






第二十七周学习笔记
毕设做到一半,发现缺少一些计算机视觉和Pytorch、tf的实战经验,根据递归学习法,接下来学习CS231n和Pytorch、tf
CS231n
卷积神经网络(Convolutional Neural Networks(CNNs/ConvNets))
翻译自英文笔记
卷积神经网络与普通的神经网络十分相似:它们由具有可学习的权值和偏置神经元组成,每个神经元接受某些输入,进行点乘操作,后接一层非线性操作,整个神经网络,仍然是一个简单的可导的评分函数:从原始图片到类别得分的映射。而且最后一层上也有损失函数,所有学习常规神经网络的技巧也同样适用
那究竟有何不同,ConvNet假设输入是图片,这使得我们可以将某些特性编码到神经网络架构中,这些特性使得前向传播更加高效并大大减少了网络中的参数
网络架构概述
回忆常规的神经网络,神经网络接受一个向量作为输入,并通过一系列隐层对其进行变换,每层隐层都由一些神经元组成,这些神经元都与前一层的神经元全连接,而某层中的神经元相互独立、互不相连。最后一个全连接层称为“输出层”,在分类任务中它给出类别得分
普通的神经网络并不能很好地应用在图片上,在CIFAR-10中,图片仅仅是32×32×3(宽32,高32,3通道),因此一个全连接网络的第一层有32*32*3 = 3072个权值,这虽然也不是太多,但这种全连接网络并不能适用(scale to)到更大的图片上。比如,一张200×200×3的图片,则需要2002003=120000个权值。这还仅仅是第一层的权值,多层的网络会导致权值数量迅速增加。显然,这种全连接网络是浪费的,而且大量的参数会导致网络迅速过拟合
神经元的三维排列。卷积神经网络利用了图片作为输入的特点并用更合理的方式约束了网络架构。具体地,与传统神经网络不同,ConvNet的神经元以3维形式组成:宽、高、深(与神经网络的深度区分)。例如,CIFAR-10的输入是一个三维32×32×3的数据。我们很快会看到,每层中的神经元仅仅与前一层的一小块区域中的神经元相接,而非全连接。此外,最终CIFAR-10的数据输出应该是1×1×10,因为卷积神经网络的最后一层应该输出各类的的得分向量,这个向量被安排在了深度维。如图所示
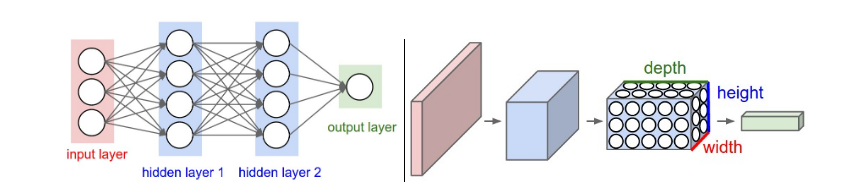
左:一个普通的三层神经网络
右:一个卷积神经网络,它的神经元是一个三维结构,每层网络将3D(volume)输入转化为3D(volume)输出,本例中,红色长方体是代表图片,因此它的宽高分别是图片的宽高,深是3(红、绿、蓝)
神经网络由一系列层组成,每层的功能很简单:通过一些可导的函数(它们可能有也可能没有参数),将输入的3D volume转化为3D volume 输出
小结
ConvNet与传统神经网络相似,但不同的是ConvNet神经元以3D volume排列,将3D volume输入转化为3D volume输出,最后一层输出的得分向量安排在了深度维上
卷积神经网络的层
如前文所述,一个简单的ConvNet由一系列层组成,每层通过可导函数,将一个数据体转化为另一个数据体,我们使用三类层来建立ConvNet架构:卷积层,池化层和全连接层,我们将这些层堆成一个ConvNet架构
示例架构:一个简单的用以分类CIFAR-10的网络架构为【INPUT - CONV - RELU - POOL - FC】:
- INPUT [32×32×3]为输入的宽32,高32,3通道图片
- CONV层计算与输入局部连接的神经元的输出,每个卷积核计算出其权值和其连接区域的内积,这会使得输出为[32×32×12]的输出,如果我们使用12个卷积核
- RELU层会elementwise地应用激活函数,比如 m a x ( 0 , x ) max(0,x) max(0,x),这并不改变输入的维数
- POOL(池化)层在宽高上对输入进行空间下采样,使得输出变成[16×16×12]
- FC(全连接)层计算类别得分,最终得到[1×1×10]的volume,10个数字分别表示对应的类别得分,比如CIFAR-10中的10个类别,全连接层的每个神经元都与前一层的每个神经元相连
这样,ConvNets将原始图片一层层地变换为最终的类别得分。注意有些层有参数,有些没有。具体来说。CONV/FC层有权值和偏置参数,而RELU/POOL层没有。这些在CONV/FC中的参数会通过梯度下降来训练,使得网络输出与预期一致
综上所述:
- ConvNet架构是一系列层将图片输入volume转化为输出volume(比如类别得分)
- 仅仅有几类不同的层(CONV/FC/RELU/POOL 是目前最流行的)
- 每层通过一个可导函数,接受3D volume输入,并将之转化为3D volume输出
- 每层可能有或没有参数(比如CONV/FC有参数,RELU/POOL没有)
- 每层可能有或没有超参数(比如 CONV/FC/POOL有,RELU没有)
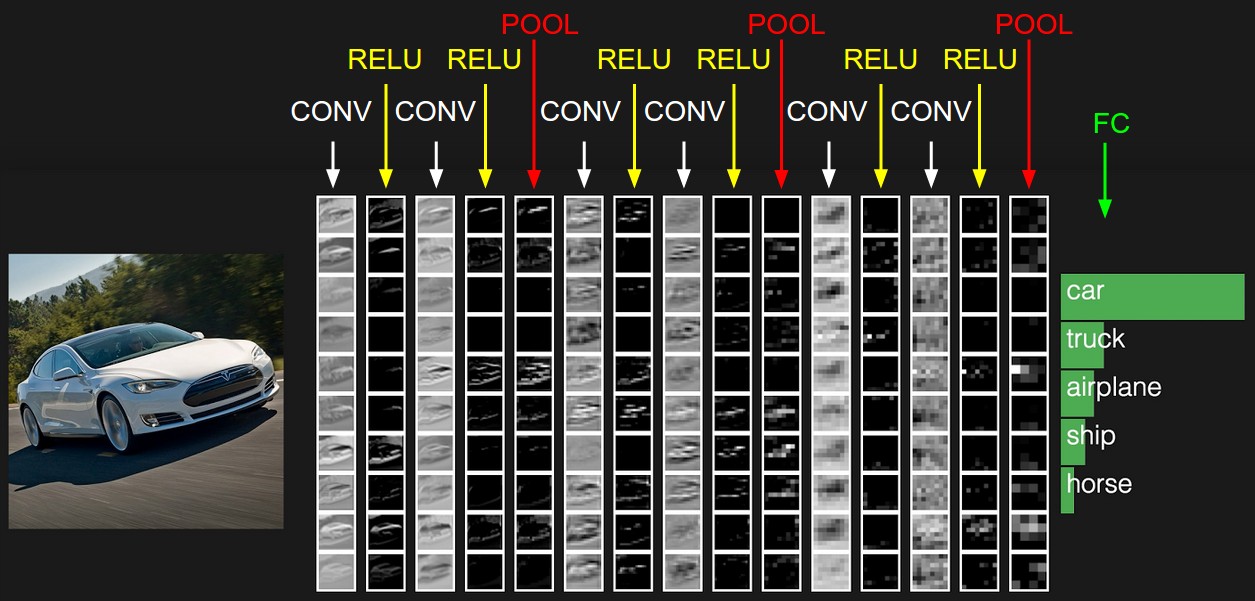
一个ConvNet的例子,起始的volume存储原始图像,最后的volume存储类别得分,每个处理路径上的volume为一列,因为难以进行3D的可视化,我们将每个volume的切片放在每一行,最后一列给出类别得分,但我们只给出了最高的五个得分以及对应类别,这里的网络是VGG Net,之后将讨论到
现在讨论每类层的超参数和连接的细节
卷积层
卷积层是ConvNet的核心块,是计算量消耗最多的部分
与大脑无关的概述和直觉。我们首先不以大脑和神经元的类比来讨论卷积层。卷积层参数包括一系列可学习的滤波器。每个滤波器空间上都很小(在宽高尺度上),但都在输入volume的深度上进行拓展,比如,一个典型的滤波器可能是【5×5×3】的,在前向传播过程中,我们将每个卷积核在输入volume的宽和高的方向上进行滑动,计算点积。随着我们滑动滤波器,我们可以得到一个2维的激活图(activation map),这个激活图给出滤波器在各个空间位置计算出的内积。直观地看,网络会学习得到一些滤波器,在检测到某类视觉特征(边缘,色块)的时候被激活,最终在高层找到整个蜂窝状、或轮状的模式。现在,我们在每层会有一些滤波器(比如12个),每个滤波器会计算不同的二维激活图。我们在深度层排列这些激活图从而得到输出volume
从大脑上来看,如果你是一个大脑或神经元类比的粉丝,每个3D volume输出可以被解释为仅仅看一小块区域输入的神经元的输出,并与左右的神经元共享参数(因为这些滤波器是一样的)。我们接下来讨论神经元连接的细节、它们在空间上的排列以及它们的权值共享机制
局部连接,当处理类似图像的高维输入时,正如前面所述,全连接是不切实际的。作为替代,我们将每个神经元只与输入的局部进行连接,空间上这种连接的拓展是超参数称为神经元的感受野(receptive field)(即滤波器的大小),连接在深度上的感受维度与输入volume深度通常相同。值得强调的是,我们对待各个维度的不对称性:在宽和高上的局部感知以及在深度上的全感知
例1,比如,假设输入volume为[32×32×3],如果感受野(或说滤波尺寸)为5×5,那么每个卷积层中的神经元会有针对[5×5×3]大小区域输入的权值,总共553=75个权值(加上一个偏置项)。注意在深度上连接的拓展必须为3,因为这是输入的深度
例2,假设输入为[16×16×20],使用感受野为3×3的卷积层,那么每个神经元会有3320=180个权值,注意,连接在长宽上局部,但在深度上是全局的
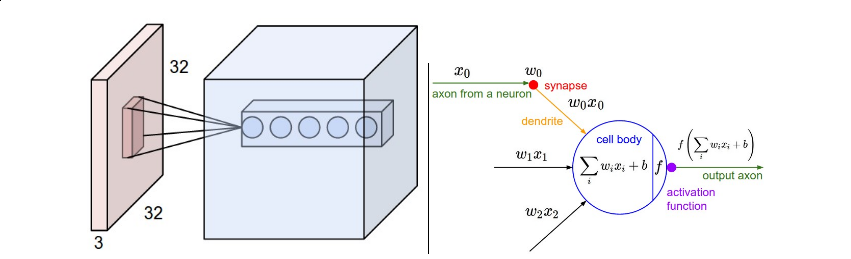
左:红色是一个示例的输入volume(32×32×3),一个示例的神经元volume作为第一个卷积层,每个神经元仅仅与输入volume空间上局部连接,但深度上是全连接的(即所有通道)。注意,在深度上有很多个神经元(本例中是五个),都以相同的区域作为输入,详见下文中的深度列(depth column)
右:神经元的结构保持不变的:它们仍然计算输入和权值的点积并结上一个非线性操作,只是他们的连接被限制为局部连接
空间排列,我们已经解释了每个卷积核中的神经元和输入的连接方式,但我们还没讨论输出volume中有多少神经元以及它们是如何排列的。3个超参数控制了输出volume的尺寸:深度、stride和zero-padding:
- 首先,输出的深度是一个超参数:它与我们使用的滤波器的个数对应,不同的滤波器用来寻找输入中的不同的东西。例如,如果第一个卷积层以原始图像作为输入,则不同深度的神经元会在不同方向的边缘、或不同的颜色出现时激活。我们称一组以相同局部作为输出的神经元为depth column(也有些人称之为fibre)
- 其次,我们必须确定stride,这是我们滑动滤波器的参数。当stride是1的时候我们每次移动滤波器1个像素,stride是2的时候我们每次移动两个像素,此时我们会得到一个空间上更小的输出volume
- 我们很快就能看到,有时在输入volume的边缘用0填充会十分方便,这种zero-padding的大小也是一个超参数。zero padding的一个优点就是它使得我们可以控制输出volume的尺寸(最通常的我们可以通过它来保证输入和输出在宽和高上是相同的)
我们可计算输出volume的尺寸,通过输入尺寸( W W W),感受野的尺寸( F F F),stride( S S S),以及zero padding( P P P)。则输出在对应维上的尺寸为 ( W − F + 2 P ) / S + 1 (W-F+2P)/S+1 (W−F+2P)/S+1。比如一个7×7的输入、3×3的滤波器、stride=1、pad=0,能够得到5×5的输出,stride=2时得到3×3的输出,让我们来看更多的图例:

空间排列的图例,在本例中仅仅有一个空间维(x维),一个神经元只有F=3的感受野,输入的尺寸W=5,zero padding P=1
左:S=1,因此输出的尺寸为(5-3+2)/1+1=5
右:S=2,因此输出的尺寸为(5-3+2)/2+1=3
注意S不能等于3,因为3不能整除(5-3+2)=4
本例中的神经元权值为[1,0,-1](在最右边),偏置是0,这些权值在所有黄色神经元中共享(详见下文中的权值共享)
zero-padding的使用,在上面最左边的例子中,注意到输入维数是5,而输出维数也是5,这是因为感受野是3而且zero padding是1,如果没有zero-padding的使用,输出的维数会是3,因为这是神经元能够填入输出中的个数。通常,当S=1时,令padding为 P = ( F − 1 ) / 2 P=(F-1)/2 P=(F−1)/2可以保证输入和输出空间尺寸相同,这样使用zero-padding是非常普遍的,在讨论ConvNet架构时我们会说明全部原因
stride的限制,注意空间超参数会有相互的限制,例如,当 W = 10 W=10 W=10, P = 0 P=0 P=0, F = 3 F=3 F=3时, S = 2 S=2 S=2是不可能的,因为 ( W − F + 2 P ) / S + 1 = ( 10 − 3 + 0 ) / 2 + 1 = 4.5 (W-F+2P)/S+1=(10-3+0)/2+1=4.5 (W−F+2P)/S+1=(10−3+0)/2+1=4.5,不是一个整数,表明神经元不fit,无法对称地处理输入,因此,这组超参数设定是非法的,ConvNet库会抛出一个异常或者使用zero pad、裁切输入来使它适应。正如我们将在ConvNet架构小节看到的,让ConvNets的各个超参数相互匹配会是一件十分头疼的事情,但使用了zero-padding或一些设计指南会让这一问题大大缓和
真实的例子,Krizhevsky et al的架构,在2012年ImageNet挑战上胜利,它接受输入[227×227×3],。在第一个卷积层,它使用神经元的感受野为 F = 11 F=11 F=11, S = 4 S=4 S=4, P = 0 P=0 P=0。而 ( 227 − 11 ) / 4 + 1 = 55 (227-11)/4+1=55 (227−11)/4+1=55,而卷积层的深度为 K = 96 K=96 K=96,因此卷积层的输出尺寸为[55×55×96]。这55*55*96中的每个神经元都与一个尺寸为[11×11×3]的输入volume相连。此外,所有在相同depth column 中的96个神经元都与相同的[11×11×3]的输入区域相连,但会有不同的权值。有趣的是,当你读它们的论文时,它们声称输入的图片是224×224的,但(224-11)/4+1不是一个整数,因此这个声明是不对的。这一点让历史上很多人都很困扰而很少人知道到底发生了什么。我的猜测是Alex使用了 P = 3 P=3 P=3的zero-padding,而它在文章中却未提及
参数共享,权值共享在卷积层中使用,并用来控制参数的个数,使用前文的例子,可以看到第一层有55*55*96=290400个神经元,每个有11*11*3=363个权值和1个偏置,这总共有290400*364=105705600个参数,显然,这个数字十分大
我们可以显著减少这个值,只要我们作出一个假设:如果一个特征在计算某个空间位置(x,y)有用,那么它在计算(x2,y2)时也有用,换言之,记一个2维的深度切片为depth slice(比如一个[55×55×96]的volume)有96个depth slice,我们将要在同一个depth slice中的神经元共享参数,使用相同的权值和偏置。通过这种参数共享机制,第一层仅仅会有96组不同的权值,总共96*11*11*3=34848个不同的权值,或34944个参数(+96个偏置)。换句话说,所有在同一层depth slice中的55*55个权值会使用相同,在反向传播的时候,每个神经元都会计算对于它的权值的梯度,同一depth slice中神经元的梯度会累加起来更新该depth slice中的权值
注意当一个depth slice使用相同的权值向量时,前向过程可以看作为神经元权值和输入图像的卷积(因此叫卷积层),因此我们也将这组权值称为滤波器(或核)

Krizhevsky实验中学习到的卷积核,每个滤波器的尺寸是[11×11×3],且每个的权值被55*55个同depth slice的神经元共享。注意,权值共享的假设是相对合理的:如果检测一个水平的边缘在图片中的某个位置是重要的,那么它在图片的其他位置也是重要的,这是由于图片的平移不变性。因此不需要这55*55个神经元重新学习检测水平边缘的能力
注意,有时权值共享的假设可能不合理,特别是输入是某些特别的中心结构时,此时我们应该期望在图片的不同位置学习到不同的特征。一个实际的例子是,当输入是位于图片中心的人脸时。你可能期望不同的眼部或头发的特征可以在不同的空间位置被学习到。此时通常会缓和权值共享机制,而使用Locally-Connected 层
Numpy 例子,为了让上面的讨论更加具体,我们使用代码来举几个例子,假设输入volume是一个numpy数组X,则
- (x,y)位置的depth column是X[x,y,:]
- depth slice,或深度为d的激活图应该是X[:,:,d]
卷积层示例,假设输入volume X X.shape:(11,11,4),假设我们使用 P = 0 P=0 P=0、 F = 5 F=5 F=5、 S = 2 S=2 S=2,输出volume则是 ( 11 − 5 ) / 2 + 1 = 4 (11-5)/2+1=4 (11−5)/2+1=4,给一个volume宽和高分别为4,则输出volume的激活图(称为 V V V),会如下所示(仅仅一部分元素在本例中被计算)
V[0,0,0] = np.sum(X[:5,:5,:]*W0)+b0
V[1,0,0] = np.sum(X[2:7,:5,:]*W0)+b0
V[2,0,0] = np.sum(X[4:9,5,:]*W0)+b0
V[3,0,0] = np.sum(X[6:11,:5,:]*W0)+b0
回忆在numpy中,*表示数组的逐个元素的乘法:注意权值数组W0是神经元的权值向量b0是偏置项,这里,W0.shape=(5,5,4),因为滤波器的尺寸为5而输入的深度为4,注意在每一点,我们如之前一样计算点积。我们也要注意我们使用了相同的权值和偏置(因为权值共享),卷积核在宽上的stride为2,为了建立输出volume的第二个激活图,我们有:
V[0,0,1] = np.sum(X[:5,:5,:] * W1) + b1
V[1,0,1] = np.sum(X[2:7,:5,:] * W1) + b1
V[2,0,1] = np.sum(X[4:9,:5,:] * W1) + b1
V[3,0,1] = np.sum(X[6:11,:5,:] * W1) + b1
V[0,1,1] = np.sum(X[:5,2:7,:] * W1) + b1
V[2,3,1] = np.sum(X[4:9,6:11,:] * W1) + b1
我们可以看到我们进入了V的第二个深度维(即1),因为我们在计算第二个激活图,因此使用了不同的参数(W1),在前面的例子中,我们省略了计算V的全部过程,此外,我们也忽略了ReLU操作
总结,综上所述,卷积层:
- 接受尺寸为 W 1 × H 1 × D 1 W_1×H_1×D_1 W1×H1×D1作为输入
- 需要四类超参数
- 滤波器的个数 K K K
- 空间拓展(spatial extent)卷积核尺寸 F F F
- stride S S S
- zero padding P P P
- 输出一个
W
2
×
H
2
×
D
2
W_2×H_2×D_2
W2×H2×D2的输出,其中
- W 2 = ( W 1 − F + 2 P ) / S + 1 W_2=(W_1-F+2P)/S+1 W2=(W1−F+2P)/S+1
- H 2 = ( H 1 − F + 2 P ) / S + 1 H_2=(H_1-F+2P)/S+1 H2=(H1−F+2P)/S+1
- D 2 = K D_2=K D2=K
- 通过权值共享,每个滤波器有 F ⋅ F ⋅ D 1 F\cdot F\cdot D_1 F⋅F⋅D1个权值,总共 ( F ⋅ F ⋅ D 1 ) ⋅ K (F\cdot F\cdot D_1)\cdot K (F⋅F⋅D1)⋅K个权值和K个偏置
- 在输出volume中,第d个depth slice的尺寸是( W 2 × H 2 W_2×H_2 W2×H2),是由第d个滤波器与第d个偏置与输入计算得出的
一个通常的超参数设定为 F = 3 , S = 1 , P = 1 F=3,S=1,P=1 F=3,S=1,P=1,然而,也有一些约定俗成的超参数设定方法,详情参看后面的卷积网络架构小节
动态图示例见原网页
实现为矩阵乘法,注意到卷积操作本质上是滤波器和输入的一个局部进行点乘,利用这个性质,一个通常的做法是将卷积层实现为一个大的矩阵乘法:
- 通过im2col操作,输入的局部区域矩阵被拉成一列。举个例子,如果输入是[227×227×3]而它将与一个11×11×3的卷积核卷积,且stride=4,我们将以[11×11×3]的块作为输入,并将每个块拉成11*11*3=363的列向量。按照stride=4重复这个操作,在宽和高方向上均重复(227-11)/4+1=55次,于是im2col输出矩阵
X_col的大小是[363×3025],其中每一列都是感受野拉成的向量,总共有55*55列。注意到,局部感受野之间是有重叠的,因此,原输入中的一个位置的输入值会在转化后的多列中出现 - 卷积层也相似地被拉成向量,比如,如果有96个尺寸为[11×11×3]的卷积核,则我们可以得到
W_row的尺寸为[96×363] - 现在卷积操作就与一个大的矩阵乘法等价,即
np.dot(W_row, X_col),这将每个卷积核和每个感受野相乘,在本例中,输出的尺寸是[96×3025]。 - 最终的输出需要reshape为[55×55×96]
这种方法的不足之处是将会消耗大量的内存,因为一些输入值在X_col中重复出现,然而,好处在于我们可以因此利用很多高效的矩阵乘法的算法实现,此外,im2col也可以被用来进行池化操作,我们将在之后进行讨论。
反向传播,卷积操作的反向传播也是一个卷积(,但需要spatially-flipped的滤波器),这很容易举一个1维的例子(暂不讨论)
1×1 卷积,一方面,一些论文使用了1×1卷积,最先在Network in Network这篇文章中被研究。一些人最初对于1×1卷积十分困惑,尤其是那些信号处理背景的人,通常情况下信号是2维的,因此1×1卷积没有意义。然而,在ConNet中不是这样,因为我们要记住我们是在三维volume上进行操作,卷积核总是在深度上与输入相同,比如,如果输入是[32×32×3]然后做1×1卷积将是一个3维的点积(因为输入的深度是3通道)
扩张卷积(Dilated convolution),最近的发现引入了一个有更多超参数的卷积层,名叫(dilation)[https://arxiv.org/abs/1511.07122]。目前我们仅仅讨论了contiguous的卷积核,然也,也可能有在每个小格子之间有空隙的卷积核,称为dilation。举个例子,在某一维上尺寸为3的一个卷积核w将与输入x按以下方式计算:w[0]*x[0] + w[1]*x[1] + w[2]*x[2],这是dilation为0的情况。dilation为1时,我们将计算w[0]*x[0] + w[1]*x[2] + w[2]*x[4]。相比0 dilation的情况这可以让你通过更少的层来更多地融合空间信息。举个例子,如果你重叠两个3×3卷积层,那么在第二个卷积层每个卷积核得到的就是输入的5×5的局部信息。而我们使用dilated convolution则可以加快这个过程。
下周目标
完成cs231n的笔记学习














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









