







linux源码:http://ftp.sjtu.edu.cn/sites/ftp.kernel.org/pub/linux/kernel/v2.6/
转:http://oldblog.donghao.org/2009/08/linuxiapolliepollaueouaeaeeio.html
转:http://blog.chinaunix.net/uid-27024249-id-3988524.html
fs/eventpoll.c中
1、epoll_create函数:
SYSCALL_DEFINE1(epoll_create1, int, flags)
{
int error;
struct eventpoll *ep = NULL;
/* Check the EPOLL_* constant for consistency. */
BUILD_BUG_ON(EPOLL_CLOEXEC != O_CLOEXEC);
//O_CLOEXEC 就等于EPOLL_CLOEXEC (打开的文件描述符在执行exec调用新程序中关闭,且为原子操作)
if (flags & ~EPOLL_CLOEXEC)
return -EINVAL;
/*
* Create the internal data structure ("struct eventpoll").
* 创建内核数据结构体 struct eventpoll
*/
error = ep_alloc(&ep);
if (error < 0)
return error;
/*
* Creates all the items needed to setup an eventpoll file. That is,
* a file structure and a free file descriptor.
* 创建的所有iteam(fd,file) 都需要安装一个eventpool文件
File callbacks that implement the eventpoll file behaviour
static const struct file_operations eventpoll_fops = {
.release = ep_eventpoll_release,
.poll = ep_eventpoll_poll
};
创建一个fd,和一个file,将eventpoll_fops绑在file->f_op上,将ep绑在file->private_data上
*/
error = anon_inode_getfd("[eventpoll]", &eventpoll_fops, ep,
flags & O_CLOEXEC);
if (error < 0)
ep_free(ep);
return error;
}anon_inode_getfd //找到int anon_inode_getfd(const char *name, const struct file_operations *fops,
void *priv, int flags)
{
int error, fd;
struct file *file;
//获取一个未使用的fd
error = get_unused_fd_flags(flags);
if (error < 0)
return error;
fd = error;
// 将ep做为参数priv设置到file的结构中 file->private_data = priv;
// 将fops作为新建文件的file -> f_op 注意是fs.h中的struct file
file = anon_inode_getfile(name, fops, priv, flags);
if (IS_ERR(file)) {
error = PTR_ERR(file);
goto err_put_unused_fd;
}
//将file和fd关联起来,fdt->fd[fd]=file
fd_install(fd, file);
return fd;
err_put_unused_fd:
put_unused_fd(fd);
return error;
}//创建file并且绑定一些数据priv-->eventpollstruct file *anon_inode_getfile(const char *name,
const struct file_operations *fops,
void *priv, int flags)
{
struct qstr this;
struct dentry *dentry;
struct file *file;
int error;
if (IS_ERR(anon_inode_inode))
return ERR_PTR(-ENODEV);
if (fops->owner && !try_module_get(fops->owner))
return ERR_PTR(-ENOENT);
/*
* Link the inode to a directory entry by creating a unique name
* using the inode sequence number.
*/
error = -ENOMEM;
this.name = name;
this.len = strlen(name);
this.hash = 0;
dentry = d_alloc(anon_inode_mnt->mnt_sb->s_root, &this);
if (!dentry)
goto err_module;
/*
* We know the anon_inode inode count is always greater than zero,
* so we can avoid doing an igrab() and we can use an open-coded
* atomic_inc().
*/
atomic_inc(&anon_inode_inode->i_count);
dentry->d_op = &anon_inodefs_dentry_operations;
/* Do not publish this dentry inside the global dentry hash table */
dentry->d_flags &= ~DCACHE_UNHASHED;
d_instantiate(dentry, anon_inode_inode);
error = -ENFILE;
file = alloc_file(anon_inode_mnt, dentry,
FMODE_READ | FMODE_WRITE, fops);
if (!file)
goto err_dput;
file->f_mapping = anon_inode_inode->i_mapping;
file->f_pos = 0;
file->f_flags = O_RDWR | (flags & O_NONBLOCK);
file->f_version = 0;
file->private_data = priv;
return file;
err_dput:
dput(dentry);
err_module:
module_put(fops->owner);
return ERR_PTR(error);
}2、插入是红黑树,查找是相当的快
epoll_ctl函数:
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd,
struct epoll_event __user *, event)
{
int error;
struct file *file, *tfile;
struct eventpoll *ep;
struct epitem *epi;
struct epoll_event epds;
error = -EFAULT;
// 如果不是EPOLL_CTL_DEL操作 将用户态的数据event拷贝到内核态的对象epds上
if (ep_op_has_event(op) &&
copy_from_user(&epds, event, sizeof(struct epoll_event)))
goto error_return;
/* Get the "struct file *" for the eventpoll file */
error = -EBADF;
file = fget(epfd); // 还记得关联函数吗? fd_install(newfd, newfile);
if (!file)
goto error_return;
/* Get the "struct file *" for the target file */
tfile = fget(fd);
if (!tfile)
goto error_fput;
/* The target file descriptor must support poll */
// 由accept->tipc_create f_op如果是TCP则是 stream_ops 如果是UDP则是 msg_ops 对应的poll都是系统poll
error = -EPERM;
if (!tfile->f_op || !tfile->f_op->poll)
goto error_tgt_fput;
/*
* We have to check that the file structure underneath the file descriptor
* the user passed to us _is_ an eventpoll file. And also we do not permit
* adding an epoll file descriptor inside itself.
*/
// 防止修改自己,file必须是eventpoll file
/*
static inline int is_file_epoll(struct file *f)
{
return f->f_op == &eventpoll_fops;
}
*/
error = -EINVAL;
if (file == tfile || !is_file_epoll(file))
goto error_tgt_fput;
/*
* At this point it is safe to assume that the "private_data" contains
* our own data structure.
取出eventpool
*/
ep = file->private_data;
mutex_lock(&ep->mtx);
/*
* Try to lookup the file inside our RB tree, Since we grabbed "mtx"
* above, we can be sure to be able to use the item looked up by
* ep_find() till we release the mutex.
*/
epi = ep_find(ep, tfile, fd);
error = -EINVAL;
switch (op) {
case EPOLL_CTL_ADD:
if (!epi) {
epds.events |= POLLERR | POLLHUP;
error = ep_insert(ep, &epds, tfile, fd);
} else
error = -EEXIST; // 如果epi在ep->rbr(红黑树)中了,表示已经存在插入操作失败
break;
case EPOLL_CTL_DEL:
if (epi)
error = ep_remove(ep, epi);
else
error = -ENOENT;
break;
case EPOLL_CTL_MOD:
if (epi) {
epds.events |= POLLERR | POLLHUP;
error = ep_modify(ep, epi, &epds);
} else
error = -ENOENT;
break;
}
mutex_unlock(&ep->mtx);
error_tgt_fput:
fput(tfile);
error_fput:
fput(file);
error_return:
return error;
}
3、
epoll_wait函数:
SYSCALL_DEFINE4(epoll_wait, int, epfd, struct epoll_event __user *, events,
int, maxevents, int, timeout)
{
int error;
struct file *file;
struct eventpoll *ep;
/* The maximum number of event must be greater than zero */
if (maxevents <= 0 || maxevents > EP_MAX_EVENTS)
return -EINVAL;
/* Verify that the area passed by the user is writeable */
if (!access_ok(VERIFY_WRITE, events, maxevents * sizeof(struct epoll_event))) {
error = -EFAULT;
goto error_return;
}
/* Get the "struct file *" for the eventpoll file */
error = -EBADF;
file = fget(epfd);
if (!file)
goto error_return;
/*
* We have to check that the file structure underneath the fd
* the user passed to us _is_ an eventpoll file.
*/
error = -EINVAL;
if (!is_file_epoll(file))
goto error_fput;
/*
* At this point it is safe to assume that the "private_data" contains
* our own data structure.
*/
ep = file->private_data;
/* Time to fish for events ... */
error = ep_poll(ep, events, maxevents, timeout);
error_fput:
fput(file);
error_return:
return error;
}static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, long timeout)
{
int res, eavail;
unsigned long flags;
long jtimeout;
wait_queue_t wait;
/*
* Calculate the timeout by checking for the "infinite" value (-1)
* and the overflow condition. The passed timeout is in milliseconds,
* that why (t * HZ) / 1000.
*/
jtimeout = (timeout < 0 || timeout >= EP_MAX_MSTIMEO) ?
MAX_SCHEDULE_TIMEOUT : (timeout * HZ + 999) / 1000;
retry:
spin_lock_irqsave(&ep->lock, flags);
res = 0;
if (list_empty(&ep->rdllist)) {
/*
* We don't have any available event to return to the caller.
* We need to sleep here, and we will be wake up by
* ep_poll_callback() when events will become available.
*/
init_waitqueue_entry(&wait, current);
wait.flags |= WQ_FLAG_EXCLUSIVE;
__add_wait_queue(&ep->wq, &wait);
for (;;) {
/*
* We don't want to sleep if the ep_poll_callback() sends us
* a wakeup in between. That's why we set the task state
* to TASK_INTERRUPTIBLE before doing the checks.
*/
set_current_state(TASK_INTERRUPTIBLE);
if (!list_empty(&ep->rdllist) || !jtimeout)
break;
if (signal_pending(current)) {
res = -EINTR;
break;
}
spin_unlock_irqrestore(&ep->lock, flags);
jtimeout = schedule_timeout(jtimeout);
spin_lock_irqsave(&ep->lock, flags);
}
__remove_wait_queue(&ep->wq, &wait);
set_current_state(TASK_RUNNING);
}
/* Is it worth to try to dig for events ? */
eavail = !list_empty(&ep->rdllist) || ep->ovflist != EP_UNACTIVE_PTR;
spin_unlock_irqrestore(&ep->lock, flags);
/*
* Try to transfer events to user space. In case we get 0 events and
* there's still timeout left over, we go trying again in search of
* more luck.
*/
if (!res && eavail &&
!(res = ep_send_events(ep, events, maxevents)) && jtimeout)
goto retry;
return res;
}
static int ep_send_events(struct eventpoll *ep,
struct epoll_event __user *events, int maxevents)
{
struct ep_send_events_data esed;
esed.maxevents = maxevents;
esed.events = events;
return ep_scan_ready_list(ep, ep_send_events_proc, &esed);
}static int ep_scan_ready_list(struct eventpoll *ep,
int (*sproc)(struct eventpoll *,
struct list_head *, void *),
void *priv)
{
int error, pwake = 0;
unsigned long flags;
struct epitem *epi, *nepi;
LIST_HEAD(txlist);
/*
* We need to lock this because we could be hit by
* eventpoll_release_file() and epoll_ctl().
*/
mutex_lock(&ep->mtx);
/*
* Steal the ready list, and re-init the original one to the
* empty list. Also, set ep->ovflist to NULL so that events
* happening while looping w/out locks, are not lost. We cannot
* have the poll callback to queue directly on ep->rdllist,
* because we want the "sproc" callback to be able to do it
* in a lockless way.
*/
spin_lock_irqsave(&ep->lock, flags);
list_splice_init(&ep->rdllist, &txlist);
ep->ovflist = NULL;
spin_unlock_irqrestore(&ep->lock, flags);
/*
* Now call the callback function.
*/
error = (*sproc)(ep, &txlist, priv);//ep_send_events_proc
spin_lock_irqsave(&ep->lock, flags);
/*
* During the time we spent inside the "sproc" callback, some
* other events might have been queued by the poll callback.
* We re-insert them inside the main ready-list here.
*/
for (nepi = ep->ovflist; (epi = nepi) != NULL;
nepi = epi->next, epi->next = EP_UNACTIVE_PTR) {
/*
* We need to check if the item is already in the list.
* During the "sproc" callback execution time, items are
* queued into ->ovflist but the "txlist" might already
* contain them, and the list_splice() below takes care of them.
*/
if (!ep_is_linked(&epi->rdllink))
list_add_tail(&epi->rdllink, &ep->rdllist);
}
/*
* We need to set back ep->ovflist to EP_UNACTIVE_PTR, so that after
* releasing the lock, events will be queued in the normal way inside
* ep->rdllist.
*/
ep->ovflist = EP_UNACTIVE_PTR;
/*
* Quickly re-inject items left on "txlist".
*/
list_splice(&txlist, &ep->rdllist);
if (!list_empty(&ep->rdllist)) {
/*
* Wake up (if active) both the eventpoll wait list and
* the ->poll() wait list (delayed after we release the lock).
*/
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
}
spin_unlock_irqrestore(&ep->lock, flags);
mutex_unlock(&ep->mtx);
/* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(&ep->poll_wait);
return error;
}3.2、默认是LT水平触发模式,ET边缘触发模式需要自己指定
static int ep_send_events_proc(struct eventpoll *ep, struct list_head *head,
void *priv)
{
struct ep_send_events_data *esed = priv;
int eventcnt;
unsigned int revents;
struct epitem *epi;
struct epoll_event __user *uevent;
/*
* We can loop without lock because we are passed a task private list.
* Items cannot vanish during the loop because ep_scan_ready_list() is
* holding "mtx" during this call.
*/
for (eventcnt = 0, uevent = esed->events;
!list_empty(head) && eventcnt < esed->maxevents;) {
epi = list_first_entry(head, struct epitem, rdllink);
list_del_init(&epi->rdllink);
// 由accept->tipc_create f_op对应(stream_ops/msg_ops)其中poll就是socket.c中的poll函数
revents = epi->ffd.file->f_op->poll(epi->ffd.file, NULL) &
epi->event.events;
/*
* If the event mask intersect the caller-requested one,
* deliver the event to userspace. Again, ep_scan_ready_list()
* is holding "mtx", so no operations coming from userspace
* can change the item.
*/
if (revents) {
if (__put_user(revents, &uevent->events) ||
__put_user(epi->event.data, &uevent->data)) {
list_add(&epi->rdllink, head);
return eventcnt ? eventcnt : -EFAULT;
}
eventcnt++;
uevent++;
if (epi->event.events & EPOLLONESHOT)
epi->event.events &= EP_PRIVATE_BITS;
else if (!(epi->event.events & EPOLLET)) { //意思是只要不是ET模式(即默认是LT模式)则继续加入rdlist列表,如果设置了ET则不再加入
/*
* If this file has been added with Level
* Trigger mode, we need to insert back inside
* the ready list, so that the next call to
* epoll_wait() will check again the events
* availability. At this point, noone can insert
* into ep->rdllist besides us. The epoll_ctl()
* callers are locked out by
* ep_scan_ready_list() holding "mtx" and the
* poll callback will queue them in ep->ovflist.
*/
list_add_tail(&epi->rdllink, &ep->rdllist);
}
}
}
return eventcnt;
}
其中POLLXX 系列和EPOLLXX宏数值是一样的,可以自己 测试
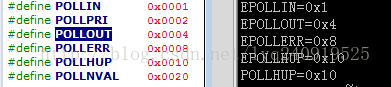
看下socket.c中的poll函数
static unsigned int poll(struct file *file, struct socket *sock,
poll_table *wait)
{
struct sock *sk = sock->sk;
u32 mask;
poll_wait(file, sk->sk_sleep, wait);
if (!skb_queue_empty(&sk->sk_receive_queue) ||
(sock->state == SS_UNCONNECTED) ||
(sock->state == SS_DISCONNECTING))
mask = (POLLRDNORM | POLLIN);
else
mask = 0;
if (sock->state == SS_DISCONNECTING)
mask |= POLLHUP;
else
mask |= POLLOUT;
return mask;
}















 9108
9108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









