







这一次的博客其实是接着上一次的,即对上一次博客的补充
首先,我们从缩减说起:
缩减方法
当数据的特征数高于样本数,或者特征之间高度相关时,会导致
XTX
奇异,从而限制了LR和LWLR的应用。这时需要考虑使用缩减法。
缩减法,可以理解为对回归系数的大小施加约束后的LR,也可以看作是对一个模型增加偏差(模型预测值与数据之间的差异)的同时减少方差(模型之间的差异)。
一种缩减法是岭回归(L2),另一种是lasso法(L1),但由于计算复杂,一般用效果差不多但更容易实现的前向逐步回归法。下面针对这两种方法详细介绍。
注意在使用缩减法时,需要对特征作标准化处理,一般对于输入是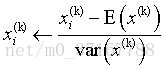
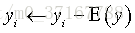
1. 岭回归
岭回归实际上相当于有约束条件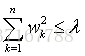
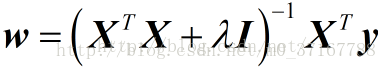
在进行特征选择时,一般有三种方式:
- 子集选择
- 收缩方式(Shrinkage method),又称为正则化(Regularization)。主要包括岭回归和lasso回归(后面会对此介绍)。
- 维数缩减
岭回归(Ridge Regression)是在平方误差的基础上增加正则项,如下:

通过确定
λ
的值可以使得在方差和偏差之间达到平衡:随着
λ
的增大,模型方差减小而偏差增大。
对
ω
求导,结果为
2XT(Y−XW)−2λW
令其为0,可求得
ω
的值:
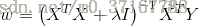
关键代码如下:
### Ridge Regression ###
def ridgeRegres(xMat, yMat, lam=0.2):
xTx = xMat.T * xMat
denom = xTx + lam*eye(shape(xMat)[1])
if linalg.det(denom) == 0.0:
print "This matrix is singular, cannot do inverse"
return
ws = denom.I * (xMat.T*yMat)
return ws
def ridgeTest(xArr, yArr):
xMat = mat(xArr)
xMeans = mean(xMat, 0)
xVar = var(xMat, 0)
xMat = (xMat-xMeans) / xVar
yMat = mat(yArr).T
yMean = mean(yMat, 0)
yMat = yMat - yMean
numTestPts = 30
wMat = zeros((numTestPts, shape(xMat)[1]))
for ii in range(numTestPts):
ws = ridgeRegres(xMat, yMat, exp(ii-10))
wMat[ii,:] = ws.T
return wMat
逐步回归
关于逐步回归的部分在上一次已经整理过了,其代码部分放在一起使用即可(读取数据部分通用)














 6941
6941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









