







实习僧网站
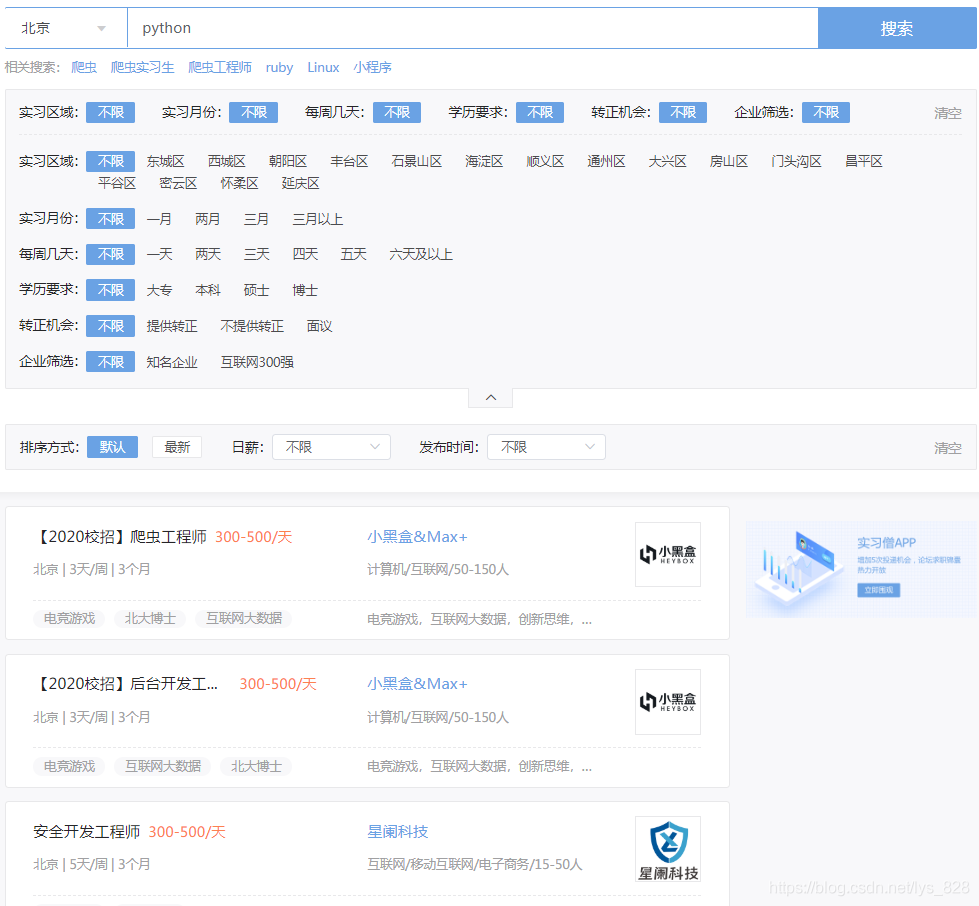
实习僧网址,地址为北京,在搜索框输入“python”,如下
实战解析
步骤一、建立for循环爬取前20页的内容
首先、查看翻页URL的信息,找规律
第一页:https://www.shixiseng.com/interns?page=1&keyword=python&type=intern&area=&months=&days=°ree=&official=&enterprise=&salary=-0&publishTime=&sortType=&city=%E5%8C%97%E4%BA%AC&internExtend=
第二页:https://www.shixiseng.com/interns?page=2&keyword=python&type=intern&area=&months=&days=°ree=&official=&enterprise=&salary=-0&publishTime=&sortType=&city=%E5%8C%97%E4%BA%AC&internExtend=
第三页:https://www.shixiseng.com/interns?page=3&keyword=python&type=intern&area=&months=&days=°ree=&official=&enterprise=&salary=-0&publishTime=&sortType=&city=%E5%8C%97%E4%BA%AC&internExtend=
......
发现只有page=后面的数值是不一样的,所以构造for循环(先获取少一点的页面),如下
for i in range(1,5):
req = requests.get(f'https://www.shixiseng.com/interns?page={i}&keyword=python&type=intern&area=&months=&days=°ree=&official=&enterprise=&salary=-0&publishTime=&sortType=&city=%E5%8C%97%E4%BA%AC&internExtend=',
headers = headers)
html = req.text
步骤二、获取每个职位的URL信息
进入浏览器后,点击检查,定位到职位一栏然后右侧会显示出对应的标签信息,可以信息是在div下的两个class标签下(class=“intern-wrap intern-item”,其中有一个空格,代表里面有两个class属性)
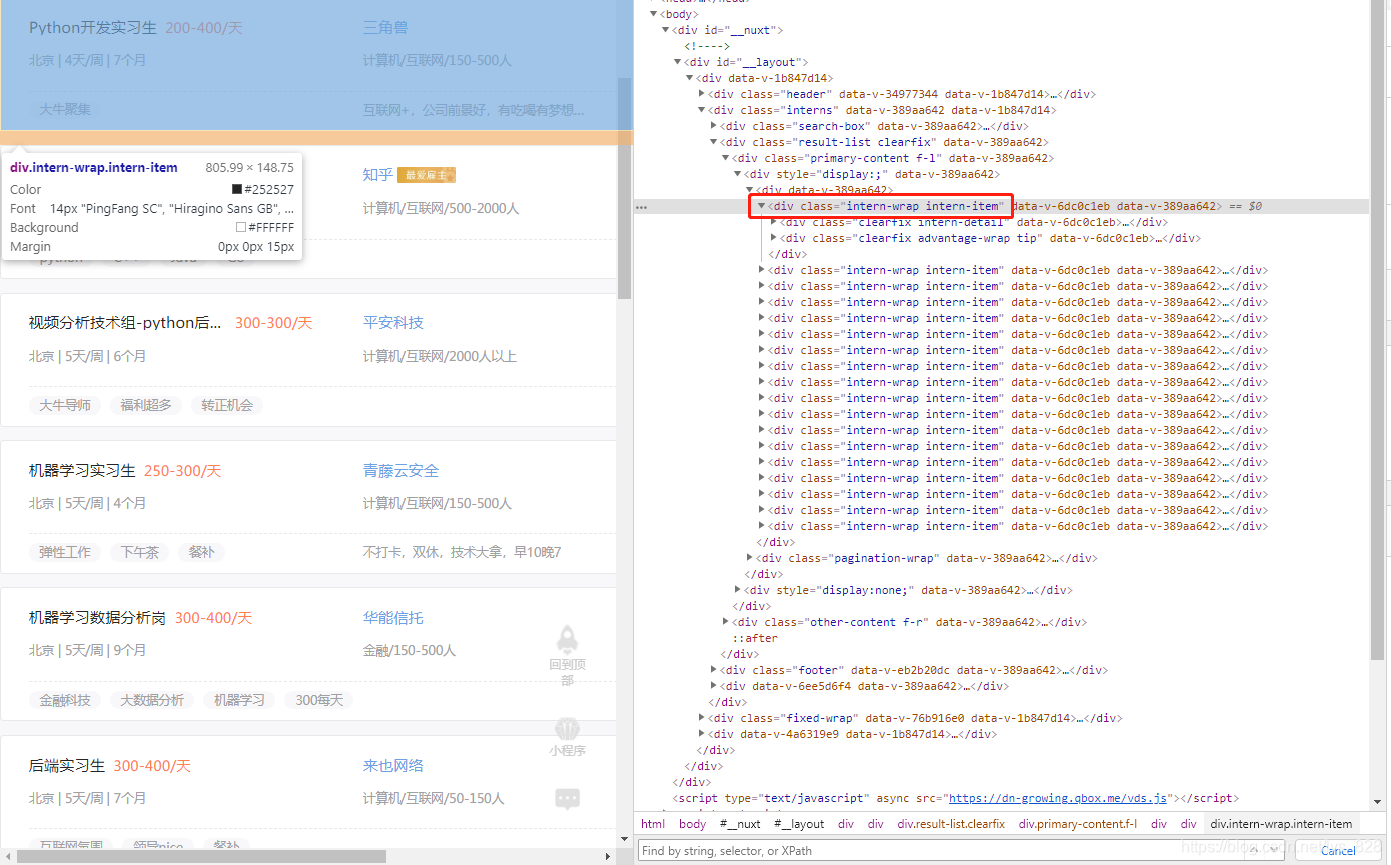
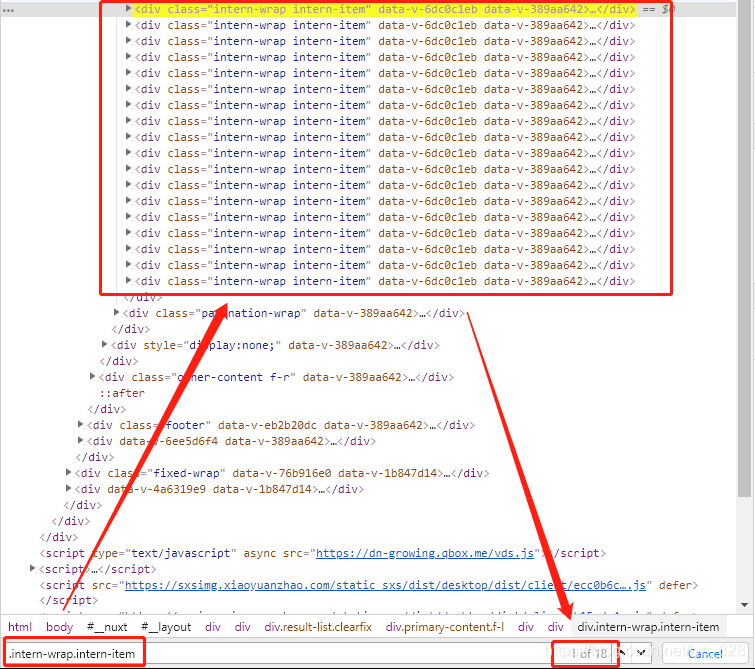
这时候就可以在右下方的查找框输入“.intern-wrap.intern-item"进行标签的搜索(注意这里是有两个点的)
soup = BeautifulSoup(html,'lxml')
offers = soup.select('.intern-wrap.intern-item')
接着是找到每个职位对应的URL,通过检查发现,该URL是在上面所选的标签的孙子class标签下面,因此可以使用“ .f-l.intern-detail__job a”方式访问(注意最开始是有个空格的,这里是访问了孙子标签,要有个空格,然后标签里面有一个空格,代表两个class属性,因此中间是要有两个点,最后选中该标签下的子标签a,中间加个空格即可),那么就可以遍历提取全部职位的URL信息了,关于里面的索引参数[0][‘href’],可以自己调试得出
for offer in offers:
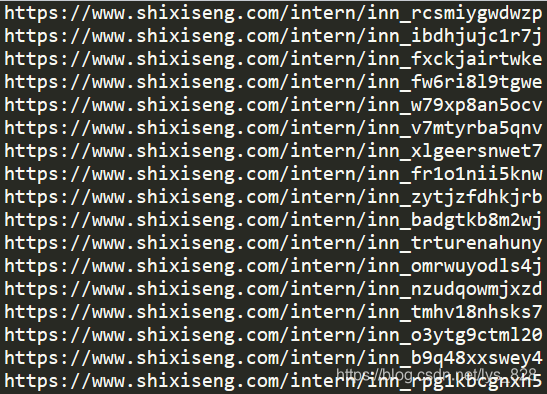
url = offer.select(" .f-l.intern-detail__job a")[0]['href']
print(url)
–> 输出结果为:这里只截取了部分
将该部分获取URL的过程封装成为函数,方便调用
def job_url():
for i in range(1,2):
req = requests.get(f'https://www.shixiseng.com/interns?page={i}&keyword=python&type=intern&area=&months=&days=°ree=&official=&enterprise=&salary=-0&publishTime=&sortType=&city=%E5%8C%97%E4%BA%AC&internExtend=',
headers = headers)
html = req.text
soup = BeautifulSoup(html,'lxml')
offers = soup.select('.intern-wrap.intern-item')
for offer in offers:
url = offer.select(" .f-l.intern-detail__job a")[0]['href']
detail_url(url)
最下面一行代码执行的功能就是将获得职位的URL打开,然后获取该页面的标题,具体函数的调用在步骤三
步骤三、进入每个职位的详情页再爬取
def detail_url(url):
html = requests.get(url,headers=headers).text
soup = BeautifulSoup(html, 'lxml')
title = soup.title.text
print(title)
job_url()
封装成函数后,只要调用函数即可,就不存在代码先后的问题了,这里直接调用job_url()函数就可以进行输出了,输出结果如下(时间是2020年2月3日的网站第一页的信息)
–> 输出结果为:
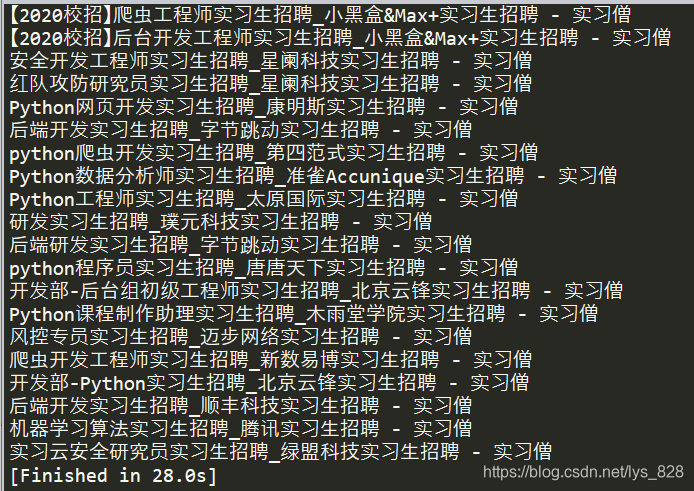
步骤四、获取公司名和职位名
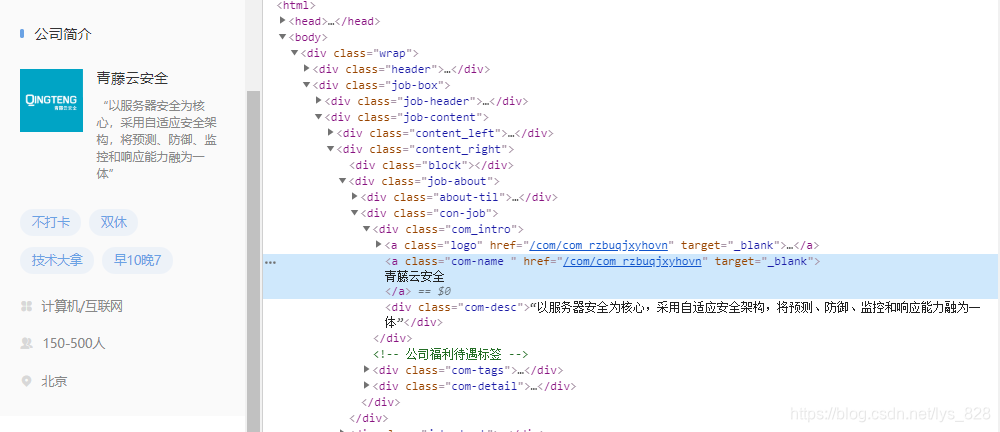
点击职位相应的URL,进入后点击检查,然后找到公司对应的标签,右侧的标签信息可以看到
职位名::通过上面的输出,可以发现职位名称就在title里面,只需要按照“招聘”进行切分字符串,取第一个数据就是职位的名称了
job = title.split("招聘")[0]
公司名称:可以发现公司的名称在class="com_intro"下的子标签a中的class中,因此可以通过“.com_intro .com-name ”’方式获取(有两个点一个空格),注意对获得的数据进行格式的处理输出
company_name = soup.select('.com_intro .com-name')[0].text.strip()
–> 输出结果为:

步骤五、获取薪金(字体反爬虫)
首先找到有数字的标签信息,通过初步检查可以发现,这里面的数字经过反扒处理(是其自定义的字体),直接查看标签信息是无法知道具体的数值的
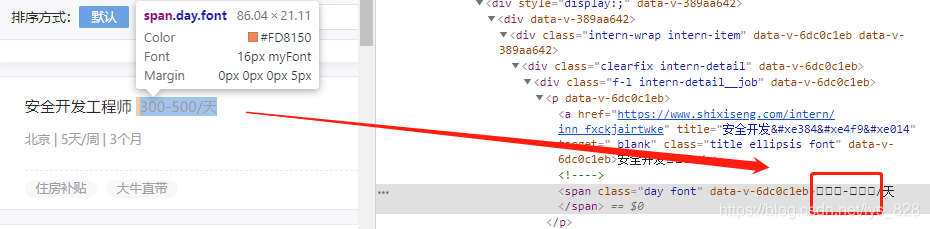
解决方式: 将数值对应的映射关系自己写一个出来
具体操作: 将薪资的内容获取到,然后转化成为我们可以识别的阿拉伯数字
进入具体的招聘信息的网页,找到薪金所对应的标签信息,然后发现其在两层class标签下,因此可以使用“.job_money.cutom_font”方式获取标签(中间两个点,没有空格)
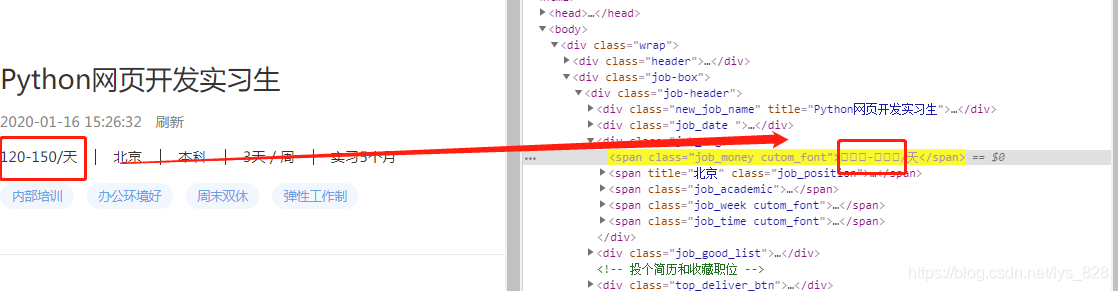
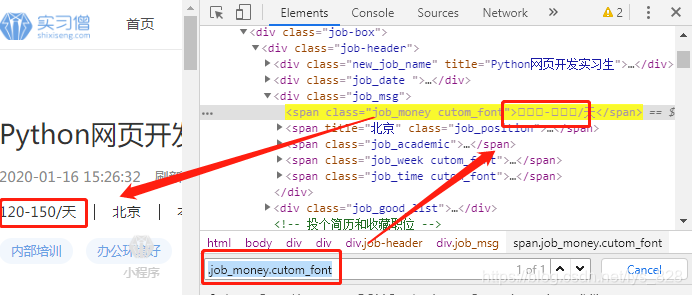
salary_text = soup.select(".day.font")[0].text
–> 输出结果为:部分截图
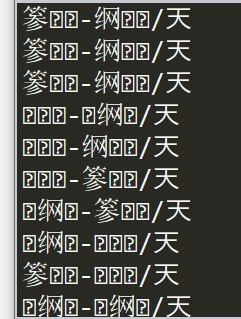
★★★ 进行数据映射,也就是将上面这些我们没有办法识别的字符转化成为我们可以直接识别的数值
先进行一个试错,创建一个新的.py文件,查看一下这些字符经过解码后是什么样子?测试代码如下`
import requests
from bs4 import BeautifulSoup
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}
url = "https://www.shixiseng.com/intern/inn_fxckjairtwke?mxa=asdd.0eqlx1.4xnxf0.b7vh6p"
req = requests.get(url,headers=headers)
html = req.text
soup = BeautifulSoup(html,"lxml")
job = soup.title.text.split("招聘")[0]
company_name = soup.select('.com_intro .com-name')[0].text.strip()
salary_text = soup.select(".job_money.cutom_font")[0].text
print("工作职位的名称为:{}\n薪金为:{}\n招聘公司的名称为:{}\n".format(job,salary_text,company_name))
print("该页面的薪金对应为:\n\n300-500/天")
print(f"{salary_text}".encode("utf-8"))
–> 输出结果为:
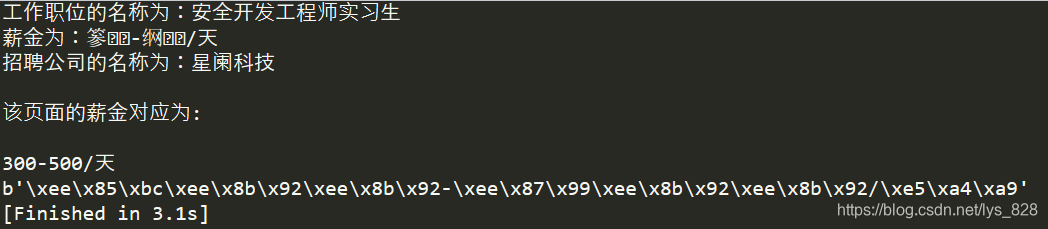
输出的前三行是为了查看采集的薪金是哪个公司和职位下的,用来确定输出我们可以直接识别的数值(300-500/天),最后一行就是输出将目标数据经过“utf-8”编码后所对应的输出十六进制的字符,经过比如可以发现,每个字符(包括数字和汉字)都应对\分割的三个字符组成的三块内容,分割如下:(这种对应的编码会更新)
数字3对应三块内容为:\xee\x85\xbc
数字0对应三块内容为:\xee\x8b\x92
数字5对应三块内容为:\xee\x87\x99
汉字天对应三块内容为:\xe5\xa4\xa9
因此按照这种方式就可以把数字对应的映射关系一一找到了
数字1对应的三块内容为:\xee\x9e\x88
数字2对应的三块内容为:\xef\x81\xa1
数字4对应的三块内容为:\xef\x84\xa2
数字6对应的三块内容为:\xee\x9b\x91
数字7对应的三块内容为:\xee\x94\x9d
数字8对应的三块内容为:\xee\xb1\x8a
数字9对应的三块内容为:\xef\x86\xbf
注意:数字7和9是在实习时间里面进行查找的,在薪金里面没有,重新解码后运行(也可以将所有的编码放在列表里,使用for循环)
salary = soup.select(".job_money.cutom_font")[0].text.encode("utf-8")
salary = salary.replace(b'\xee\x8b\x92',b"0")
salary = salary.replace(b'\xee\x9e\x88',b"1")
salary = salary.replace(b'\xef\x81\xa1',b"2")
salary = salary.replace(b'\xee\x85\xbc',b"3")
salary = salary.replace(b'\xef\x84\xa2',b"4")
salary = salary.replace(b'\xee\x87\x99',b"5")
salary = salary.replace(b'\xee\x9b\x91',b"6")
salary = salary.replace(b'\xee\x94\x9d',b"7")
salary = salary.replace(b'\xee\xb1\x8a',b"8")
salary = salary.replace(b'\xef\x86\xbf',b"9")
salary = salary.decode()
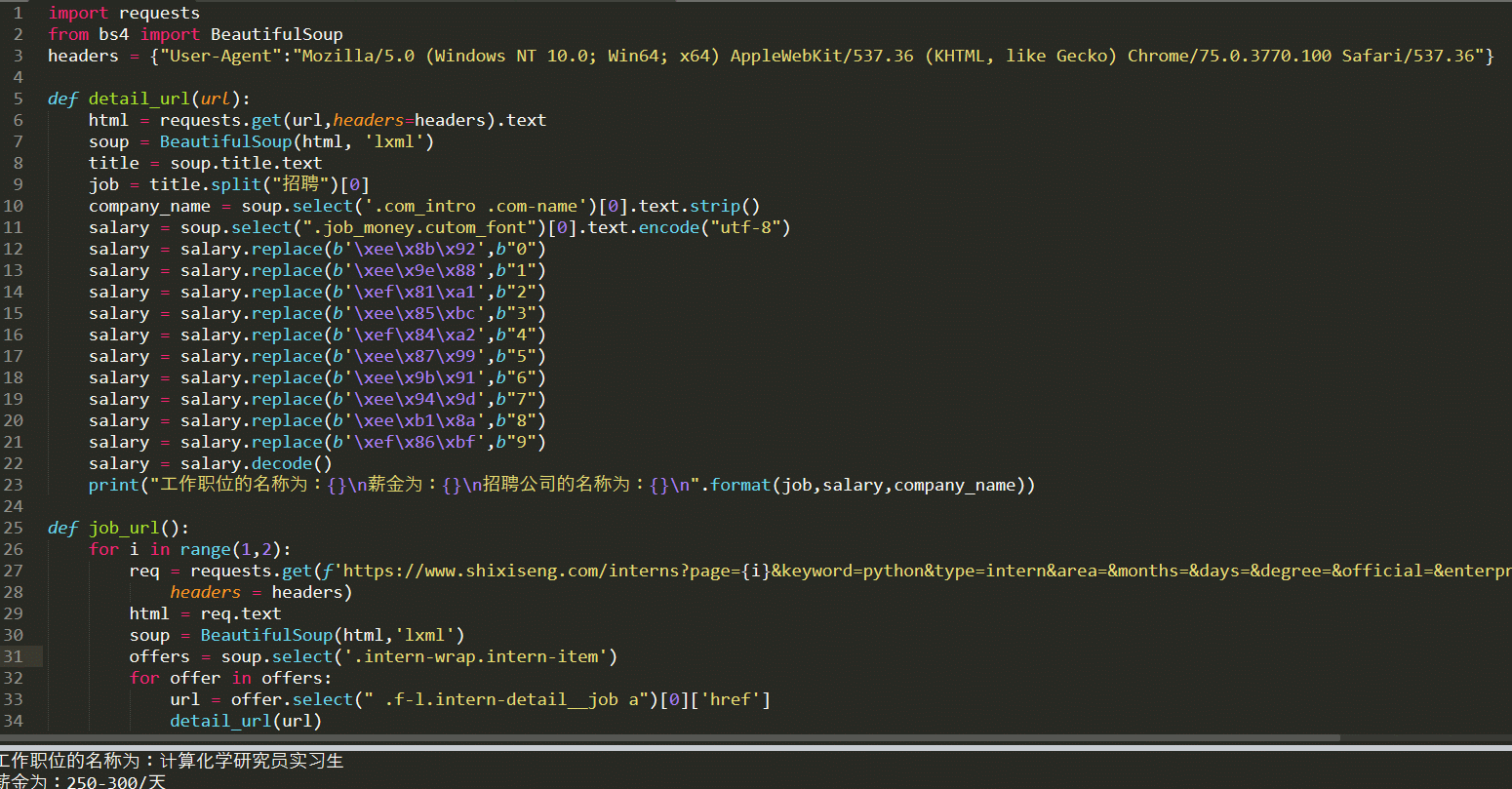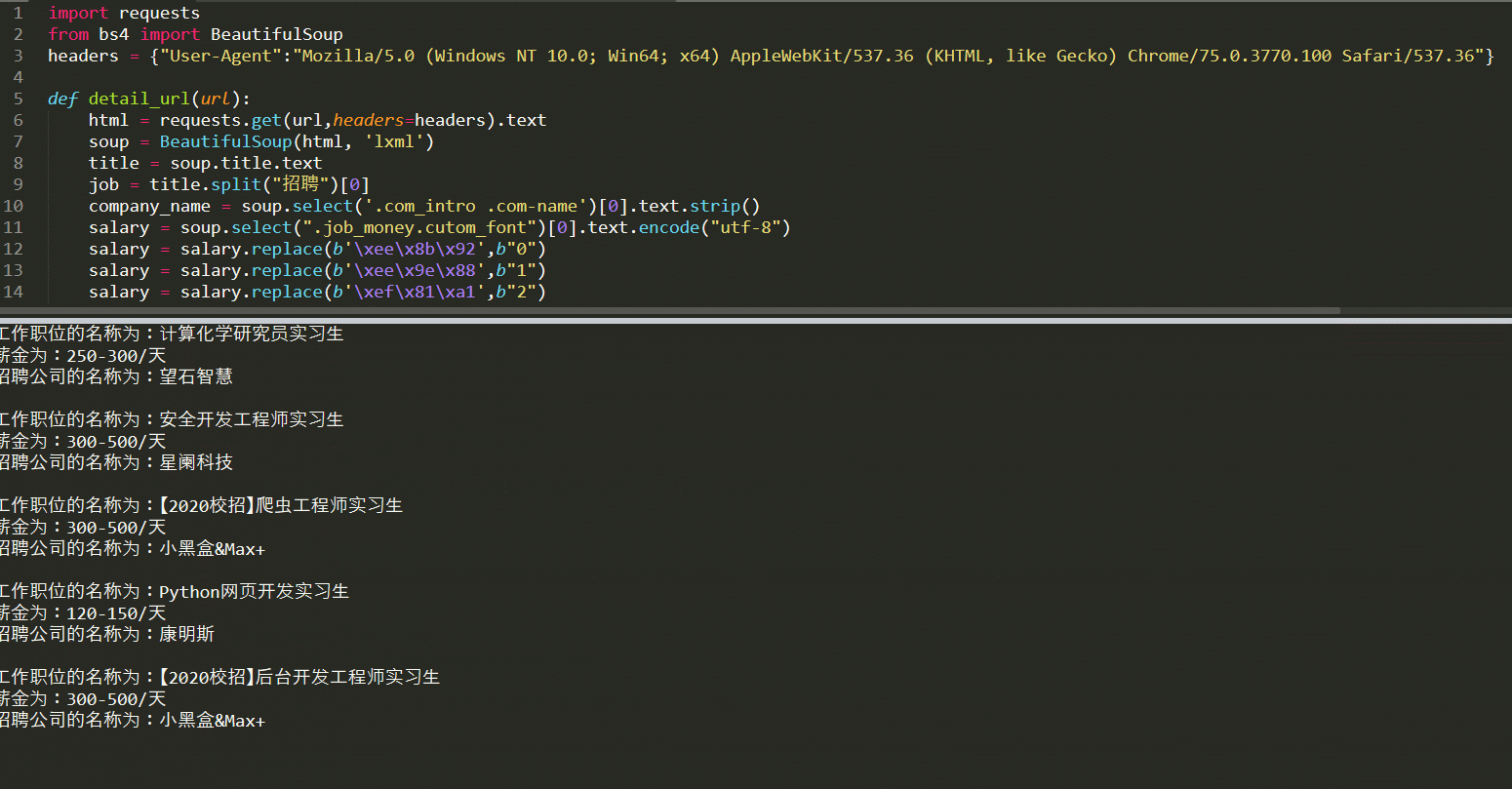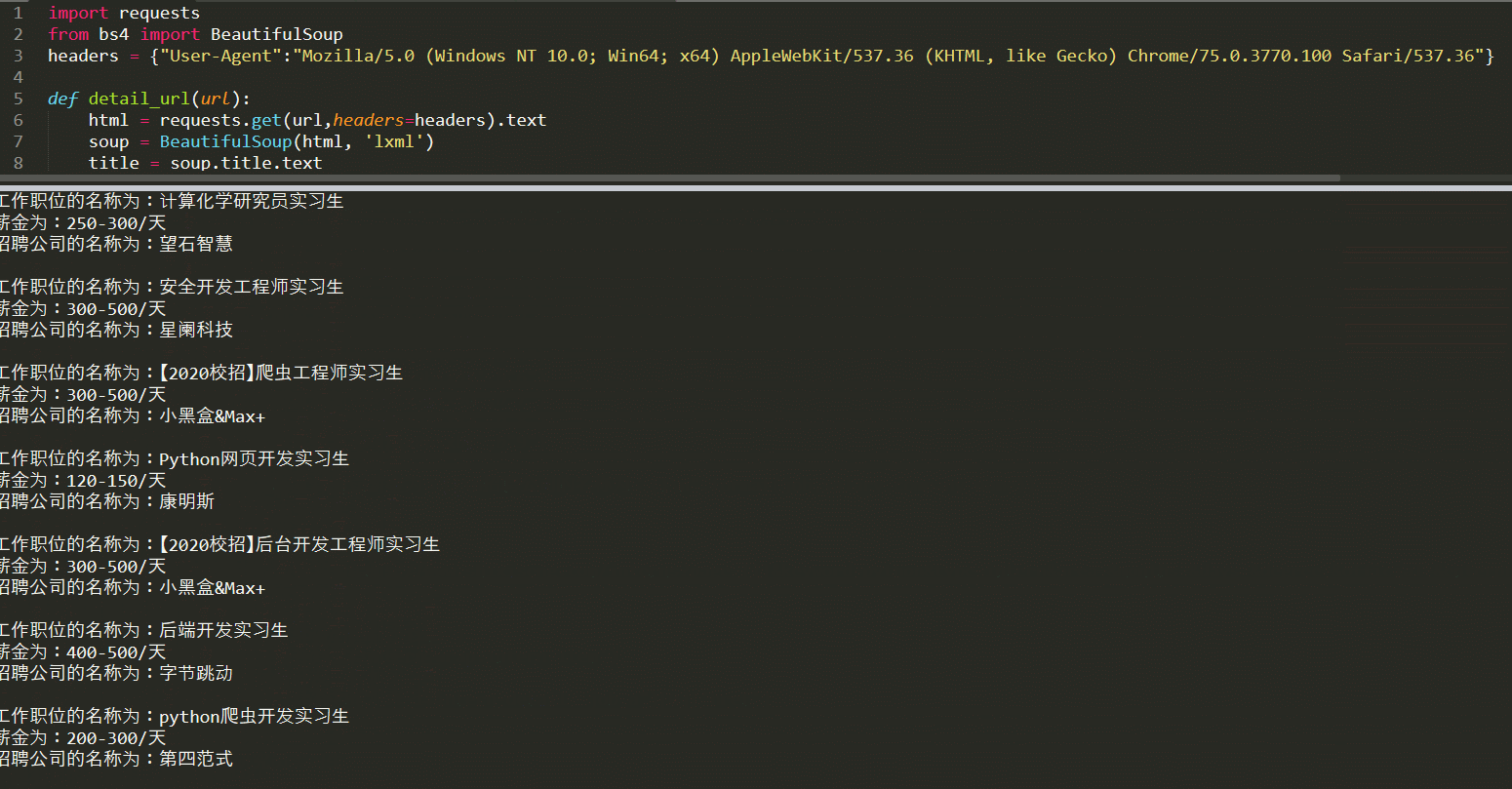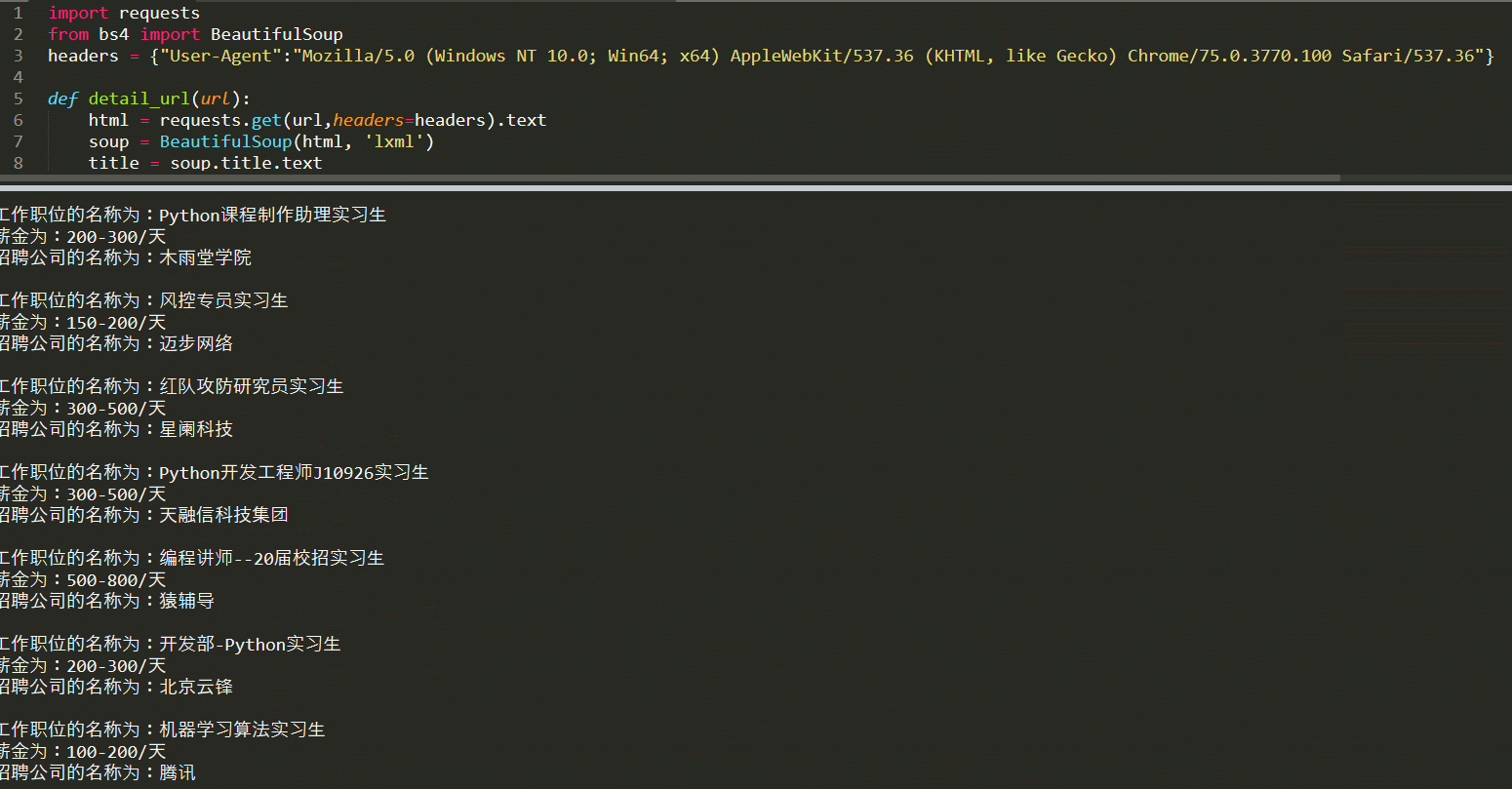
print("工作职位的名称为:{}\n薪金为:{}\n招聘公司的名称为:{}\n".format(job,salary,company_name))
–> 输出结果为:部分截图

全部代码
注意:网站的编码会更新,代码有时效性,掌握方法才是核心
import requests
from bs4 import BeautifulSoup
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}
def detail_url(url):
html = requests.get(url,headers=headers).text
soup = BeautifulSoup(html, 'lxml')
title = soup.title.text
job = title.split("招聘")[0]
company_name = soup.select('.com_intro .com-name')[0].text.strip()
salary = soup.select(".job_money.cutom_font")[0].text.encode("utf-8")
salary = salary.replace(b'\xee\x8b\x92',b"0")
salary = salary.replace(b'\xee\x9e\x88',b"1")
salary = salary.replace(b'\xef\x81\xa1',b"2")
salary = salary.replace(b'\xee\x85\xbc',b"3")
salary = salary.replace(b'\xef\x84\xa2',b"4")
salary = salary.replace(b'\xee\x87\x99',b"5")
salary = salary.replace(b'\xee\x9b\x91',b"6")
salary = salary.replace(b'\xee\x94\x9d',b"7")
salary = salary.replace(b'\xee\xb1\x8a',b"8")
salary = salary.replace(b'\xef\x86\xbf',b"9")
salary = salary.decode()
print("工作职位的名称为:{}\n薪金为:{}\n招聘公司的名称为:{}\n".format(job,salary,company_name))
def job_url():
for i in range(1,2):
req = requests.get(f'https://www.shixiseng.com/interns?page={i}&keyword=python&type=intern&area=&months=&days=°ree=&official=&enterprise=&salary=-0&publishTime=&sortType=&city=%E5%8C%97%E4%BA%AC&internExtend=',
headers = headers)
html = req.text
soup = BeautifulSoup(html,'lxml')
offers = soup.select('.intern-wrap.intern-item')
for offer in offers:
url = offer.select(" .f-l.intern-detail__job a")[0]['href']
detail_url(url)
job_url()
–> 输出结果为:















 367
367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











