







一、定义
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即,对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即,对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。
二、实现
MODI.Document doc = new MODI.Document();
doc.Create(fileName);
MODI.Image image = doc.Images[0];
image.OCR(MODI.MiLANGUAGES.miLANG_CHINESE_SIMPLIFIED, true, true);
MODI.Layout layout = image.Layout;
doc.Close(false);
return layout.Text;
三、效果
左边是图片,右边是从图片中读取的文字。
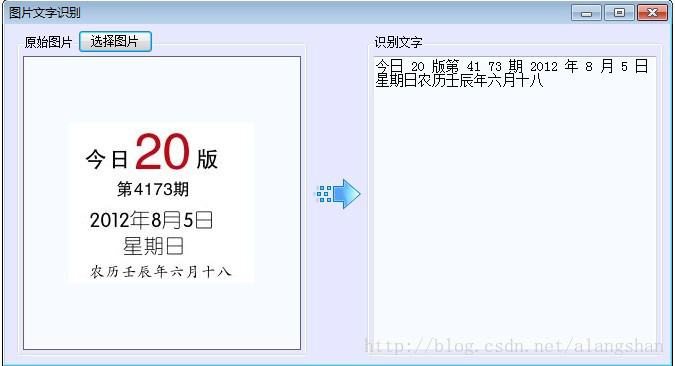

四、备注
MODI(Microsoft Office Document Imaging)















 359
359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









