







对于每一个表(table)或者分区,Hive可以进一步组织成桶。Hive也是针对某一列进行桶的组织。Hive采用对列值哈希,然后除于桶的个数求余的方式决定该条记录存放在哪个桶当中。采用桶能够带来一些好处,比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大减少JOIN的数据量。
Hive中table可以拆分成Partition,table和Partition可以通过'CLUSTERED BY'进一步分bucket,bucket中的数据可以通过'SORT BY'排序。
Hive中bucket的主要作用:
1.数据sampling
2.提升某些查询操作效率,列如Map Side join
注:cluster by和sorted by不会影响数据的导入,这意味着,用户必须自己负责数据如何导入,包括数据的分桶和排序。另外一个要注意的就是使用桶表的使用一定要设置如下属性:
hive.enforce.bucketing=true示例:
#建立student表,如下:
hive (hive)> create table student(
> id int,age int,name string)
> partitioned by (stat_date string)
> clustered by(id) sorted by(age) into 2 buckets
> row format delimited
> fields terminated by '\t'
> stored as textfile;
> stored as textfile;
OK
Time taken: 0.101 seconds#创建数据源
[root@liaozhongmin5 src]# vim student
[root@liaozhongmin5 src]# more student
1 22 lavimer
2 23 liaozhongmin
3 24 liaozemin
4 25 liaomin
5 26 min#启用桶表
hive (hive)> set hive.enforce.bucketing=true;#导入数据
hive (hive)> load data local inpath '/usr/local/src/student' into table student partition(stat_date='2015-01-29');
hive (hive)>
> insert overwrite table student
> partition(stat_date='2015-01-29')
> select id,age,name from student where stat_date='2015-01-29' sort by age;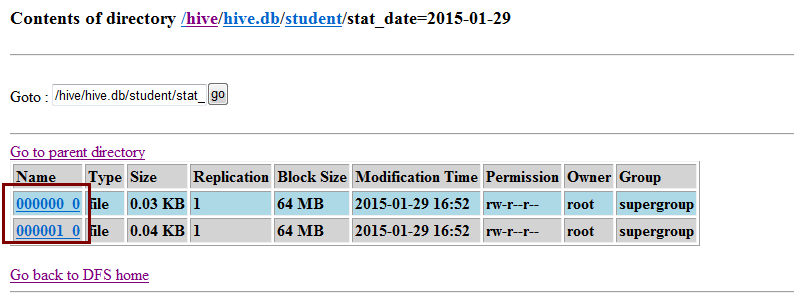

注:不知道为什么使用load data的形式导入数据时就不会有分桶的结构。
#查看所有数据
hive (hive)> select * from student;
OK
id age name stat_date
1 22 lavimer 2015-01-29
2 23 liaozhongmin 2015-01-29
3 24 liaozemin 2015-01-29
4 25 liaomin 2015-01-29
5 26 min 2015-01-29
Time taken: 0.328 seconds#查看sampling数据
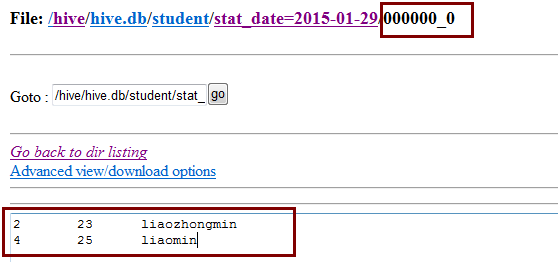
hive (hive)> select * from student tablesample(bucket 1 out of 2 on id);注:上述语句表示抽取1(2/2)个bucket的数据从第一个桶中抽取数据。
id age name stat_date
2 23 liaozhongmin 2015-01-29
4 25 liaomin 2015-01-29注:
tablesample是抽样语句,语法:tablesample(bucket x out of y),y必须是table总共bucket数的倍数或者因子。Hive根据y的大小,决定抽样的比例。例如:table总共分了64份,当y=32时,抽取2(64/32)个bucket的数据,当y=128时,抽取1/2(64/128)个bucket的数据。x表示从哪个bucket开始抽取。例如:table总共bucket数为32,tablesample(bucket 3 out of 16)表示总共抽取2(32/16)个bucket的数据,分别为第三个bucket和第19(3+16)个bucket的数据。















 1070
1070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









