







 本文介绍了网易云音乐在构建用户分群数据化运营智能决策引擎(诺伦)的过程,包括项目背景、挑战、解决方案和成果。诺伦平台旨在实现新客拉新、老客促活和流失召回,通过用户行为数据进行策略匹配和触达。在面临业务多繁荣和策略多复杂等挑战时,通过数据中台、标准化数据体系和优化策略确保数据稳定快速输出。项目成果体现在架构清晰、产出时效稳定和触达效果显著。未来将继续优化基线运维,提升数据服务能力并扩展数据架构。
本文介绍了网易云音乐在构建用户分群数据化运营智能决策引擎(诺伦)的过程,包括项目背景、挑战、解决方案和成果。诺伦平台旨在实现新客拉新、老客促活和流失召回,通过用户行为数据进行策略匹配和触达。在面临业务多繁荣和策略多复杂等挑战时,通过数据中台、标准化数据体系和优化策略确保数据稳定快速输出。项目成果体现在架构清晰、产出时效稳定和触达效果显著。未来将继续优化基线运维,提升数据服务能力并扩展数据架构。

导读:大数据时代,用户的行为深刻影响着企业产品的变革与创新,如何追溯和分析用户行为,沉淀数字资产,并利用它实现精准化营销和产品价值提升,需要更多的探索与实践。本次分享的题目为用户分群数据化运营智能决策引擎数据开发实践,将结合网易云音乐产品实例,阐述数仓侧如何从0到1开展用户数据产品的开发与治理,实现用户增长。
01
项目背景
首先和大家分享下用户分群数据化运营智能决策引擎的背景、产品链路、产品架构和数仓定位。
1. 背景介绍
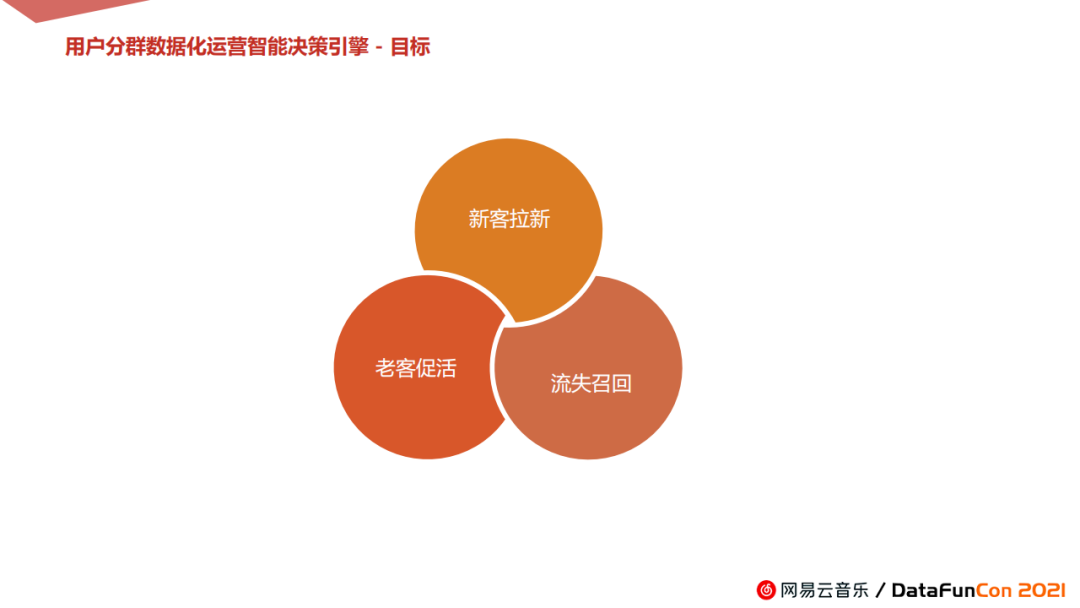
用户分群数据化运营智能决策引擎项目于今年八月下旬开始启动,在我们内部有一个非常好听的名字,叫做诺伦。它是一款面向用户增长的产品,重点聚焦三个方面:新客拉新、老客促活和流失召回。
2. 产品链路
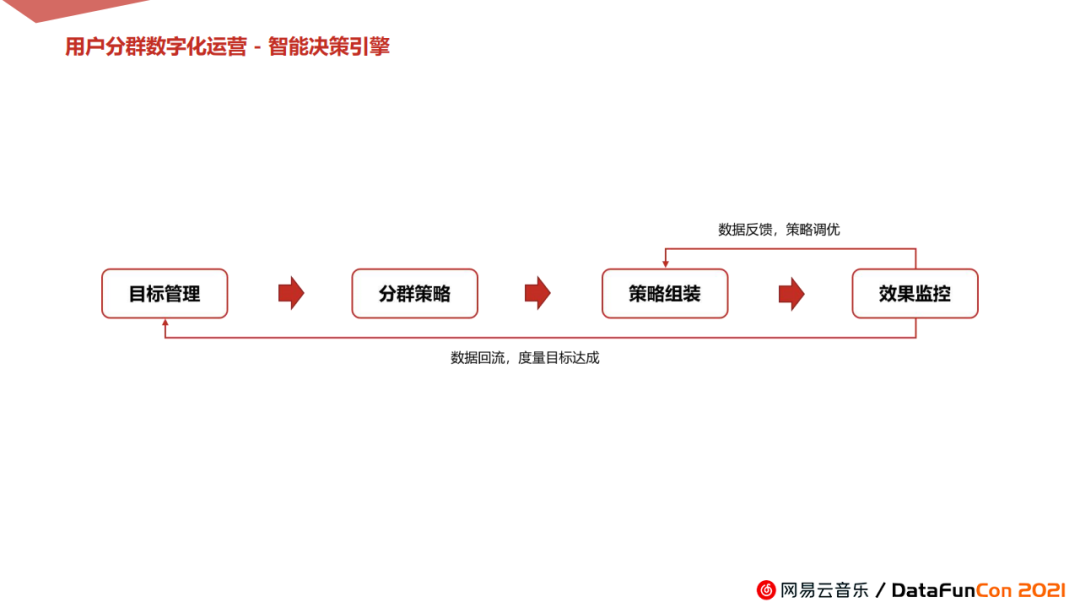
我们结合新客拉新,老客促活和流失召回的主体目标,依次拆解得出现有用户的分层分级和具体业务现状。寻找两者之间的差距点,确定重点运营方向,由此形成进一步的分群策略。例如:根据现有用户的活跃、消费、生产等情况,制定针对性的方向策略,比如内容触达、权益触达等等。在策略组装这一环节,我们将平台用户的历史行为数据,进行人、货、物的精准匹配,支持前端用户的可视化交互,实现一键发送、用户触达。同时将数据回流,进行监控和效果跟踪,指导策略优化。
3. 产品架构

上图是具体的产品架构图,主要分为数据输入层,智能决策层,触达通道层,以及数据回流。目前触达通道主要以push为主,后期我们会扩展出更多的触达通道。
整个产品系统建设有多个小组参与,包括数据产品,数据开发,前端/后端和系统测试人员等等。
4. 数仓职责
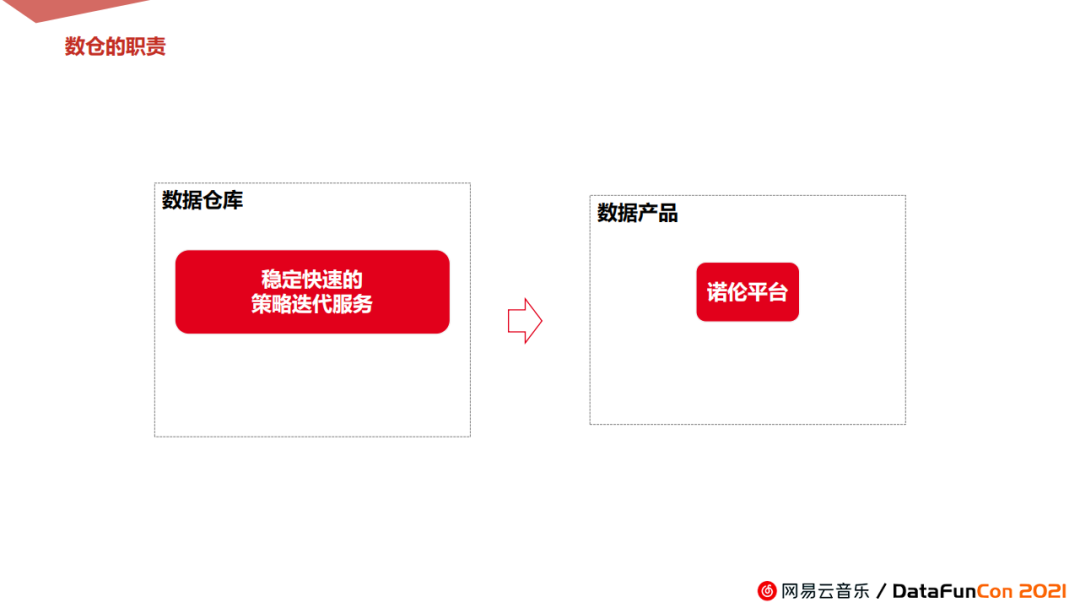
我们数仓在整个系统中的角色是最底层数据输入层,我们需要源源不断地提供数据给这个产品。简言之概括为:需要提供稳定快速的策略迭代服务,源源不断的输送给诺伦平台。
02
项目挑战
接下来,我们详细讲述用户分群数据化运营智能决策引擎的项目挑战。
1. 数仓角色
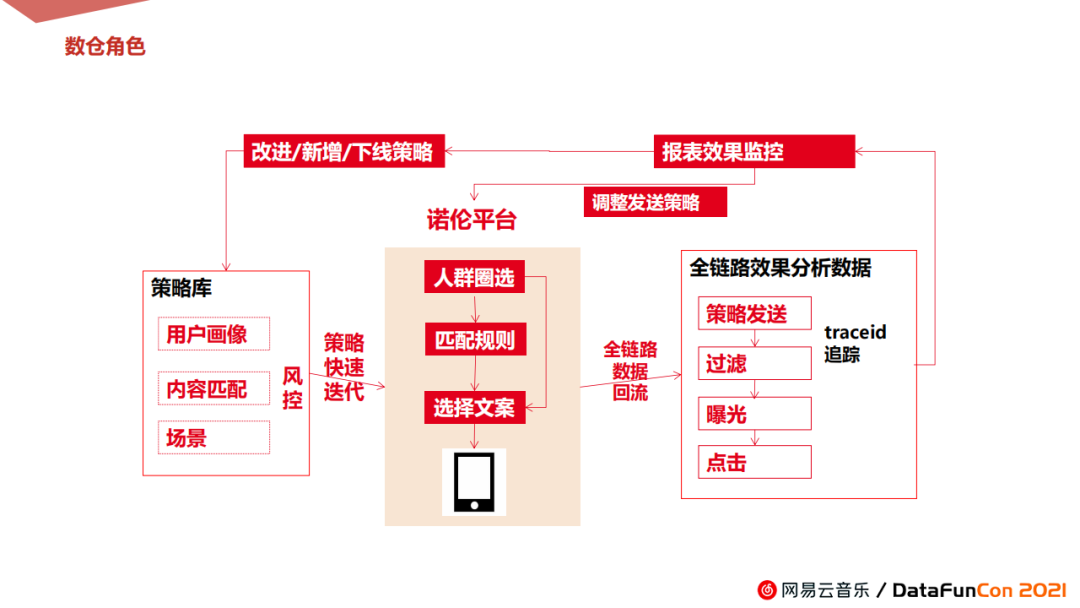
具体来说,数仓和诺伦的数据流转和交互对接大致如上图所示。
-
首先,我们每天会生成相应的策略,包含用户画像,内容匹配,还有一些场景类的数据,定时输送给诺伦平台,用户可进行人群圈选,匹配相应策略和对应文案,最后一键触达给平台终端用户。
-
其次,数仓负责全链路的效果分析数据回流,进行策略的效果监控,一方面可以调整运营策略;另一方面,可以优化我们的策略库,例如效果好的策略,我们会进一步优化,反之,效果不好的策略可进行下线操作,并探索更新更优的策略等等。
2. 面临的挑战
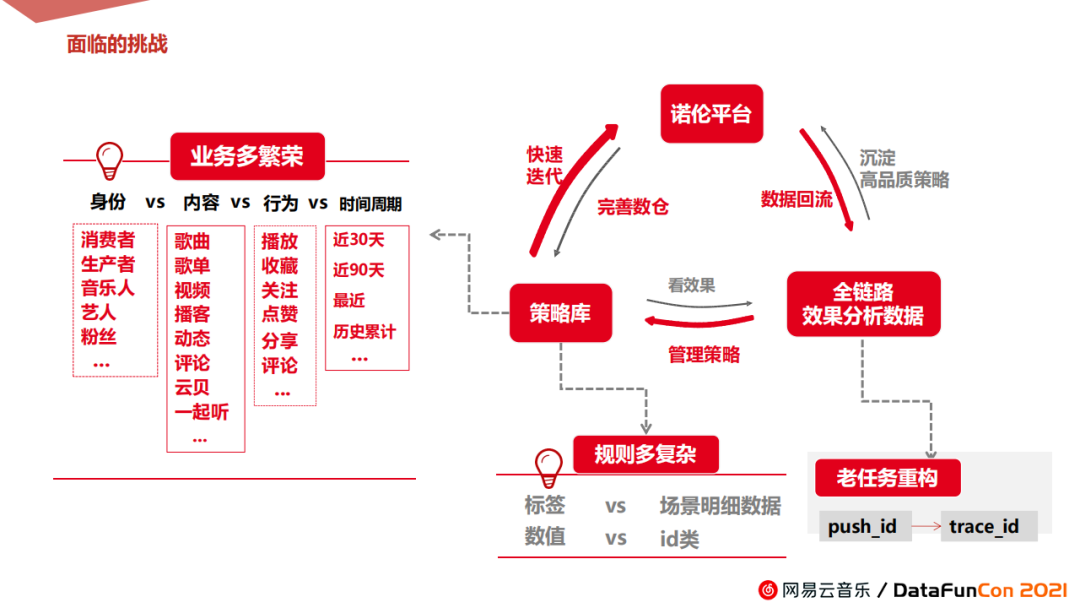
数仓面临的挑战,可以总结为两大方向:
① 业务多繁荣
-
身份:整个诺伦的运营场景非常丰富,包含内容消费类,内容生产类,社交关系类和功能使用类等等。业务生态同时聚集多个角色身份,有消费者,生产者,音乐人,艺人,粉丝关注等等。
-
内容:从业务线的角度,也非常庞大,主要集中在三大核心主线。第一个是以歌曲播放为场景,比如歌单,歌曲,专辑等等,第二个是社区场景,包含音乐视频,动态,评论和圈子等等。第三个是播客,声音和云贝,一起听等其它垂直业务和平台功能。
-
行为:行为方面主要是一些社交互动行为和播放行为。
-
时间周期:对指标的周期需求也比较多,有近30天,90天,历史累计等等。
从整个运营的角度,我们的业务相当繁荣,那对于数仓设计来说也是非常大的一个挑战。
② 策略多复杂
不仅需要一些统计类、预测类的标签,还需要某些场景的明细类数据,来辅助多样化的文案。
3. 数仓的挑战
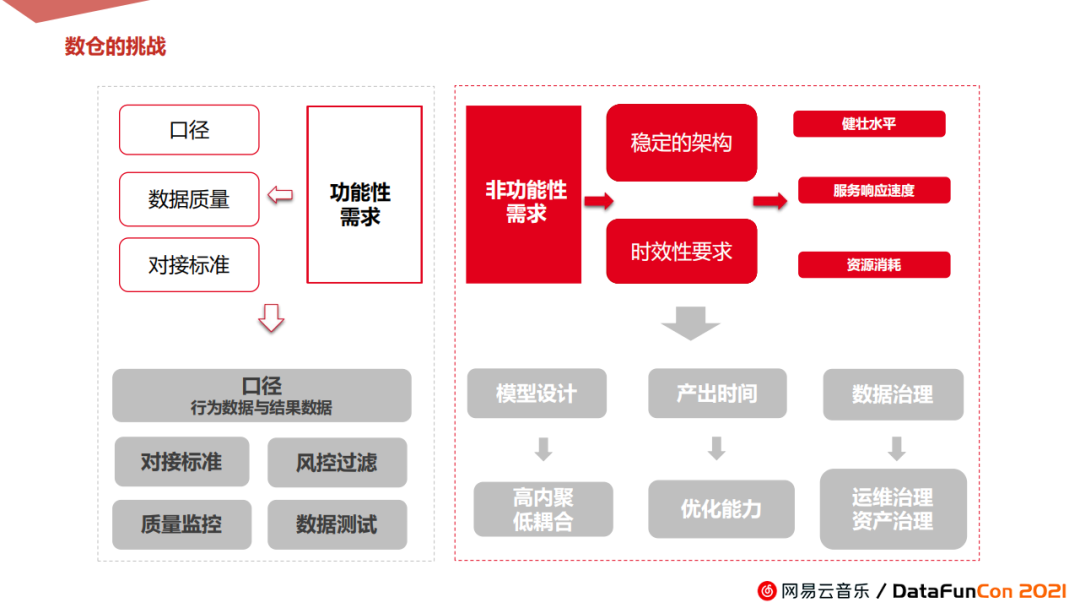
从产品系统的全局视野,数仓作为整个产品的数据输入层,是整个系统重要组成部分,需兼顾功能性需求和非功能性需求。
① 功能性层面主要分为三点:
-
口径足够清晰:需求定义需足够清晰,并与开发保持一致。例如行为类数据还是结果类数据需根据实际使用场景,对于诺伦的push场景我们严格使用结果类数据。
-
数据质量:包含两方面,数仓侧需确保数据有效性、一致性、完整性的测试,业务侧需过风控、黑名单以及是否满足需求等多方面的校验。
-
对接标准:数仓侧需对接整个系统,所以必须满足对接规范和标准,体现在数据固定格式,特殊字段和公共标记及命名等。
② 非功能性层面有以下三点:
-
稳定的架构:根据后续产品规划云音乐主APP和其他垂类业务都将对接诺伦,由此数仓非常需要有一个稳定、健壮、可扩展性的架构以满足业务扩张性发展。
-
时效性要求:严格保障产出时效,数据每天定点推送和输出,以满足运营日常工作的需要。
-
在数仓设计方面,还需在资源消耗角度做降本管理。
非功能性上具体来讲,就是分别在模型架构设计、产出时间、数据治理、资产管理等方面做考量。
03
项目方案
接下来,讲一下我们的项目方案。
1. 前置条件-数据中台和标准体系
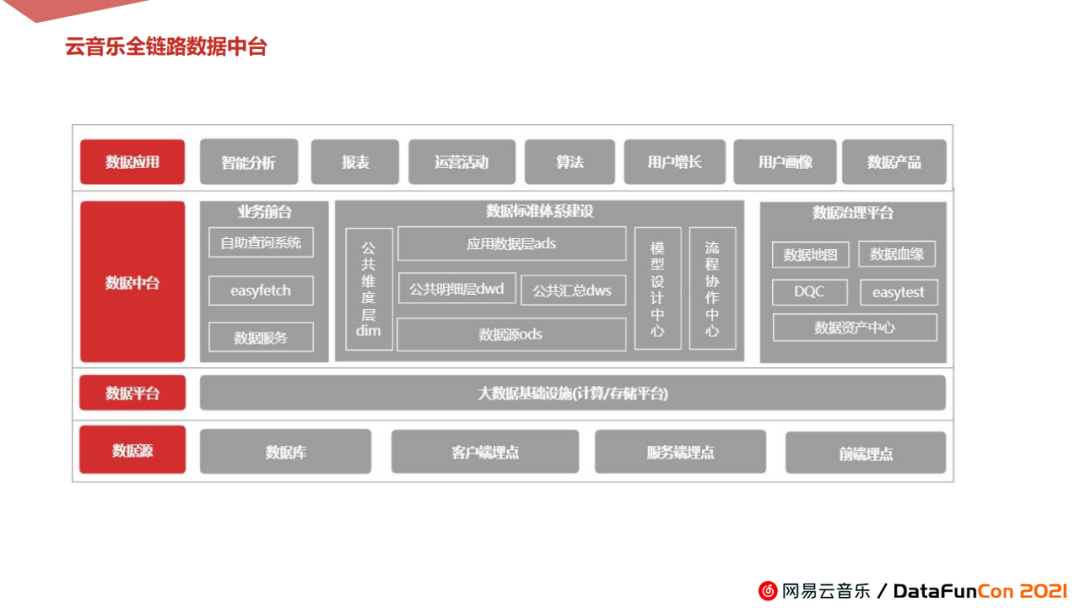
整个诺伦产品的数据开发工作都围绕着云音乐全链路数据中台展开。
如图所示,云音乐全链路数据中台包含网易自主研发的大数据存储和计算平台,具体有标准化数据建设体系,降本增效的数据产品工具和CICD工具,比如数据模型设计、评审工具、数据质量监测工具,还有上线任务评审、基线运维等等工具。此外还有面向用户的OLAP工具,支持SQL自主查询和面向运营端的简单拖拉拽的Easyfetch工具。
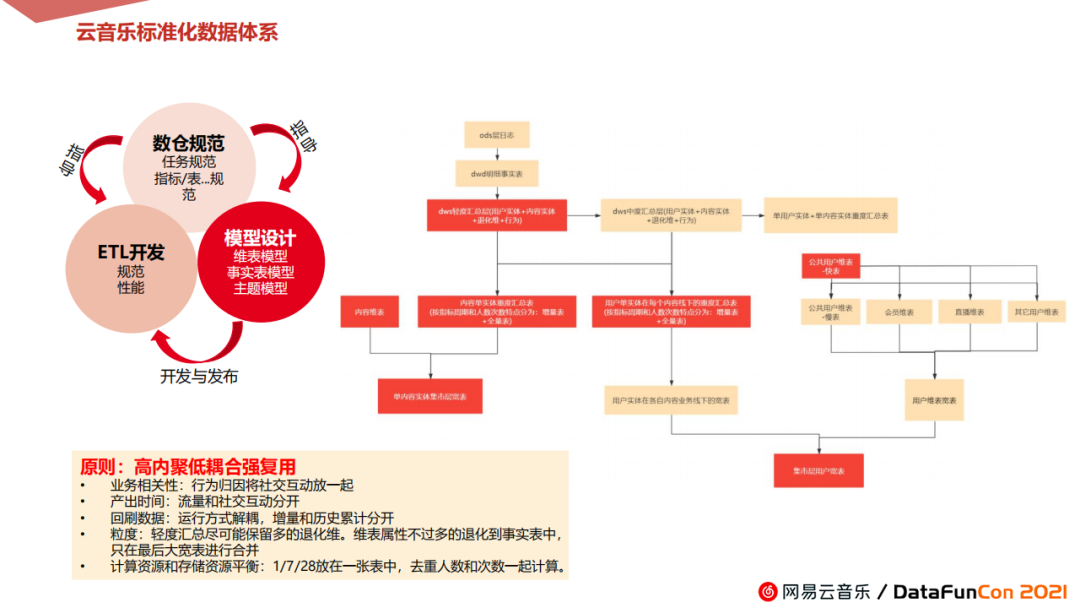
下面我们介绍云音乐的标准化数据体系,它从2019年下半年开始着手建设,采用业界公认的维度建模思想。
鉴于云音乐建设的自身特点、对流量的重视和复杂的商业模式,我们采用各条业务主线独立建设,并各自分层分域的方式,重点建设核心在DWS层,尤其重视DWS的第一层建设。主要包含对用户、内容,退化维和相关性行为做轻度聚合汇总。
在轻度汇总层,会向下往两个方向建设:内容和用户。
-
内容方面建设:根据它做一些内容中度和重度汇总的指标,有增量、全量等,并结合内容维表,建立单内容实体集成层宽表,再推送到Easyfetch平台展示,供用户自助查询分析。这样做可以极大减少数仓很多的临时性取数和数据咨询需求。
-
用户方向建设:我们会建立同具体业务线场景相关的用户指标,包括增量和全量表。
如此每条业务线都有业务相关的用户宽表和内容宽表,最后集成所有业务线的用户宽表和用户维表,组装后输出到集市层形成用户大宽表,最后输送给Easyfetch开放给用户使用。
纵观整个过程,采用高内聚低耦合强复用的原则,并根据云音乐的业务场景实时动态调整。主要体现在:
-
业务相关性:行为归因将社交互动放一起
-
产出时间:流量和社交互动分开
-
回刷数据:运行方式解耦,增量和历史累计模型分开
-
粒度:轻度汇总尽可能保留多的退化维。维表属性不过多的退化到事实表中,只在最后大宽表进行合并。
-
计算资源和存储资源平衡:将1d/7d/28d指标放在一张表中,去重人数和次数一起计算。
此外,云音乐已经建立自有的数仓规范和建模标准来指导日常开发,例如指标规范、数据表规范、存储规范、任务规范,以及贴合云音乐业务的模型设计架构。诺伦产品的开发也在这样的框架体系内,遵循统一的标准化数据体系,围绕着全链路数据中台进行。
2. 数据方案思路和机制
① 诺伦产品的数据方案思路
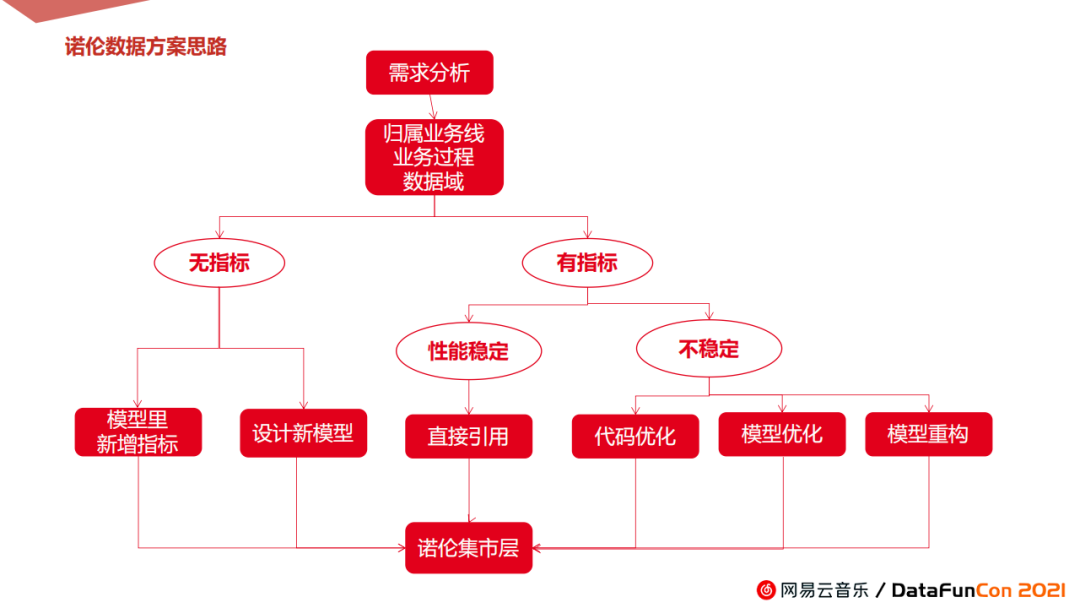
首先,从需求出发,进行需求分析和业务分析。然后将需求归属到对应业务线、业务过程以及数据域。
重点评估所属业务线是否有该指标,性能是否稳定。如果有且性能正常则不需要再开发,若性能不稳定则进行代码或者模型方向的优化等。如果对应指标缺失,我们会考虑是否必要新增模型,需要新建模型的话,就进行一系列的评审、开发等后续工作。没有必要新增模型的话,会把指标补充到相应的模型里。最后完成数据CDM层后,会输送到诺伦集市,集市层统一开发后,最后再传输给诺伦平台。
② 诺伦的数据开发流程和机制
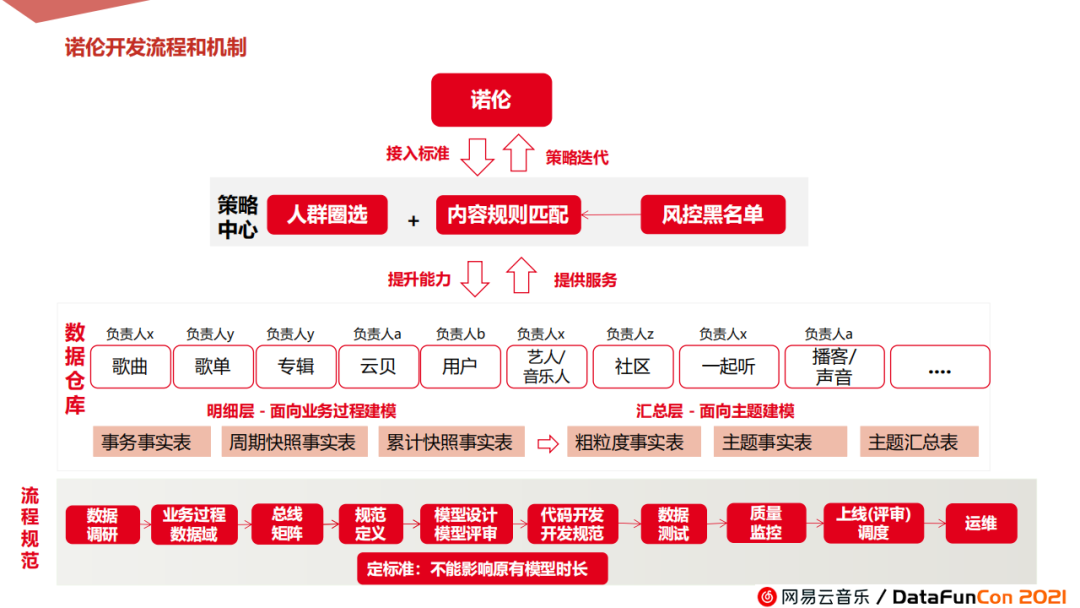
我们采用先分而治之后化整为零的建构思路。
采取歌曲、专辑、云贝、社区等多条业务线独立定向开发、优化,统一在策略中心集市层收口,组装成中心化集市层,最后统一输送至诺伦平台。
整条数据链路开发中严格遵循标准化开发流程和规范,如图所示,经历数据调研—总线矩阵—模型设计评审—数据测试—质量监控—上线调度—数据运维等多个环节。其中,数据开发过程中,我们也会借助一些质量测试、质量监控等CICD工具来提高我们的交付效率和交付质量,以达到降本提效的效果。
3. 数仓优化策略和保障
① 非功能性优化措施
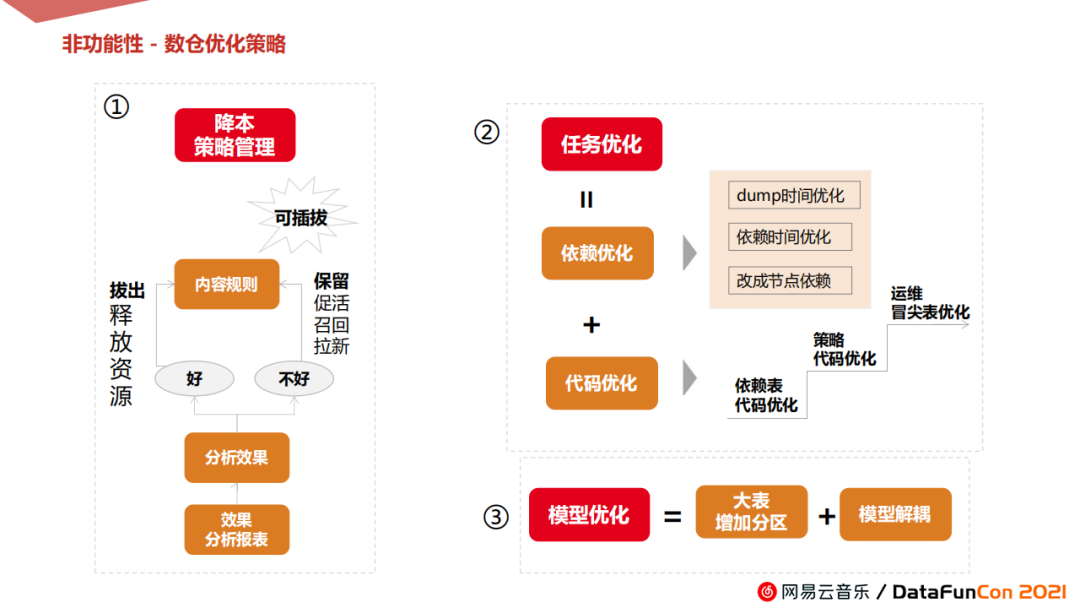
主要体现在3个方面:
-
降本策略管理:为达到降本效果,合理的计算资源和释放存储,集市层策略封装时,支持可插拔的方式,回流效果数据评估策略好坏,相应作出上线、下线和资源释放的等操作。
-
任务优化:重点工作在任务优化,首先是依赖优化,例如来源于数据库的表,减少从数据源传输到HDFS上的时间;调整血缘依赖图上的调度时间;将任务依赖改成节点依赖来保证每个策略可独立运行,不受其他策略的影响;更多的重点是在代码方面的优化,在CDM层开发阶段的一系列代码优化,在集市层策略组装过程中的优化,比如SQL的优化,根据业务特点优化数据实现方式、切换计算引擎、参数优化等。后续在策略上线后,观测整个数据流生产链路,对于不稳定的冒尖表着重优化,最终以达到数据生产流长期稳定的效果。
-
模型优化:对于一些大表,增加分区以保障它的可读性能;当某个指标性能不好,影响了整个模型产出时,我们也会针对模型做部分解耦工作,以便提高整体产出时效。
② 非功能性运维机制
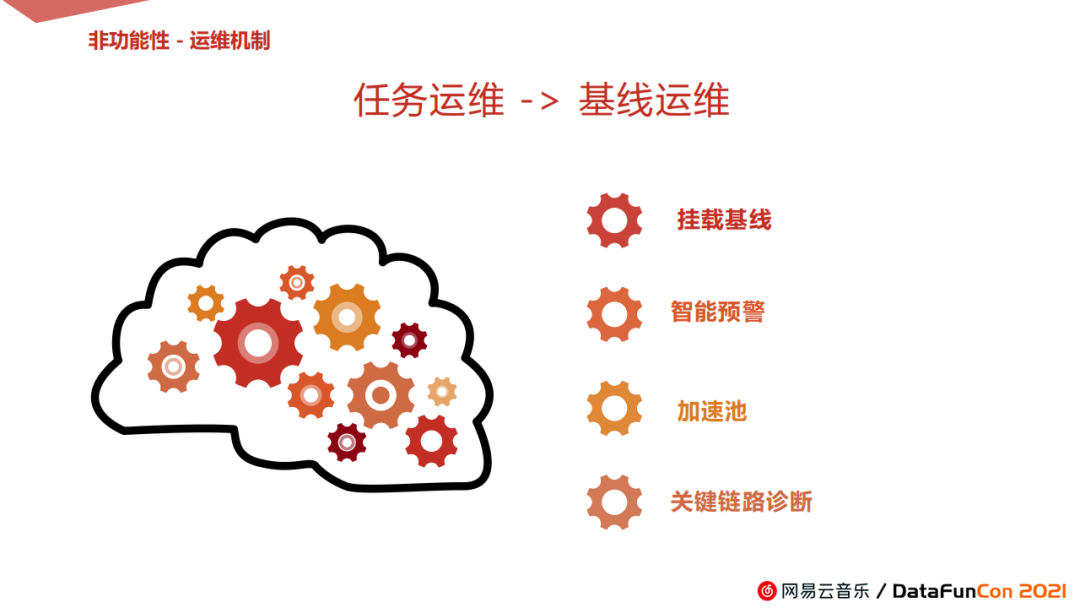
-
我们将先前的任务运维改成了基线运维。这源于我们云音乐是各业务线独立运维,开发工程师有可能对自己业务线的下游任务的重要性判断不准确,而成影响整体诺伦的产出效率,为此改成基线运维。
-
我们将应用层全部挂载在基线上,整条链路的任务自动被监控起来了,通过智能预警的功能,发现卡点环节,及时介入以确保数据产出的稳定。
-
此外还可利用加速池来加速数据产出,同时还有运维可视化展示,用以诊断和发现关键链路上的超时任务,以辅助整条链路的持续优化。
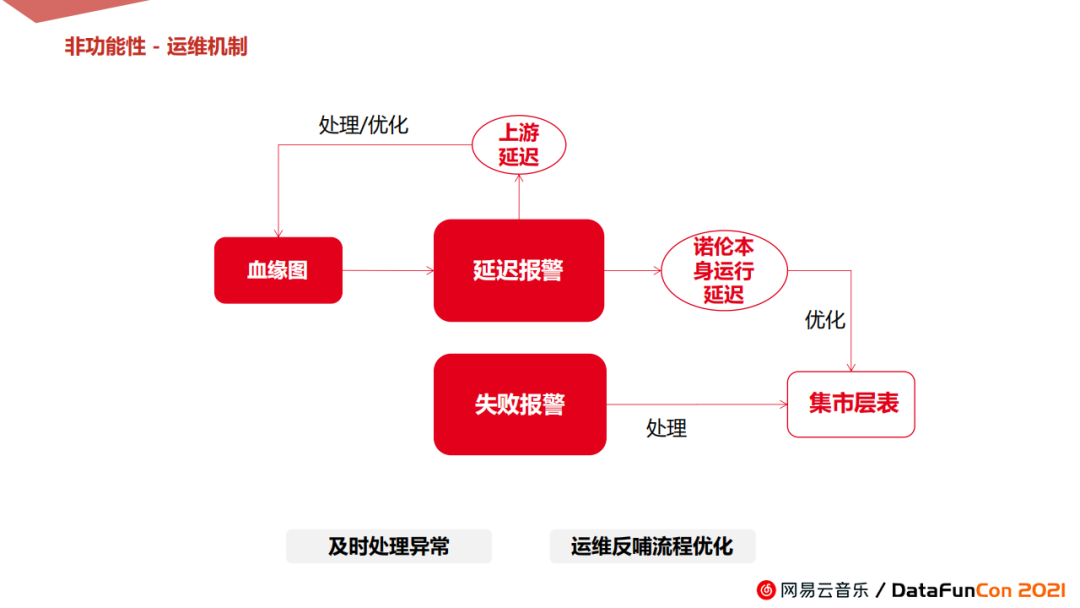
总体运维机制期望实现两个效果,一是及时处理延迟异常和报警异常,二是通过关键链路诊断,实现上下游全链路数据流的持续优化。
04
项目成果
下面讲一下经过上述的开发实践所积累的丰富项目成果。
1. 总体数据流程架构
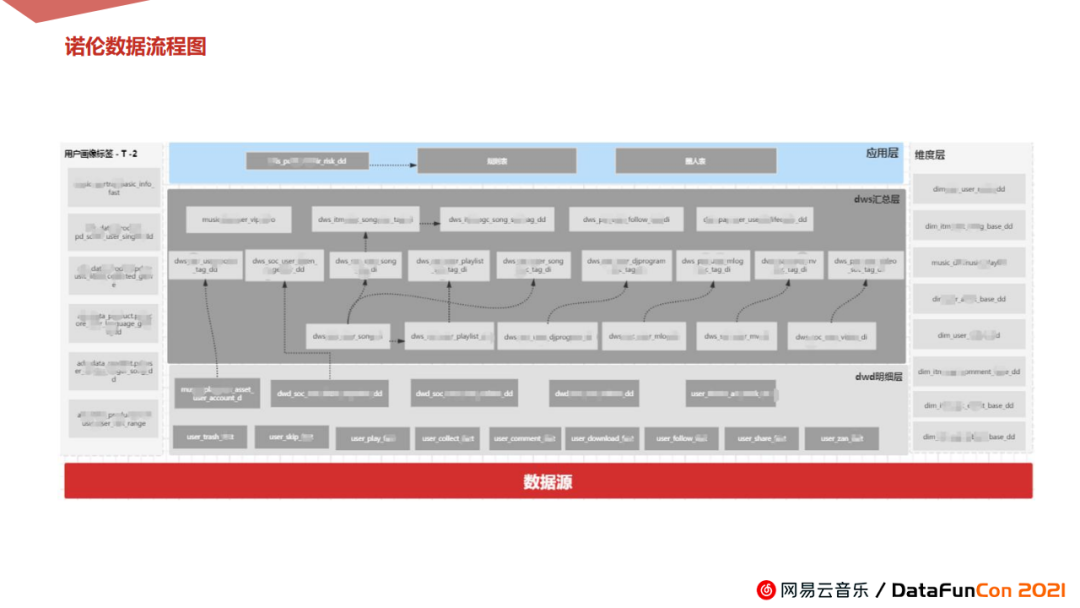
经过以上环节的操作,整个诺伦的数据流程图就像这张图所展示的,分为左侧的用户画像指标,右边维度层,中间事实表的模块结构。库表关系清晰,总体架构稳定。
2. 产出时效
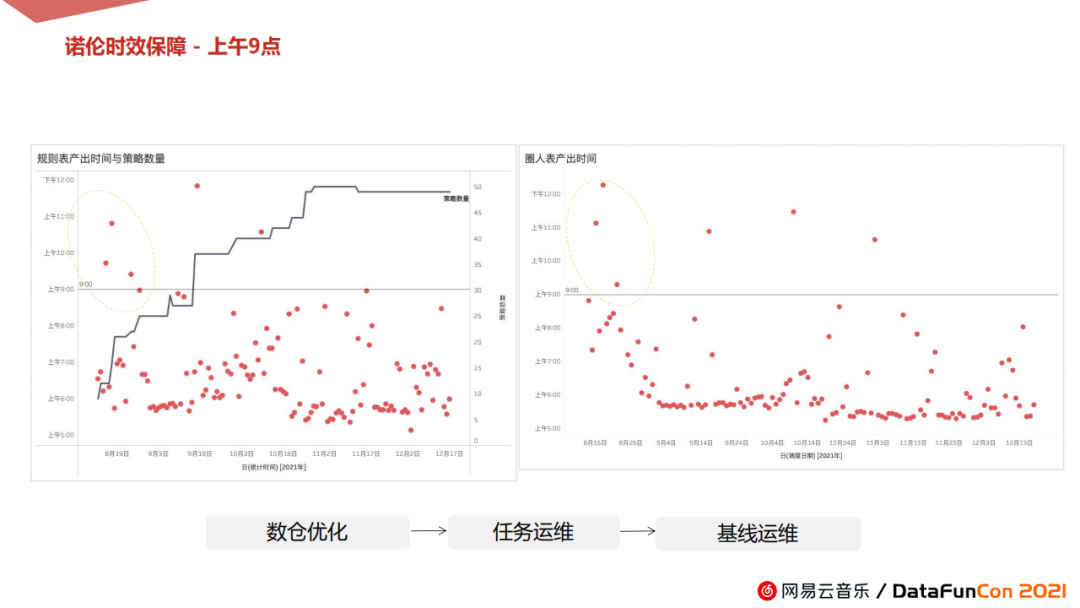
上图是我们的数据产出时间表。
从八月下旬截止到目前的数据产出趋势可见,前期联调阶段,黄色虚线框处会呈现短期震荡,此时进行了大量的CDM层和集市层的优化工作。中间偶尔有冒尖表出现震荡,专项优化,也有些是任务运维带来的震荡。将任务运维改成基线运维之后,数据输送的时间保障都控制在有效范围内。
3. 触达效果
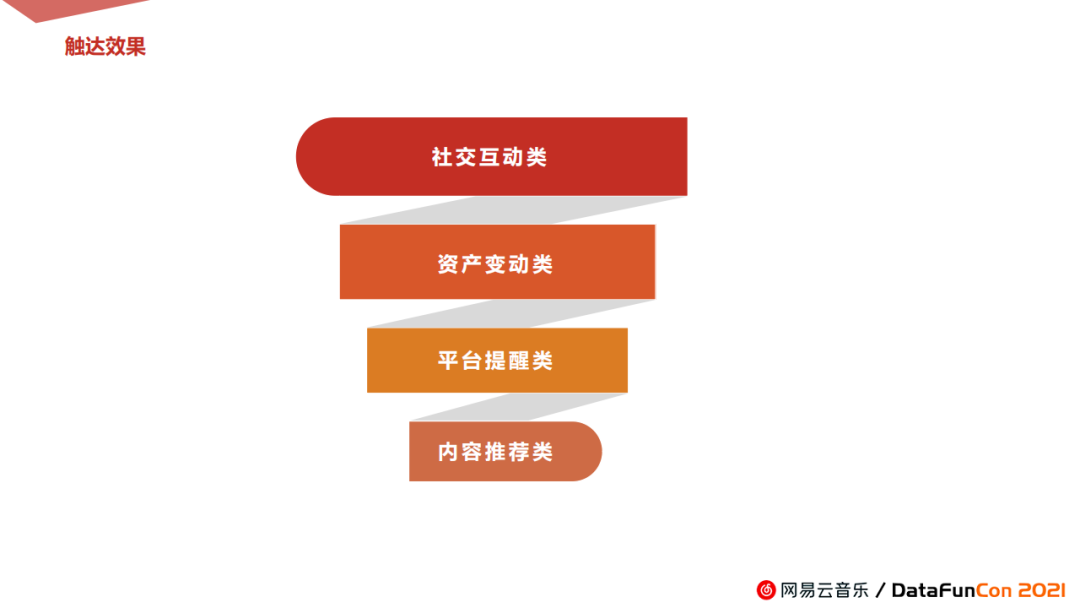
具体来看下,诺伦产品的触达效果。按照效果排序,第一个是社交互动类,其次是资产变动类,再往下是平台提醒类和内容推荐类。效果最显著时可达到3%的点击率,具体推送数量可达几万、上百万乃至上千万。
4. 项目成果总结
整体总结下,我们在整个开发过程中,把握住了5个重点:
-
标准化数据体系:围绕着数据中台的标准模型架构和数据规范来指导开发实践。
-
研发流程:全链路的研发流程非常严谨,从模型设计到交付有完整过程管控。
-
计算优化:我们进行了大量的计算优化,包含依赖优化、引擎优化和SQL优化等。
-
基线运维:上线产出后采用基线运维方式,给诺伦平台提供有力保障。
-
DataOps加持:利用CICD的数据相关产品工具,支持数据质量测试、数据质量监控等,极大地提高了交付质量和交付效率。
5. 诺伦产品的未来展望
-
加强基线运维:由于基线运维上线时间较短,后续着重做更多的优化工作。
-
产品功能迭代:有针对性提升策略覆盖率和响应度,以便接入更多的垂类业务和创新业务。
-
提升数据服务能力:丰富用户画像和数据资产,扩展诺伦平台的数据架构。
-
数据资产治理:伴随着策略的不断增加,合理布局、科学控制计算和存储资源。

















 440
440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









