






1 dropout简介
1.1 dropout出现的原因
在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。
过拟合表现:模型在训练数据上损失函数较小,预测准确率较高,但是在测试数据上损失函数比较大,预测准确率较低。
dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果。
dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。对于随机梯度下降来说,由于是随机丢弃,因此每一个mini-batch都在训练不同的网络。
1.2 什么是dropout
在前向传播的时候,让某个神经元的激活值以一定的概率 p 停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部特征。
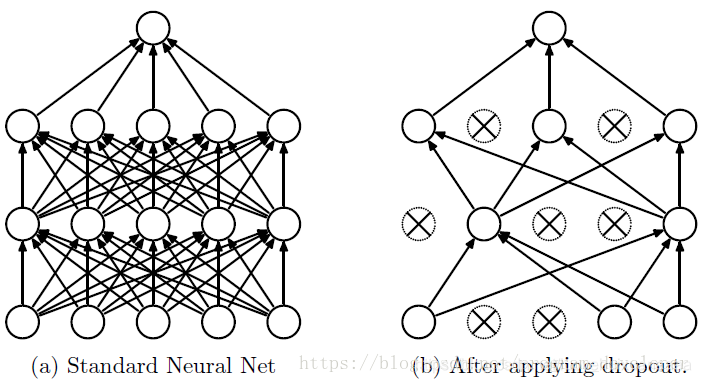
2 dropout工作流程及使用
2.1 dropout在神经网络中的使用
dropout的具体工作流程上面已经详细的介绍过了,但是具体怎么让某些神经元以一定的概率停止工作?代码层面如何实现呢?
(1)在训练模型阶段
在训练网络的每个单元都要添加一道概率流程。
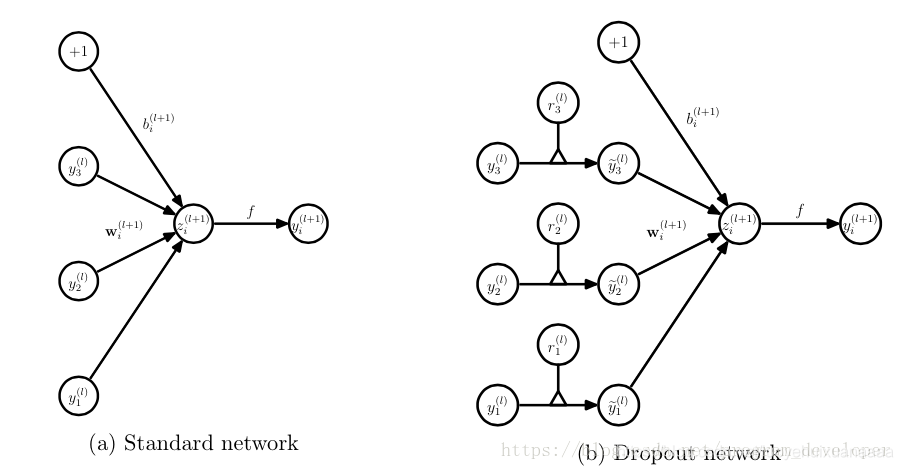
对应的公式变化如下:
没有dropout的网络计算公式:
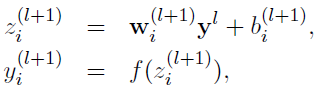
采用dropout的网络计算公式:
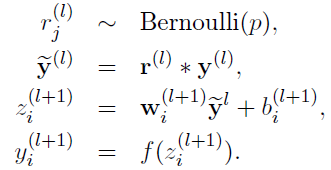
注意:经过上面屏蔽掉某些神经元,使其激活值为0以后,我们还需要对向量 y1, ... , y1000进行缩放,也就是乘以 1 / (1-p)。如果你在训练的时候,经过置0后,没有对 y1, ... , y1000进行缩放(rescale),那么在测试的时候,就需要对权重进行缩放。操作如下:
(2)在测试模型阶段
预测模型的时候,每一个神经元的权重参数要乘以概率p。
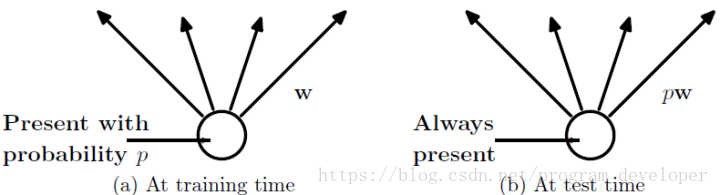
测试阶段dropout公式:
![]()
3 为什么说dropout可以解决过拟合?
1 取平均的作用
先回到标准的模型即没有dropout,我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用 “5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。
这种“综合起来取平均”的策略通常可以有效防止过拟合问题。因为不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消。
dropout掉不同的隐藏神经元就类似在训练不同的网络,随机删掉一半隐藏神经元导致网络结构已经不同,整个dropout过程就相当于对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。














 31万+
31万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









