









基于Keras对图像随机裁剪并同时变换image和mask的数据增广方法
总所周知,Keras自带对图像数据进行预处理的函数,但是该函数是对整张图像进行预处理。在进行图像的语义分割的网络中,当图像尺寸较小,且数据量足够的时候确实可以直接进行resize,投入到网络进行训练。但到图像太大,且数据量不多时,显然不能这样做。比如遥感的语义分割图像,一般的尺寸都是几千乘以几千,且图像的数量并不是很多,这时候就需要先对图像和mask同时进行裁剪成相同的大小,并可以进行适当的数据增广以便使网络具有更好的泛化性能。
第一种方法是每对数据裁剪一次就进行一次数据增广的操作:from PIL import Image
from keras.preprocessing.image import ImageDataGenerator
import numpy as np
from tqdm import tqdm
import random
import os
img_w = 256
img_h = 256 #要切割的图像尺寸
'''
读取指定文件夹下的图像名称
'''
def file_name(file_dir):
L=[]
for root, dirs, files in os.walk(file_dir):
for file in files:
img_name = os.path.split(file)[1]
L.append(img_name)
return L
'''
image_num:生成裁剪图像的总数量
src_url:原图路径
label_url:对应的label路径
'''
def creat_dataset(image_num ,src_url,label_url):
#Keras图片生成器具体方法和参数可以自己设置
data_gen_args = dict(featurewise_center=True,
featurewise_std_normalization=True,
width_shift_range=0.2,
height_shift_range=0.2,
rotation_range=45,
horizontal_flip=True,
zoom_range=0.2)
image_datagen = ImageDataGenerator(**data_gen_args)
mask_datagen = ImageDataGenerator(**data_gen_args)
seed = 1
print('creating dataset...')
image_sets=file_name(src_url);
image_each = image_num /len(image_sets)
g_count=1
for i in tqdm(range(len(image_sets))):
count = 0
src_img = Image.open(src_url+'/' + image_sets[i]) # 3 channels
label_img = Image.open(label_url+'/' + image_sets[i]) # 3 channels
while count < image_each:
#对图像进行随机裁剪
width1 = random.randint(0, src_img.size[0] - img_w)
height1 = random.randint(0, src_img.size[1] - img_h)
width2 = width1 + img_w
height2 = height1 + img_h
src_roi=src_img.crop((width1, height1, width2, height2))
label_roi=label_img.crop((width1, height1, width2, height2))
src=np.asarray(src_roi)
src = src.reshape((1,) + src.shape) #增加维度,将(256,256,3)变成(1,256,256,3)
label=np.asarray(label_roi)
label = label.reshape((1,) + label.shape)
# print('src_shape:{},label_shape:{}'.format(src.shape,label.shape))
i=0 #对每张裁剪的图片进行增广的次数,这里是2次,所以最终生成的图像数据应该是image_num*i
for src_batch in image_datagen.flow(src, batch_size=1,save_to_dir='./data/train_src/',save_prefix=g_count, save_format='tif', seed=seed):
i+=1
if i>=2:
break
j=0
for mask_batch in mask_datagen.flow(label,batch_size=1,save_to_dir='./data/train_label/',save_prefix=g_count, save_format='tif', seed=seed):
j+=1
if j>=2:
break
count += 1
g_count+=1
if __name__=='__main__':
creat_dataset(20,'./data/src','./data/label')
结果:
 裁剪的图像 裁剪的图像 |  对应的mask 对应的mask |
|---|
第二种方法是先将裁剪的数据存储到numpy中,从numpy中读取数据在进行数据增广:
# -*- coding: utf-8 -*-
"""
Created on Tue Mar 12 16:46:20 2019
@author: 伊
"""
from PIL import Image
from keras.preprocessing.image import ImageDataGenerator
import numpy as np
from tqdm import tqdm
import random
import os
img_w = 256
img_h = 256
'''
读取指定文件夹下的图像名称
'''
def file_name(file_dir):
L=[]
for root, dirs, files in os.walk(file_dir):
for file in files:
img_name = os.path.split(file)[1]
L.append(img_name)
return L
'''
image_num:生成裁剪图像的总数量
src_url:原图路径
label_url:对应的label路径
'''
def creat_dataset(image_num ,src_url,label_url):
image_sets=file_name(src_url);
image_each = image_num /len(image_sets)
src=[]
label=[]
for i in tqdm(range(len(image_sets))):
count = 0
src_img = Image.open(src_url+'/' + image_sets[i]) # 3 channels
label_img = Image.open(label_url+'/' + image_sets[i]) # 3 channels
while count < image_each:
#对图像进行随机裁剪
width1 = random.randint(0, src_img.size[0] - img_w)
height1 = random.randint(0, src_img.size[1] - img_h)
width2 = width1 + img_w
height2 = height1 + img_h
src_roi=src_img.crop((width1, height1, width2, height2))
label_roi=label_img.crop((width1, height1, width2, height2))
src_roi=np.asarray(src_roi)
label_roi=np.asarray(label_roi)
src.append(src_roi)
label.append(label_roi)
count+=1
src=np.asarray(src)
label=np.asarray(label)
print('src_shape:{},label_shape:{}'.format(src.shape,label.shape))
return src,label
def gen_dataset():
image_num=20
img_src,img_label=creat_dataset(image_num,'./data/src','./data/label')
#Keras图片生成器具体方法和参数可以自己设置
data_gen_args = dict(featurewise_center=True,
featurewise_std_normalization=True,
width_shift_range=0.2,
height_shift_range=0.2,
rotation_range=45,
horizontal_flip=True,
zoom_range=0.2)
print("begein data_gen......")
image_datagen = ImageDataGenerator(**data_gen_args)
mask_datagen = ImageDataGenerator(**data_gen_args)
seed = 1
i=0#这里的batch_size是要每张增广的批次,所以生成图片的最终数量是batch_size*image_num
for src_batch in image_datagen.flow(img_src, batch_size=2,save_to_dir='./data/train_src/', save_format='tif', save_prefix='all',seed=seed):
i+=1
if i>=image_num:
break;
j=0
for label_batch in mask_datagen.flow(img_label,batch_size=2,save_to_dir='./data/train_label/',save_format='tif',save_prefix='all', seed=seed):
j+=1
if j>=image_num:
break;
if __name__=='__main__':
gen_dataset()
结果:
 裁剪的图像 裁剪的图像 | 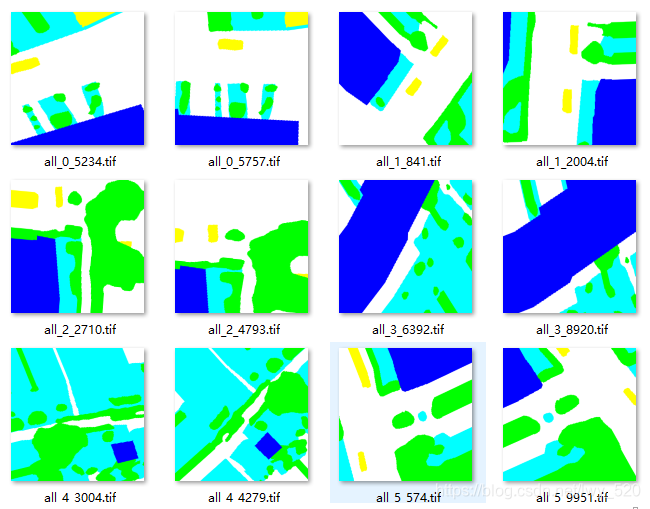 对应的Mask 对应的Mask |
|---|
可以看到生成的图像和标签名称都一样,但是用方法二的时候,增广出来的图像可能没有原图像。而且个人跑代码的时候,方法二给出警告。另外我有另一篇博客用的是另一种方法进行的数据增广,附上链接:https://blog.csdn.net/lwy_520/article/details/83794238














 1786
1786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









