







(1)实验环境:最新的vmware workstation10.0.0 和 ubuntu-12.04.3服务器版本,hadoop 1.1.2,java1.7
在win7下虚拟三个 乌班图系统,作为一个主节点两个从节点。
分别去官网下载这四个的安装包
(2) vmware10.0.0安装:
按提示安装vmware10.0.0 并破解,安装完成后显示
(2)创建三个乌班图虚拟机
点击创建新的虚拟机的按钮,选择典型的配置模式 ,选择系统镜像,和系统文件存储目录,以及磁盘分配空间,我的将分别放到
d盘linux目录下的 ubutu01 ubutu02 ubutu03 设置内存都为1G
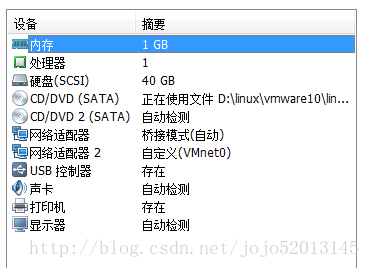
将新建的系统克隆出 ubutu02 ubutu03 除了名字配置相同
修改机器名分别为 ubutu01 ubutu02 ubutu03
(2)组件局域网
家里的机器用的是路由器上网,所以适配器选择桥连模式,并复制物理网络连接状态。三个虚拟机等同于独立主机通过路由上网 (主机是其他上网方式的可选择NAT模式(nte8),通过主机实现连接外网。 需要调节虚拟机跟主机同一个网段,网关设为主机IP)
都是启动时连接
局域网组建完毕,能相互ping通,也能访问外网
(3)vmware tools 安装
为了能方便的在主机和三个虚拟机之间共享数据,将4个系统都共享一个文件夹,
安装vmware tools 按提示操作即可
(3)JAVA和GCC的安装(GCC可以不用装 我因为安装vmware tools 需要 才装的 ,其实用xshell之类的软件更简单)
因为hadoop允许需要jvm环境和gcc环境故需要安装
去oracle官网下载java1.7的linux版本
再三台机器上分别解压安装,并配置环境变量
export JAVA_HOME=/opt/jdk1.7.0_15
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
执行java -version显示版本即为安装成功
执行命令 sudoapt-getinstallbuild-essential安装 gcc
(3)hadoop的安装和配置
将hadoop解压安装在工作目录下
进入hadoop下的conf目录修改hadoop的配置
hadoop-env.sh配置 JAVA_HOME 为java目录
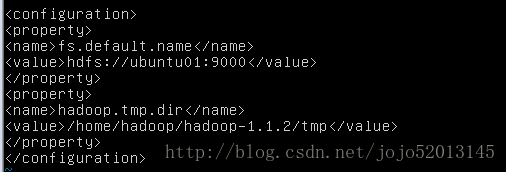
core-site.xml : namenode和临时文件目录的配置


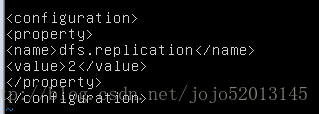
hdfs-site.xml 配置hdfs的从节点复制因子
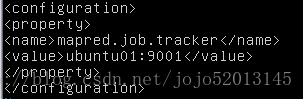
mapred-site.xml 配置job tracker
masters 配置主服务器
slaves 配置从服务器
将hadoop装个目录分别用scp拷贝到 ubuntu02和ubuntu03
三台虚拟机分别修改 /etc/hosts:
192.168.10.104 ubuntn01
192.168.10.105 ubuntn02
192.168.10.106 ubuntn03
(4)配置无需密码的ssh
三台机器分别执行 ssh-keygen -t rsa 在工作目录下的~/.ssh/下会生产秘钥文件
将三台机器的
id_rsa.pub都拷贝到ubuntu01 中分别为 id_rsa.pub 2.pub,3.pub 其中2和3来自另外两台机器的id_rsa.pub拷贝
对三个文件分别执 cat 2.pub >> authorized_keys , cat 3.pub >> authorized_keys , cat id_rsa .pub >> authorized_keys
将秘钥的内容都汇总到 authorized_keys 文件
然后将authorized_keys 文件拷贝到 ubuntu02,ubuntu03的 ~/.ssh/下
完成后三台机器间的ssh访问就不需要密码
(5)hadoop命令启动
格式化名称节点
bin/hadoop namenode -format
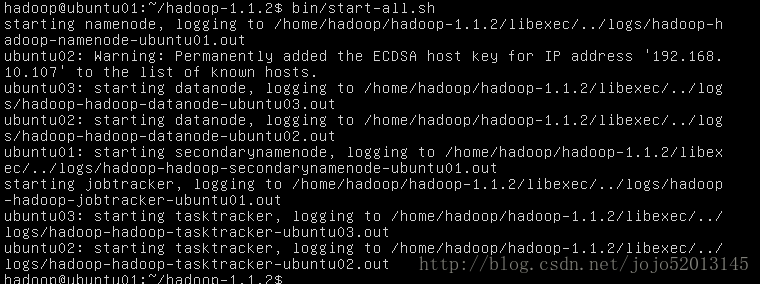
启动集群 bin/start-all.sh
假如启动失败 看进程 /opt/jdk****/bin/jps
显示多个进程 需要杀掉后再重启 kill -9 + 进程号 jps进程不要杀
主从节点都要杀干净进程
也可以 bin/stop-all.sh关闭
怎么确定启动成功:
不报错同时 主从的进程(/opt/jdk****/bin/jps)都正常启动
(6)运行hadoop自带事例 wordcount
本地创建文件
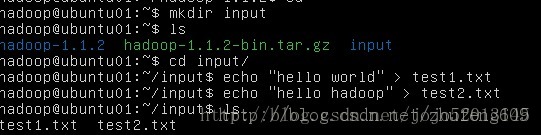
将本地文件拷贝到hdfs hadfs里 .代表当前用户的缺省目录 /user/hadoop/ 其中hadoop是用户名(最好起个别的名字 容易混淆)
hadoop 操作hdfs的命令(老版本可能是 bin/hadoop dfs )
bin/hadoop fs -ls ./in
bin/hadoop fs -put
bin/hadoop fs -cat ./in/test1.txt
bin/hadoop fs -rmr ./in/test1.txt
执行示例程序wordcount in是输入目录 out是输出目录


查看结果
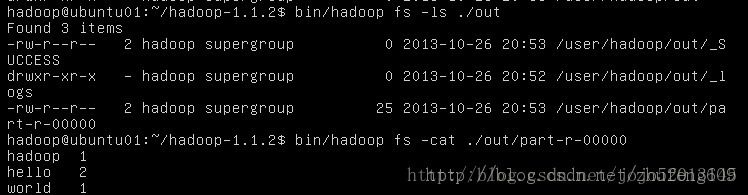















 1490
1490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









