







简单爬虫架构
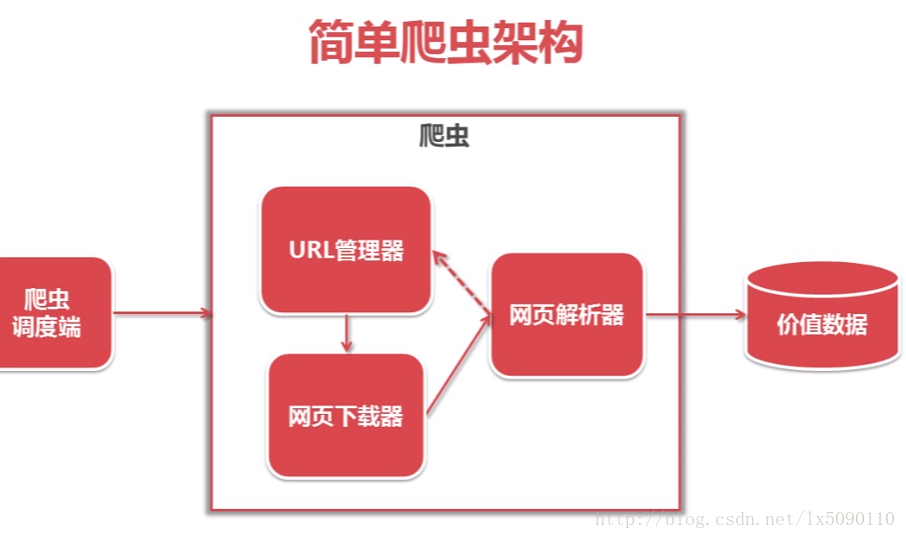
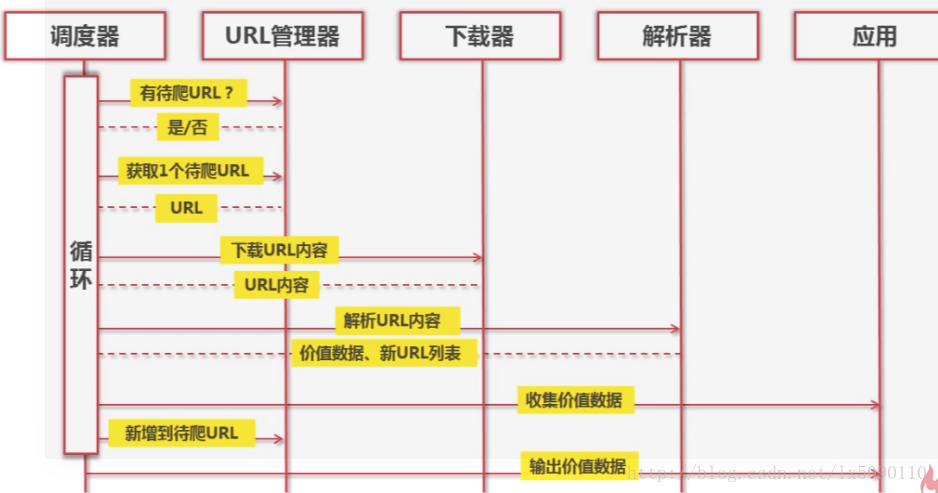
URL 管理器:管理待爬取URL集合和已抓取URL集合(防止重复抓取、防止循环抓取)
需要支持:1.添加新URL到待爬取集合中 2. 判断待添加URL是否在容器中 3.从url管理器中获取待爬取URL
4.判断URL管理器中是否还有待爬取的URL 5.将URL从待爬取集合中移动到已爬取集合
实现方式:1.将待爬取的URL集合和已爬取的URL集合存储在内存中 使用set()[为了去重]
2.关系数据库MySQL: 用一个表存储两个集合(待,已) urls(url, is_crawled)
3.缓存数据库redis :set
网页下载器:从互联网将一个url对应的互联网以HTML形式存储为一个本地文件或本地字符串
1.python对应下载器:urllib2,requests
urllib2:response = urllib2.urlopen("url")
print response.getcode()#获取状态码,如果是200则是成功
cont = response.read()#读取内容
2.urllib2 下载网页的方法:添加data 、http header
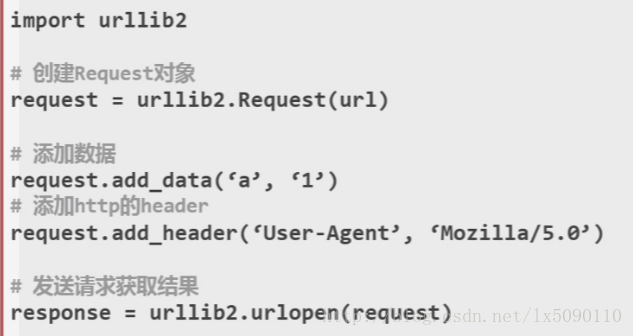
3.添加特殊情景的处理器
HTTPCookieProcessor (用户登录) ProxyHandler(需要代理) HTTPSHandler(加密访问) HTTPRedirectHandler(自动跳转关系)














 5421
5421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









