









该论文提出了一种能感知图像内容进而提高表情识别能力的网络。目前主流的表情识别基本不考虑图像背景/context,而是把人脸crop出来单独进行表情的识别。本文认为,图像背景信息可以帮助对表情的判断。
本文提出的网络称为Context-Aware Emotion Recogntion Networks(CAER-Net),主要功能就是同时参考背景信息和人脸信息,实现更准确的表情识别。CAER-Net结构如下图所示:
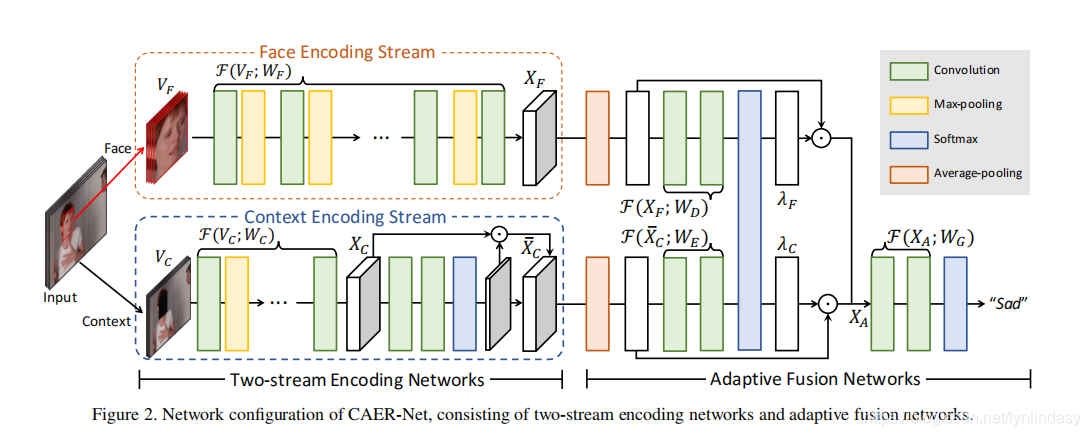
整个网络由两部分组成,一个是前面的双流编码网络/Two-stream Encoding Networks,一个是后面的自适应融合网络/Adative Fusion Networks。前者从一张图像分别编码,上方从脸部区域提取信息,下方从背景中提取信息。后者是将两个信息进行融合从而实现表情分类。
先分析face encoding stream:没有特殊的结构,卷积包括了后面的BN和Relu,卷积核3*3,卷积后进行最大池化降低分辨率,最后经过均匀池化/average pooling。
再分析context encoding stream:包括两部分context encoding model和attention inference model,从上图中就能推断出来两者的顺序:蓝色框表示softmax是attention model中最常见的操作,因此是先进行context encoding再进行attention inference。文中介绍,是提取的context features,也是attention model的输入。紧接着
的局势卷积和softmax,然后得到了一个灰色框其实就是attention mask,该mask和
相同大小,因此和
进行element-wise multiplication。这个过程就是使用attention对原本的context features进行提升/boost,使得context中有利于表情识别的信息得到重视。context encoding中的网络结构和face encoding相同,5层卷积和四个最大池化,这保证了双流的输出features是相同大小的。同样,context encoding stream也会进行平均池化。
attention的效果如下图所示:

图(b)是对单张图片,图(c)是对多帧图像,后者还利用了时间特征,因此attention的结果更细致。
得到了两部分信息后,考虑的就是融合。Adaptive fusion networks中再次利用了attention:因为两种feature maps直接concatenate效果略差,使用attention为他们分配了权重,这就是所谓的adaptive。一些图像的权重分配如下所示:

融合后的features进行最后的分类。
文中比较有趣的实验是是否在对context encoding时遮挡face region,实验结果如下:前两列并没有遮挡,后两列遮挡了。说明不遮挡情况下attention的区域就是面部,遮挡后它才能focus on其他有助于表情识别的信息,比如手部的动作等。

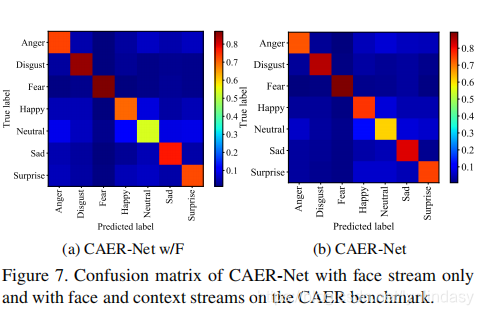
利用confusion matrix量化结果,可以看到happy和neutral是提高很明显的,如下图所示。neutral可以理解为本身面部特征没有非常明显,借助背景后更容易判断。
这篇文章整体比较简单,其实没想到context information对表情识别影响会很大,因为面部特征的提取和解耦合还有待改进。所以这篇文章提供了新思路,可以实验看看效果。














 2994
2994











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









