两部分组成,Pointwise convolution接在Depthwise convolution之后。Depthwise convolution指,从多维空间角度上来看,input的不同channel之间,相互独立进行卷积。Pointwise convolution采用Inception Net中的1X1的卷积窗口进行卷积,把Depthwise convolution的输出映射到一个新的channel space中。
注意:Depthwise separable convolution与图像处理中的spatialy separable convolution处理不一样。
传统的convolution、Depthwise convolution、Pointwise convolution和Depthwise separable convolution(separable convolution)数学表达式下所示:
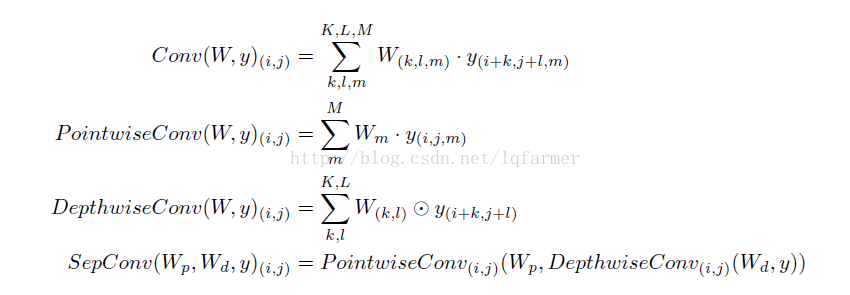
深度神经网络通过逐层的特征抽取,从复杂的输入X中抽取出抽象的、易于理解的特征。特定的i层中,隐含层神经元之间相互独立,各自抽取特定的特征(particular feature);i层神经元的输出,通过特定的方式(全连接、卷积、池化等方式)连接到i+1层神经元输入端,特定的连接方式起到组合(融合)这个特征(particular feature)的作用。
常规的卷积层中(regular convolution),需要同时进行特征抽取和特征融合的工作,从参数(Parameters)的使用角度来讲,效率低且效果不理想。相反,Depthwise separable convolution把两步分离开来,从深度方向,把不同的channels之间相互独立开,先进行特征抽取,在进行特征融合,这样做可以充分利用模型参数进行表示学习(representation learning),使用更少的参数,取得更好的效果。
Grouped convolution(sub-separable convolution)是一种介于regular convolution和Depthwise separable convolution之间的一种卷积方式。Grouped convolution把输入的channel分解成多个互补重叠的groups,每个组分别进行常规的convolution操作,然后把每个channel中的feature maps拼接起来做为最后的输出。这几种卷积方式的参数数目和每个位置的近似浮点数运算对比如table1所示:

其中,c是channel或filter的数目(一般c=1000),k是卷积核大小(一般k=3),g是groups的数目。可见,Depthwise separable convolution的数目比其余三种convolution types要少很多,单位置(per position)的计算量也要少很多。
获取最新消息链接:获取最新消息快速通道 - lqfarmer的博客 - 博客频道 - CSDN.NET
4、超分离卷积(super-separable convolution)
Super-separable convolution借鉴了group convolution的思想,把输入x从深度方向分解成g个组,然后每个组分别进行separable convolution操作,最终把不同的组的结果拼接起来。注意,通常,通常多个super-separable convolution堆叠在一起,且super-separable convolution中每个channels之间相互独立,没有信息交换。
Super-separable convolution的表达式如公式(1)所示:
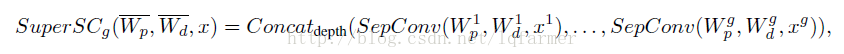
其中,x1....xg表示一个super-separable convolution group中的g(一般g=2或3)个split,(Wp(i),Wd(i)),i=1.....g表示g个的position weight和dimension weight。每个split的dimension卷积操作次数为k*c / g,position映射操作次数为c^2/g^2,一个super-separable convolution group的总计算次数为k*c + c^2 / g。
5、过滤膨胀(filter dilation)和卷积窗口大小
Filter dilation通过增加卷积核的size以获得更多的multiscale information,同时有效避免卷积核增加带来的参数爆炸问题。与filter dilation相似且更简单的方法是选择更多大卷积窗口,但卷积窗口越大,计算量和需要的存储空间也越大。在Depthwise separable convolution网络中,需要更少的计算量进行convolution操作,non-embedding层中的参数可以减少一半,因此,可以空余更多的计算和存储空间用于选择更大的卷积窗口。
6、SliceNet结构
模型的输入和输出都被embedded成相同长度的embedding,采用两个独立的sub-network分别进行encode操作,然后把两个sub-network的输出拼接起来,做为自回归(auto-regressive)decoder的输入。在给定输入x和partial prediction(y1...yi-1)的encoded结果条件下,Auto-regressive decoder每一次预测一个输出yi。SliceNet的网络结构如图1所示。
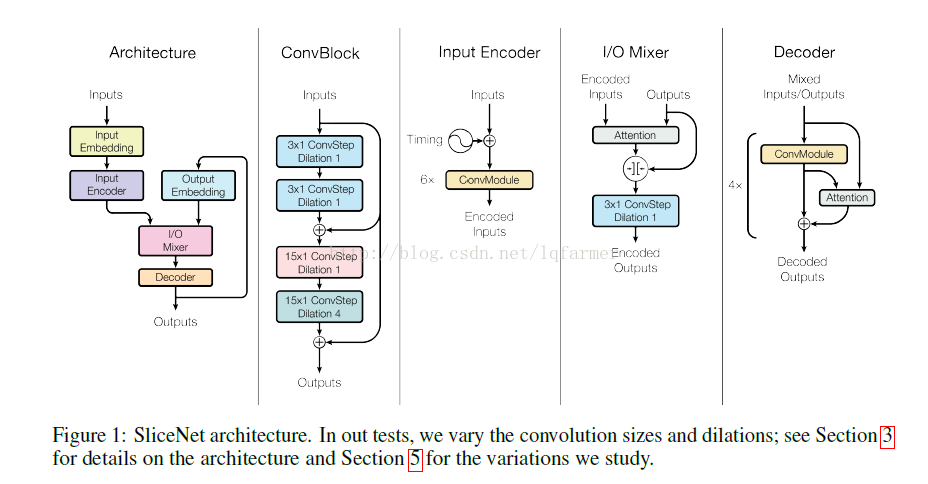
其中,encoder由堆叠的convolution module构成,decoder由堆叠的convolution module+attention module构成。
获取最新消息链接:获取最新消息快速通道 - lqfarmer的博客 - 博客频道 - CSDN.NET
6.1 卷积模块
每一个Convolution step由三个部分组成:对输入x的relu激活,跟着一个Depthwise separable convolution操作SepConv,在跟着一个layer Normalization。(关于layer Normalization详细介绍,参考文章《<优化策略-2>深度学习加速器Layer Normalization-LN》),一个完整的convolution step的计算公式如下所示:
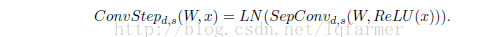
在encoder和decoder中,每个convolution module由多个convolution steps堆叠起来,相互之间采用残差连接(Residual connection)。图1中第二图给出了由4个convolution step和两个skip-connections构成的convolution module(convolution block),表达式如下所示:
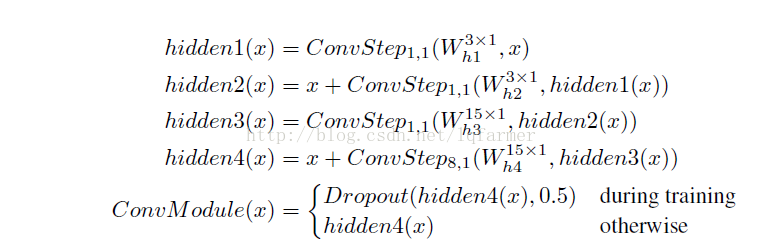
Encoder和decoder中采用堆叠多个convolution Modules的方式。
6.2 attention模块
Attention通过计算source 和target 向量之间内积attention(inner-product attention)的相似度来确定,同时根据sequence的长度进行re-scale,计算公式如下:
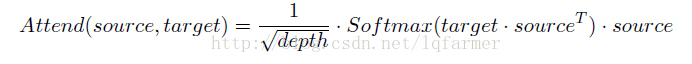
此外,Attention中添加了timing信息,让attention获得输入sequence中的位置信息。Timing(位置)信息的计算方式与《模型汇总16 各类Seq2Seq模型对比及《Attention Is All You Need》中技术详解》类似,采用关于word k的频率的cosine或sine函数计算:
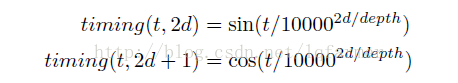
因此,在图1中给出的decoder的attention module结构:先对在target中添加timing信号 ,执行两次convolution step,然后再对source进行attending。整个结构如下公式所示:
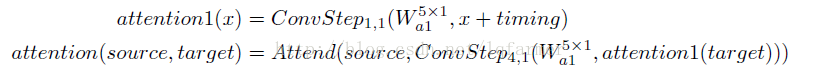
6.3 自回归结构(Autoregressive structure)
如图1所示,模型最终通过自回归(autoregressive)的方式预测output。在基于Depthwise separable convolution的seq2seq模型中,encoder和decoder通过更大的卷积窗口和堆叠的convolution module来学习input sequence和output sequence中的long term dependencies。因此,得到图1所示的,基于super-convolution 的整个seq2seq模型的表达式如下所示:

获取最新消息链接:获取最新消息快速通道 - lqfarmer的博客 - 博客频道 - CSDN.NET
参考文献:
Depthwise Separable Convolutions for Neural Machine Translation
Neural machine translation in linear time
Wavenet: A generative model for raw audio
Conditional image generation with pixelcnn decoders
Multi-scale context aggregation by dilated convolutions;Factorization tricks for LSTM networks
Factorization tricks for LSTM networks
往期精彩内容推荐
《纯干货-6》Stanford University 2017年最新《Tensorflow与深度学习实战》视频课程分享
<纯干货-5>Deep Reinforcement Learning深度强化学习_论文大集合
更多深度学习在NLP方面应用的经典论文、实践经验和最新消息,欢迎关注微信公众号“深度学习与NLP”或“DeepLearning_NLP”或扫描二维码添加关注。
















 4972
4972











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











