







决策树的主要优势在于数据形式非常容易理解
决策树的一个重要任务是为了数据中蕴含的知识信息,因此决策树可以使用不熟悉的数据集合,并从中提取出一系列规则,在这些机器根据数据集创建规则时,就是机器学习的过程。
from math import log
import operator
import M_0302_DTPlot as DTP
#决策树:分类基于使信息处于最大信息熵的状态。对一个数据集来说,找到每一个特征的所有值,计算不同值的划分带来的信息熵变化,对所有的特征都这样计算,最终找到使信息变化最大的特征,一次划分数据集。因为一个特征可能有多个不同的值,所以基于ID3的决策树划分一个节点下可能有多个子节点。
#数据结构:(数据特征,类别标签)
#在我们创建决策树时,需要人为传递特征名字以更好地展示信息。类别标签最终将位于叶子节点,特征名字位于树节点
3.1.决策树的构造
-
优点:计算复杂度不高,输出结果易于理解,对中间值的确实不敏感,可以处理不相关特征数据
缺点:可能会产生过度匹配问题
使用数据类型:数值型和标称型 -
在构造决策树时,我们需要解决的第一个问题就是:
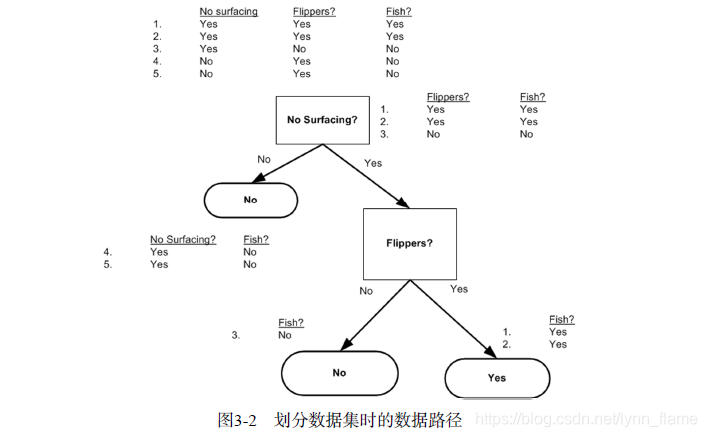
当前数据集上哪个特征在划分数据分类时起决定性作用。为了找到决定性的特征,划分出最好的结果,我们必须评估每个特征。完成测试之后,原始数据集就被划分为几个数据子集。这些数据子集会分布在第一个决策点的所有分支上。如果莫格分支下的数据属于同一类型,则无需进一步对数据集进行分割。如果数据子集内的数据不属于同一类型,则需要重复划分数据子集的过程。如何划分数据子集的算法和划分原始数据集的方法相同,直到所有具有相同类型的数据均在一个数据子集内。 -
创建分支的伪代码函数createBranch()如下所示
检测数据集中的每个子项是否属于同一分类
if so return 类标签:
Else
寻找划分数据集的最好特征
划分数据集
创建分支节点
for 每个划分的子集
调用函数createBranch并增加返回结果到分支节点中
return 分支节点 -
决策树的一般流程
1)收集数据
2)准备数据:树构造算法只适用于标称型数据,因此数值型数据必须离散化
3)分析数据:可以使用任何方法,构造树完成之后,我们应该检查图形是否符合预期
4)训练算法:构造树的数据结构
5)测试算法:使用经验树计算错误率
6)使用算法:此步骤可以适用于任何监督学习算法,而使用决策树可以更好地理解数据的内在含义 -
划分数据
如果依据某个属性划分数据将会产生4个可能的值,我们将把数据分成四块,并创建四个不同的分支。将使用ID3算法划分数据集,该算法处理如何划分数据集,何时停止划分数据集。 -
每次划分数据集时我们只选择一个特征属性,如果训练集中存在20个特征,那我们选取哪个特征呢?
3.1.1 信息增益
**划分数据集的大原则是:将无序的数据变得更加有序**
-
在划分数据集之前之后信息发生的变化称为信息增益。我们可以计算每个特征值划分数据集获得的信息增益,获得信息增益最高的特征就是最好的选择。
-
集合信息的度量方式称为香农熵(information gain)或简称为熵(entropy)
熵定义为信息的期望值。
如果待分类的事物可能划分在多个分类之中,则符号Xi的信息定义为l(Xi) = - log2[p(Xi)],其中p(Xi)是选择该分类的概率
为了计算熵,我们需要所有类别所有可能值包含的信息期望值,通过下面的公式得到: H = -Σp(Xi)log2[p(Xi)] i=[1,n],n为分类的数目
熵越高,则混合的数据也越多
得到熵之后,我们就可以按照获取最大信息增益的方法划分数据集 -
另一个度量集合无序程度的方法是基尼不纯度(Gini
impurity),简单地说就是从一个数据集中随机选取子项,度量其被错误分类到其他分组里的概率
def calcShannonEnt(dataset):
"""计算数据集的香农熵
返回数据集的熵
"""
num_entries = len(dataset)
label_counts = {} #为所有可能分类创建字典
for feat_vec in dataset:
#标签在数据的最后一列
current_label = feat_vec[-1]
if current_label not in label_counts.keys():
label_counts[current_label] = 0
label_counts[current_label] += 1 #具有相同Label的数据记录数
shannon_ent = 0.0
for key in label_counts:
prob = float(label_counts[key])/num_entries #p(Xi)选择该分类的概率
shannon_ent -= prob*log(prob,2)
return shannon_ent
def createDataset():
"""测试函数"""
dataset = [
[1,1,'yes'],
[1,1,'maybe'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no'],
]
labels = ['no surfacing','flippers']
return dataset,labels
def splitDataset(dataset:list,axis,value):
"""按照给定特征划分数据集\n
dataset:待划分的数据集\n
axis:划分数据集的特征\n
value:需要返回的特征的值\n
return:返回一个列表,不包含axis列,包含了标签列ie.no lense"""
ret_dataset = [] #因为该函数在同一数据集上被调用多次,为了不修改原始数据集,创建一个新的列表对象
for feat_vec in dataset:
if feat_vec[axis] == value:
reduced_feat_vec = feat_vec[:axis]
# if len(reduced_feat_vec) == 0:
# print("当前列表为空")
reduced_feat_vec.extend(feat_vec[axis+1:])
ret_dataset.append(reduced_feat_vec)
return ret_dataset
3.1.2 划分数据集-chooseBestFeatureToSplit(dataset:list)
对每个特征划分数据集的结果计算一次信息熵,然后判断按照哪个特征划分数据集集是最好的划分方式
def chooseBestFeatureToSplit(dataset:list):
"""遍历整个数据集,循环计算香农熵和splitDataset(),找到最好的特征划分方式\n
dataset:是由列表元素组成的列表,所有的列表元素具有相同的数据长度,数据的最后一列或每个实例的最后一个元素是当前实例的类别标签[val,val,val,...,label]
划分数据集的大原则是:将无序的数据变得更加有序
return best_feat:返回划分最好的特征
"""
num_features = len(dataset[0]) - 1 #当前数据集包含多少特征属性
base_entropy = calcShannonEnt(dataset) #整个数据集的原始香农熵,用于与划分后的数据集计算的熵值进行比较
best_info_gain = 0.0
best_feature = -1
#遍历数据集中的所有特征x1,x2,x3,...
for i in range(num_features):
#创建唯一的分类标签列表
#对于数据young myope no reduced no lenses,去掉标签,i=0,1,2,3
feat_list = [example[i] for example in dataset] #列表推导式,将数据集的第i个特征放到列表中
unique_vals = set(feat_list) #i.e.age特征(presbyopic,pre,young)
new_entropy = 0.0
#计算以每种特征划分方式的信息熵
for value in unique_vals: #遍历当前特征中的所有唯一属性值,对每个特征值划分一次数据集,然后计算数据集的新熵值,并对所有唯一特征值得到的熵求和
sub_dataset = splitDataset(dataset,i,value)
prob = len(sub_dataset)/float(len(dataset)) #选择该分类的概率
new_entropy += prob*calcShannonEnt(sub_dataset)
info_gain = base_entropy - new_entropy
#计算最好的信息增益-比较所有特征中的信息增益(变化越大越好)
if info_gain>best_info_gain:
best_info_gain = info_gain
best_feature = i
return best_feature
3.1.3 递归构建决策树
数据的特征:lenses_labels = ['age','prescript','astigmatic','tearRate']
数据:young('age') myope('prescript') no('astigmatic') reduced('tearRate') no lenses(标签)
-
基于最好的属性值划分数据集,由于特征值可能多于两个,因此可能存在大于两个分支的数据集划分。第一次划分后,数据将被向下传递到树分支的下一个节点。在这个节点上,我们可以再次划分数据。使用递归
-
递归结束的条件是:程序遍历完所有划分数据集的属性,或者每个分支下的所有实例都具有相同的分类。如果所有实例具有相同的分类,则得到一个叶子节点或者终止块。任何到达叶子节点的数据必然属于叶子节点的分类。
-
我们可以设置算法可以划分的最大分组数目。后续还会介绍其他决策树算法,如C4.5和CART,这些算法在运行时并不总是在每次划分分组时都会消耗特征。
-
如果数据集已经处理了所有属性,但是类标签依然不时唯一的,此时我们需要决定如何定义该叶子节点,在这种情况下,我们通常采用多数表决的方法决定改叶子节点的分类。majorityCnt()
def majorityCnt(classList):
"""如果数据集已经处理了所有属性,但是类标签依然不是唯一的,在这种情况下,我们通常采用多数表决的方法决定改叶子节点的分类"""
class_count = {} #存储每个类标签出现的频率
for vote in classList:
if vote not in class_count.keys():
class_count[vote] = 0
class_count[vote] +=1
sorted_class_count = sorted(
class_count.items(),
key = operator.itemgetter(1), #operator操作键值排序字典,并返回出现次数最多的分类名称
reverse = True
) #传入一个迭代器对象,返回一个包含所有item的列表,并降序排列reverse = True
return sorted_class_count[0][0]
def createTree(dataset,featName):
"""创建树
dataset:数据集
labels:特征的名字
"""
class_list = [example[-1] for example in dataset] #取出类别标签
#递归出口1:类别完全相同则停止继续划分,并将标签作为叶子节点
if class_list.count(class_list[0]) == len(class_list):
return class_list[0]
#递归出口2:使用完了所有特征,仍然不能将数据集划分成仅包含唯一类别的分组。遍历完所有特征时返回出现次数最多的类别。
if len(dataset[0]) == 1: #dataset[0]:splitDataset()函数返回的是feat_vec[axis+1:],到最后返回的是一个只包含一个数据的列表实例
return majorityCnt(class_list)
best_feature = chooseBestFeatureToSplit(dataset)
best_featName = featName[best_feature] #这里的Labels存储的是特征的值而不是意义上的标签
myTree = {best_featName:{}} #存储树的所有信息-嵌套字典
del(featName[best_feature])
feat_values = [example[best_feature] for example in dataset] #得到列表的所有属性值
unique_vals = set(feat_values)
#遍历当前选择特征包含的所有属性值,在每个数据集划分上递归调用函数createTree(),得到的返回值将被插入到字典变量myTree中,因此函数终止执行时,字典中将会嵌套很多代表叶子接待你信息的字典数据
for value in unique_vals:
sub_labels = featName[:] #复制类标签,为保证每次调用createTree()时不改变原始列表的内容
myTree[best_feature_label][value] = createTree(splitDataset(dataset,best_feature,value),sub_labels)
return myTree
if __name__ == '__main__':
mydata,labels = createDataset()
Tree = createTree(mydata,labels)
#DTP.plotDT.createPlot(Tree)#Exception has occurred: AttributeError:'function' object has no attribute 'createPlot'
#DTP.plotDT(Tree)
3.2 在Python中使用Matplotlib注解绘制树形图
3.2.1 matplotlib注解
注解工具annotations
3.2.2 构造注解树
如何放置所有的树节点却是个问题。我们必须知道有多少个叶节点,以便可以正确确定x轴的长度;我们还需要知道树有多少层,以便可以确定y轴的高度
import matplotlib.pyplot as plt
def attempt_test():
#使用文本注解绘制树节点\n
decision_node = dict(boxstyle = 'sawtooth',fc = '0.8')
leaf_node = dict(boxstyle = 'round4',fc = '0.8')
def plotNode():
pass
def createPlot():
"""首先创建一个新图形并清空绘图区,然后在绘图区绘制两个代表不同类型的树节点"""
fig = plt.figure(1,facecolor='white')
fig.clf() #清除所有轴
createPlot.ax1 = plt.subplot(111,frameon=False) #定义绘图区
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] #matplotlib默认不支持中文,配置字体
plotNode('决策节点',(0.5,0.1),(0.1,0.5),decision_node)
plotNode('叶节点',(0.8,0.1),(0.3,0.8),leaf_node)
plt.show()
createPlot()
def plotDT(Tree):
"""使用文本注解绘制树节点\n
createPlot()
"""
#定义文本框和箭头格式
decision_node = dict(boxstyle = 'sawtooth',fc = '0.8')
leaf_node = dict(boxstyle = 'round4',fc = '0.8')
arrow_args = dict(arrowstyle='<-')
def plotNode(nodeTxt,centerPt,parentPt,nodeType):
"""绘制带箭头的注解"""
createPlot.ax1.annotate(
nodeTxt,xy=parentPt,xycoords='axes fraction',
xytext=centerPt,textcoords='axes fraction',
va='center',ha='center',bbox=nodeType,arrowprops=arrow_args,
)
def plotMidText(cntrPt,parentPt,txtString):
"""在父子节点间填充文本信息,并计算父子节点各自的中间位置"""
xMid = (parentPt[0] - cntrPt[0])/2.0 + cntrPt[0]
yMid = (parentPt[1] - cntrPt[1])/2.0 + cntrPt[1]
createPlot.ax1.text(xMid,yMid,txtString)
def plotTree(myTree,parentPt,nodeTxt):
"""绘制树形图\nplotTree.totalW,plotTree.totalD两个全局变量计算树节点的摆放位置,这样可以把树绘制在水平方向和垂直方向的中心位置\n树的宽度用于计算放置判断节点的位置,主要的计算原则是将它放在所有叶子节点的中间,而不仅仅是它子节点的中间\nplotTree.xOff,plotTree..yOff跟踪已经绘制的节点位置,以及防止下一个节点的恰当位置"""
num_leafs = getNumLeafs(myTree)
depth = getTreeDepth(myTree)
first_str = list(myTree.keys())[0]
cntrPt = (plotTree.xOff + (1.0 +float(num_leafs))/2.0/plotTree.totalW,plotTree.yOff)
plotMidText(cntrPt,parentPt,nodeTxt)
plotNode(first_str,cntrPt,parentPt,decision_node)
second_dict = myTree[first_str]
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD #按比例减少全局变量plotTree.yOff,并标注此处将要绘制子节点,自顶向下
for key in second_dict.keys():
#如果不是叶子节点,则递归调用
if type(second_dict[key]).__name__ == "dict":
plotTree(second_dict[key],cntrPt,str(key))
#如果是叶子节点,则绘制
else:
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(second_dict[key],(plotTree.xOff,plotTree.yOff),cntrPt,leaf_node)
plotMidText((plotTree.xOff,plotTree.yOff),cntrPt,str(key))
#绘制了所有子节点之后,增加全局变量Y的偏移
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
def createPlot(inTree):
"""首先创建一个新图形并清空绘图区,计算树形图的全局尺寸"""
fig = plt.figure(1,facecolor='white')
fig.clf() #清除所有轴
axprops = dict(xticks=[],yticks=[])
createPlot.ax1 = plt.subplot(111,frameon=False,**axprops) #定义绘图区
plotTree.totalW = float(getNumLeafs(inTree)) #函数名.变量名 将变量声明为全局变量
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5/plotTree.totalW
plotTree.yOff = 1.0
plotTree(inTree,(0.5,1.0),'')
plt.show()
createPlot(Tree)
def getNumLeafs(myTree):
"""获取叶节点的数目"""
num_leaves = 0
first_str = list(myTree.keys())[0] #dict_keys类型不能使用索引取值,需list()转换
second_dict = myTree[first_str]
for key in second_dict.keys():
#测试节点的数据类型是否为字典,第一个关键字是划分数据集的类别标签
if type(second_dict[key]).__name__=='dict':
num_leaves += getNumLeafs(second_dict[key])
else:
num_leaves += 1
return num_leaves
def getTreeDepth(myTree):
"""获取树的层数\n该函数的终止条件是叶子节点,一旦到达叶子节点,则从递归调用中返回,并将计算树深度的变量加1"""
max_depth = 0
first_str = list(myTree.keys())[0]
second_dict = myTree[first_str]
for key in second_dict.keys():
if type(second_dict[key]).__name__=='dict':
this_depth = 1+getTreeDepth(second_dict[key])
else:
this_depth = 1
if this_depth > max_depth:
max_depth = this_depth
return max_depth
3.3 测试和存储分类器
3.3.1 测试算法:使用决策树执行分类
在执行数据分类时,需要决策树以及用于构造树的标签向量。然后,程序比较测试数据与决策树上的数值,递归执行该过程直到进入叶子节点;最后将测试数据定义叶子
3.3.2 决策树的存储
使用模块pickle序列化对象,序列化对象可以在磁盘上保存对象,并在需要的时候读取出来。任何对象都可以执行序列化操作,字典对象也不例外
3.4 使用决策树预测隐形眼镜类型
1.收集数据
2.准备数据:解析Tab键分割的数据行
3.分析数据:快速检查数据,确保正确地解析数据内容,使用createPlot()函数绘制最终的树形图
4.训练算法:createTree()
5.测试算法:编写测试函数验证决策树可以正确分类给定的数据实例
6.使用算法:存储树的数据结构,以便下次使用时无需重新构造树
7.匹配选项太多的情况称为过度匹配(overfitting)。为了减少过度匹配问题,我们可以裁剪决策树,去掉一些不必要的叶子节点。如果叶子节点只能增加少许信息,则可以删除该节点,将它并入到其他叶子节点中。
后续学习CART算法,本章使用ID3.ID3算法无法直接处理数值型数据,尽管我们可以通过量化的方法将数值型数据转化为标称型数值,但太多的特征划分仍存在问题。
import M_0301_DT as DTC
import pickle
import M_0302_DTPlot as DTP
def classify(inputTree,featLabels,testVec):
"""使用决策树的分类函数"""
first_str = list(inputTree.keys())[0]
second_dict = inputTree[first_str]
feat_index = featLabels.index(first_str) #使用Index方法查找当前列表中第一个匹配first_sr变量的元素,并返回索引
#遍历整棵树,比较testVec变量中的值与树节点的值,如果到达叶子节点,则返回当前节点的分类标签
for key in second_dict.keys():
if testVec[feat_index] == key:
if type(second_dict[key]).__name__ == 'dict':
class_label = classify(second_dict[key],featLabels,testVec)
else:
class_label = second_dict[key]
return class_label
def storeTree(inputTree,filename):
"""使用pickle存储决策树"""
fw = open(filename,'wb')
pickle.dump(inputTree,fw)
fw.close()
def grabTree(filename):
"""取决策树"""
fr = open(filename,'rb')
return pickle.load(fr)
if __name__ == '__main__':
fr = open('./M_0304_DT_lenses.txt')
lenses = [inst.strip().split('\t') for inst in fr.readlines()]
lenses_features = ['age','prescript','astigmatic','tearRate']
lenses_tree = DTC.createTree(lenses,lenses_features)
DTP.plotDT(lenses_tree)














 314
314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









