







(1)使用技术
python 3.5.2、requests 、BeautifulSoup
(2)背景介绍
爬取的网站http://tu.duowan.com/tag/5037.html
需要爬取的内容是网站上面的图片
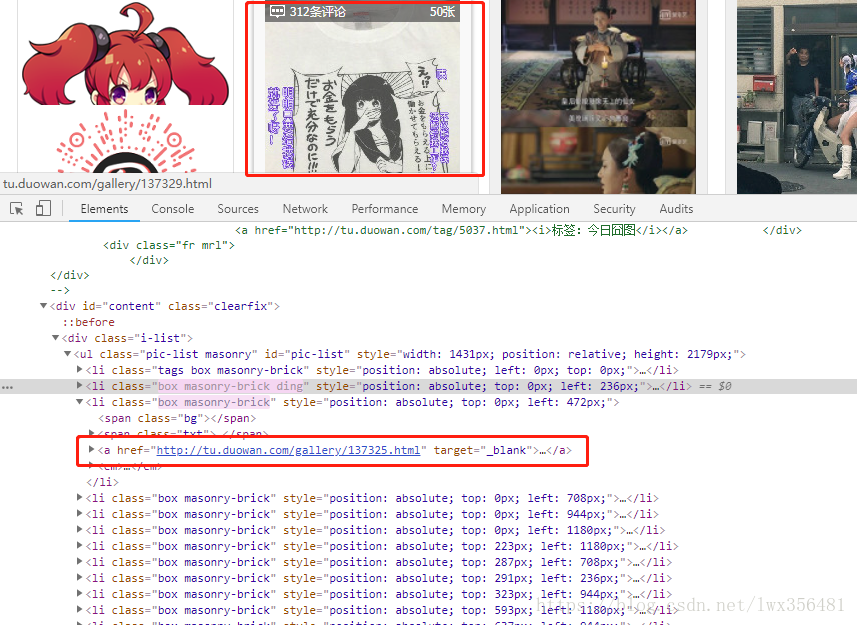
- 首先我们观察一下今日囧途的每个图片点进去之后,会有详情页面。而这个想进入详情页面,我们必须要先爬取到这些url。之后通过url,然后进入页面也就是红框的的url
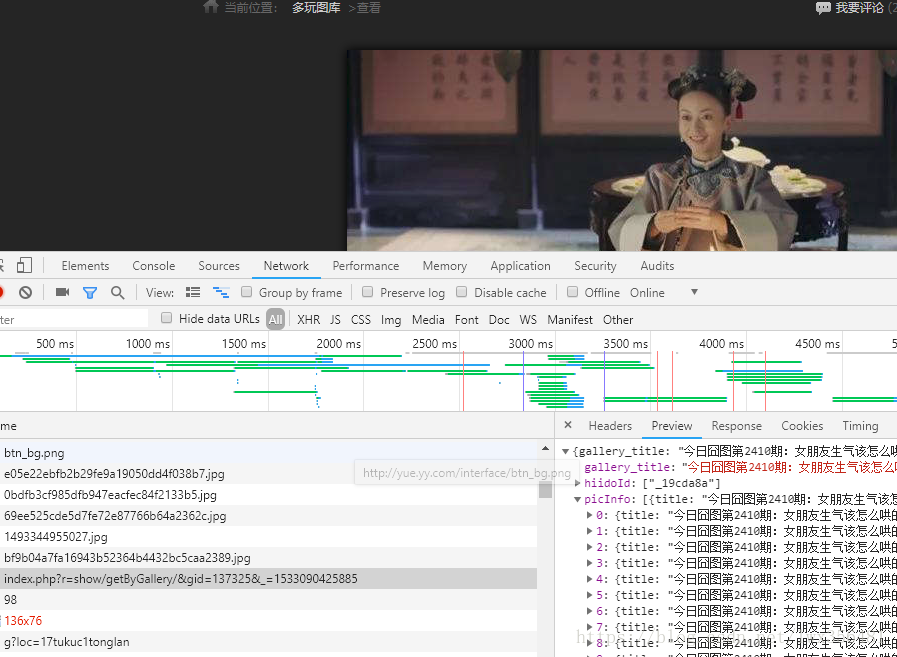
- 然后进入详情页面之后,我们可以用开发者工具查看是否有链接返回图片的信息,发现有个请求里面返回了所有的picInfo。好的这个时候爬取图片的思路就很清晰了,先到今日囧图的首页爬取到每个网页的信息,然后再到详情页面里面将所有的图片信息获取,之后将图片下载下来。
(3)详细代码
import requests
from bs4 import BeautifulSoup
import json
import os
#用来获取今日囧图所有的url
def get_today_urls(url):
today_urls = []
res = requests.get(url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,"html.parser")
for url in soup.select(".i-list li em a"):
today_urls.append(url['href'])
return today_urls
#根据每个url来获取每个囧图界面里面的具体的内容
def get_details(url):
url_param = url.split("/")[-1].split(".")[0]
detail_url = "http://tu.duowan.com/index.php?r=show/getByGallery/&gid={}".format(url_param)
res = requests.get(detail_url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,"html.parser")
json_str = json.loads(str(soup))
dir_name =json_str['gallery_title']
dir_name = dir_name.split(":")[0]
print(dir_name)
if not os.path.exists(dir_name):
os.mkdir(dir_name)
pic_info = json_str["picInfo"]
return pic_info , dir_name
#根据具体页面里面获取的图片的地址,来将图片保存到本地来。
def save_pic(url,dir_name):
pic = requests.get(url)
pic.encoding = 'utf-8'
pic_name = url.split("/")[-1]
pic_dir = os.path.join(dir_name , pic_name)
if not os.path.exists(pic_dir):
with open(pic_dir,"wb") as f:
f.write(pic.content)
f.close()
def get_duowan_pic():
#今日囧图首页的url,用来传入get_today_urls(url)中获取今天所有的囧图的url
url = "http://tu.duowan.com/tag/5037.html"
today_urls = get_today_urls(url)
for today_url in today_urls:
pic_info, dir_name = get_details(today_url)
for pic in pic_info:
save_pic(pic["source"], dir_name)
def main():
get_duowan_pic()
#函数入口
if __name__ == '__main__':
main()代码相对比较简单,有问题的话,大家可以一起讨论。
版权声明: 原创文章,如需转载,请注明出处。 https://blog.csdn.net/lwx356481/article/details/81325880














 2325
2325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









