







近来,在CV领域里针对NN或ANN查询,设计了许多压缩编码方式,将高维向量压缩成64-bit 或128-bit来表示。这些方法大体上可以分为两类,PQ-based methods and Hashing-based method。
最近,试图直接使用这种压缩编码方式来解决自己的问题。因此,很想知道两者到底哪个效果更好。今天在看Norouzi的文章的时候,发现它前后的文章已经给出了一些结论,就此我试图解释可能存在的原因。
下面两幅图分别是Norouzi在PAMI14和CVPR13上发表的文章的截图。注意,PAMI14的文章是CVPR12文章的扩展。估计,之后Norouzi也认识到PQ的优势,果断的研究出了CK-MEANS。只是CV里面做实验的比较一般不全面。做PQ的好像一般不和hashing比,hashing也不和PQ比。这当然是我的印象,没有足够的经验。
好了,还是看图吧。首先,这两幅图都有两个数据集1M SIFT 和 1B SIFT,而且都有64bit的编码。因此,这两个结构可以直接拿来用了。所以,对两个图,分别取1M和1B的结果,编码长度都是64bit。hashing取MLH64结果,而PQ取ck-means结果。recall@R/K取1000.结果如下表。
| data set | 1M SIFT | 1B SIFT |
| MLH | 约90% | 约50% |
| CK-MEANS | 约100% | 约90% |

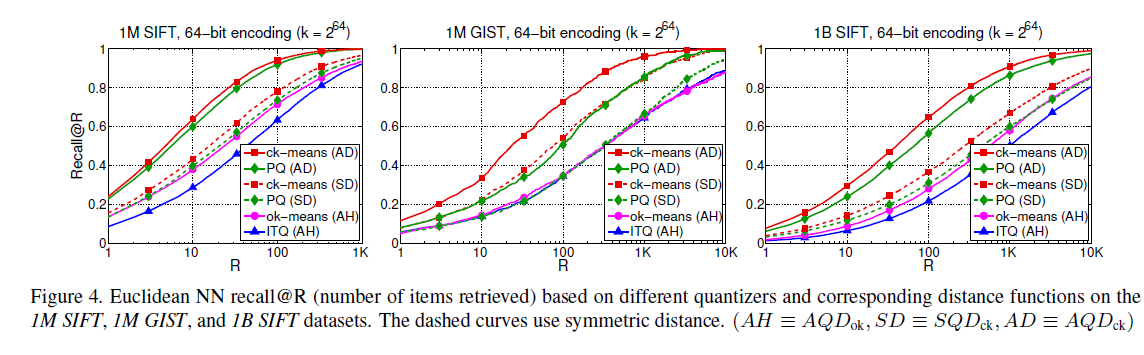
因此,基于以上观察的结果来看,PQ系方法应该好于hashing系的方法,考虑相同的bit数。但我想hashing系的方法要比PQ系的方法要快。毕竟,hashing系方法进行计算的时候是比特位异或操作,而PQ系方法则要进行加法操作。当然hashing系的快。但快的话,精确性就不够好。可见,相同的存储,计算量大,可以释放更多的信息量。这也是空间换时间的基本思路了。
就此问题,今天发了封邮件问Norouzi,正在等回复。
*******************************************************************************************
ok, 今天收到Norouzi的回复了,他已经大致确定了我的看法。他回复到
Personally, I think that there is more promise in pursuing approaches based on PQ and ck-means which can be thought of as integer embedding techniques, in contrast to binary embedding techniques.
但是,还是需要注意的是,毕竟bitwise的操作,比加法操作要快的多了。因此,PQ可能在时间效率上是不占便宜的。
所以,如果把精确性看作时间的函数,谁胜谁负还不知道呢。估计应该是binary embedding好些。不过,我关注的是IO环境下的查询,这些与IO相比,微不足道。哈哈。。。。















 234
234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









