









转载请注明出处:勿在浮沙筑高台http://blog.csdn.net/luoshixian099/article/details/51811945
决策树
决策树模型是一种树形结构,基于特征对实例进行分类或回归的过程。即根据某个特征把数据分划分到若干个子区域(子树),再对子区域递归划分,直到满足某个条件则停止划分并作为叶子节点,不满足条件则继续递归划分。
一个简单的决策树分类模型:红色框出的是特征。
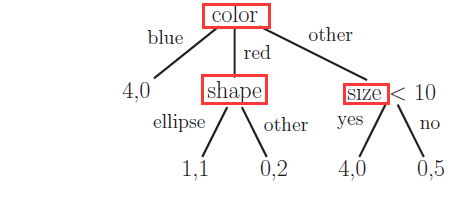
决策树模型学习过程通常包3个步骤:特征选择、决策树的生成、决策树的修剪。
1.特征选择
选择特征顺序的不同将会产生不同决策树,选择好的特征能使得各个子集下标签更纯净。度量特征对产生子集的好坏有若干方法,如误差率,信息增益、信息增益比和基尼指数等。
1.1误差率
训练数据D被特征A分在若干子结点后,选择子节点中出现数目最多的类标签作为此结点的返回值,记为
yc^
。则误差率定义为
1.2信息增益
熵与条件熵:熵表示随机变量不确定性的度量。设计随机变量X为有限离散随机变量,且
pi=P(X=xi)
。熵的定义为
H(X)=−∑ni=1pilog(pi)
。熵越大,随机变量的不确定性就越大,当X取某个离散值时概率为1时,则对应的熵H(X)为0,表示随机变量没有不确定性。条件熵:表示已知随机变量X的条件下随机变量Y的不确定性,定义
H(Y|X)=∑ni=1piH(Y|X=xi)
,其中
pi=P(X=xi)
。这里X表示某个特征,即表示根据某个特征划分后,数据Y的熵。如果某个特征有更强的分类能力,则条件熵H(Y|X)越小,表示不确定性越小。
信息增益:特征A对训练数据集D的信息增益定义为g(D,A)=H(D)-H(D|A).即有特征值A使得数据D的不确定性下降的程度。所以信息增益越大,表明特征具有更强的分类能力。
1.3信息增益比
信息增益比也是度量特征分类能力的方法。定义训练数据D关于特征A的值的熵
HA(D)=−∑ni=1|Di||D|log2(|Di||D|)
,
|D|
表示训练数据的总数,
|Di|
表示训练数据D中特征A取第i个值的总数目。信息增益比越大,表明特征分类能力越强。
1.4基尼指数
假设随机变量X可以取K的离散值,
p(X=k)=pk
则X的基尼指数定义为:
Gini(X)=∑Kk=1pk(1−pk)=1−∑Kk=1p2k
.对于给定的样本集合D,其基尼指数为
Gini(D)=1−∑Kk=1(|Ck||D|)2
,
|Ck|
是D中属于第k类的样本个数,K是类的个数。基尼指数表示样本集合的不确定性程度,所以基尼指数越小,对应的特征分类能力越强。
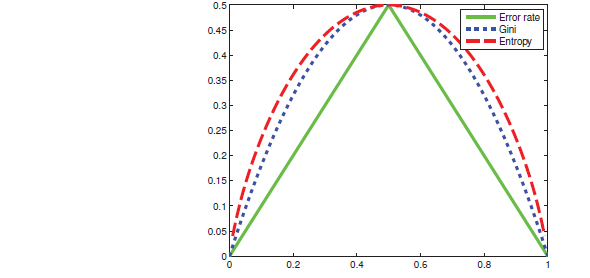
下图表示一个二分类的情况下,度量样本集合的不确定性程度几种方法。熵(Entropy),基尼指数(Gini),误差率的关系(Error rate).为了方便比较熵被缩小一半。
2.决策树的生成
ID3与C4.5都是决策树的经典分类决策树算法。唯一不同的是ID3算法采用信息增益作为特征选择准则,而C4.5采用的是信息增益比的方法。下面介绍ID3决定树生成算法的过程,C4.5类似。
ID3算法
从根节点开始,在数据集D上计算所有可能的特征A分别计算信息增益,选择信息增益最大的特征作为分类条件,对该特征不同的取值分别建立子集作为子节点,最对子集递归地调用以上方法。直到没有特征可以选择或者信息增益很小为止。
下面的代码来自《机器学习实战》
def createTree(dataSet, labels) :
classList = [example[-1] for example in dataSet]
if classList.count(classList[0] ) == len(classList) :#数据集全部属于同一个类别
return classList[0] #返回这个类别,并作为叶子结点
if len(dataSet[0]) == 1: #没有特征可以选择
return majorityCnt(classList) #返回数目最多的类别,并作为叶子结点
bestFeat = chooseBestFeatureToSplit(dataSet) #选择信息增益最大的特征A
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel : {}}#建立结点
del (labels[bestFeat]) #特征集中去除特征A
featValues = [example[bestFeat] for example in dataSet] #特征A下的所有可能的取值
uniqueVals = set(featValues)#去重
for value in uniqueVals: #对可能取值分别建立子树
subLabels = labels[ : ]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)#递归建立子树
return myTree3.决策树剪枝
不考虑复杂度的情况下,一个完全生长树很容易过拟合,对训练数据拟合很好,但对预测数据效果很差。因此要对生成的决策树做修剪,剪掉一些不必要的branch.可以通过增加正则项来控制决策树的复杂度。定义
Cα(T)
表示决策树的损失,
C(T)
表示模型对训练数据的预测误差。
|T|
表示模型的复杂度,即叶子节点的数目。
参数 α 权衡训练误差与模型复杂度。
(1)计算每个节点的经验熵
(2)递归地从树的叶节点向上回溯,计算叶节点回溯到父节点之前与之后的损失 Cα(TB) 与 Cα(TA) ,如果 Cα(TA)<Cα(TB) ,代表修剪此节点后,损失函数更小,则进行剪枝。
(3)返回(2),直到不能继续为止。
4.CART算法
CART(Classification and regression tree)算法一种即能做分类又能做分类的决策树算法。
特征选择
回归树采用平方误差最小化准则:数据集D的平方误差定义为
∑|D|i=1(yi−y′)2
,其中
y′
表示数据集D的平均值。
分类树选择基尼指数最小化准则。
CART树生成
回归树的生成
(1)考虑数据集D上的所有特征,遍历每一个特征下所有可能的取值或者切分点,对数据集D划分成两部分 D1 和 D2
(2)分别计算上述两个子集的平方误差和,选择最小的平方误差对应的特征与分割点,生成两个子节点。
(3)对上述两个子节点递归调用(1)(2),直到没有特征可以选择,或者子节点数目很小或者平方误差小于阈值为止,作为叶子节点,并返回节点内样本的均值(也可以在叶子节点内训练回归模型作为预测值)。分类树的生成
(1)考虑数据集D上的所有特征,遍历每一个特征下所有可能的取值或者切分点,对数据集D划分成两部分 D1 和 D2
(2)分别计算上述两个子集的基尼指数的和,选择最小的基尼指数的和对应的特征与分割点,生成两个子节点。
(3)对上述两个子节点递归调用(1)(2),直到没有特征可以选择,或者子节点数目小于阈值或者基尼指数小于阈值为止,作为叶子节点,并返回类别数目最多的类别。
CART的剪枝
CART的剪枝算法,从决策树 T0 的底端不断剪枝,直到根节点。计算完全生长树的内部的每一个结点t的剪枝系数g(t),剪枝系数代表修剪后整体损失减小的程度,即修剪前与修剪后的数据的误差下降的程度。在 T0 中剪去最小的g(t),得到的子树作为 T1 ,如此剪下去,直到根节点。利用独立的验证集,测试子树序列 T0,T1,T2...,Tn 每个子树的平方误差或者基尼指数。数值最小的决策树作为最优的决策树。
5.随机森林
最简单的RF(Random Forest)算法是bagging+完全生长CART树的组合。
通过bagging方法是建立多个分类或者回归模型,最后采用投票或平均作为预测值,可以降低过拟合。
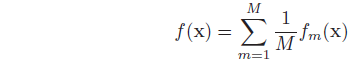
bagging对训练样本采用boostrap采样方法进行M轮,分别建立决策树。由于每轮采用出的样本子集基本不相同,训练的模型相关性会降低小。为了进一步降低模型间的相关性,每轮训练前可以对训练数据的特征进行随机采样,也可以在决策树的每个branch上进行随机特征选择。
Reference:
统计学习方法-李航
MLAPP-Kevin P. Murphy














 4885
4885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









