






先上图
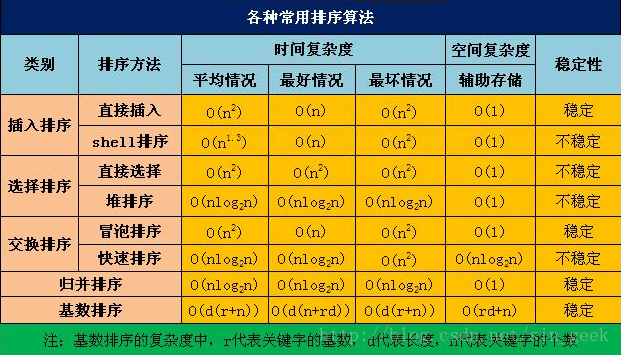
1 插入排序(InsertSort)
插入排序通过把序列中的值插入一个已经排序好的序列中,直到该序列的结束。插入排序是对冒泡排序的改进。平均情况下,冒泡排序的比较次数近似为插入排序的2倍,移动次数与插入排序相同,可以说插入排序比冒泡排序快2倍。
插入排序一般不用在数据大于1000的场合,或者重复排序超过200数据项的序列。
2 Shell排序(ShellSort)
Shell排序通过将数据分成不同的组,先对每一组进行排序,然后再对所有的元素进行一次插入排序,以减少数据交换和移动的次数。平均效率是O(nlogn)。也有说时间复杂度为O(n1.25)~O(1.6n1.25),查了下貌似没有具体解决。只有那么几种说法。一般说来,Shell排序比冒泡排序快5倍,比插入排序大致快2倍。它适合于数据量在5000以下并且速度并不是特别重要的场合。它对于数据量较小的数列重复排序是非常好的。
3 选择排序(SelectSort)
选择排序是一种简单的交换排序算法,效率是 O(n2)。在实际应用中处于和冒泡排序基本相同的地位。冒泡排序与选择排序的比较次数是一样的,而移动次数比选择排序多出n次。
4 堆排序(HeapSort)
堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。堆排序适合于数据量非常大的场合(百万数据)。堆排序不需要大量的递归或者多维的暂存数组。这对于数据量非常巨大的序列是合适的。比如超过数百万条记录,因为快速排序,归并排序都使用递归来设计算法,在数据量非常大的时候,可能会发生堆栈溢出错误。
5 冒泡排序(BubbleSort)
又译为泡沫排序或气泡排序,冒泡排序是最慢的排序算法。在实际运用中它是效率最低的算法。它通过一趟又一趟地比较数组中的每一个元素,使较大的数据下沉,较小的数据上升。
6 快速排序(QuickSort)
在平均状况下,排序 n 个项目要Ο(n log n)次比较。在最坏状况下则需要Ο(n2)次比较,但这种状况并不常见。事实上,快速排序通常明显比其他Ο(n log n) 算法更快,因为它的内部循环可以在大部分的架构上很有效率地被实现出来。但对于内存非常有限的机器来说,它不是一个好的选择。
7 归并排序(MergeSort)
是建立在归并操作上的一种有效的排序算法。该算法是采用分治法的一个非常典型的应用。归并排序先分解要排序的序列,从1分成2,2分成4,依次分解,当分解到只有1个一组的时候,就可以排序这些分组,然后依次合并回原来的序列中,这样就可以排序所有数据。
合并排序比堆排序稍微快一点,但是需要比堆排序多一倍的内存空间,因为它需要一个额外的数组。
8 基数排序(RadixSort)
基数排序和通常的排序算法并不走同样的路线。基数排序的时间复杂度是 O(k•n),其中n是排序元素个数,k是数字位数。注意这不是说这个时间复杂度一定优于O(n•log(n)),因为k的大小一般会受到 n 的影响。 以排序n个不同整数来举例,假定这些整数以B为底,这样每位数都有B个不同的数字,k就一定不小于logB(n)。由于有B个不同的数字,所以就需要B个不同的桶,在每一轮比较的时候都需要平均n•log2(B)次比较来把整数放到合适的桶中去,所以就有:
• k 大于或等于 logB(n)
• 每一轮(平均)需要 n•log2(B) 次比较
所以,基数排序的平均时间T就是:
T ≥logB(n)•n•log2(B) = log2(n)•logB(2)•n•log2(B)= log2(n)•n•logB(2)•log2(B) = n•log2(n)
所以和比较排序相似,基数排序需要的比较次数:T ≥ n•log2(n)。故其时间复杂度为 Ω(n•log2(n))= Ω(n•log n) 。















 7579
7579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









