







目录
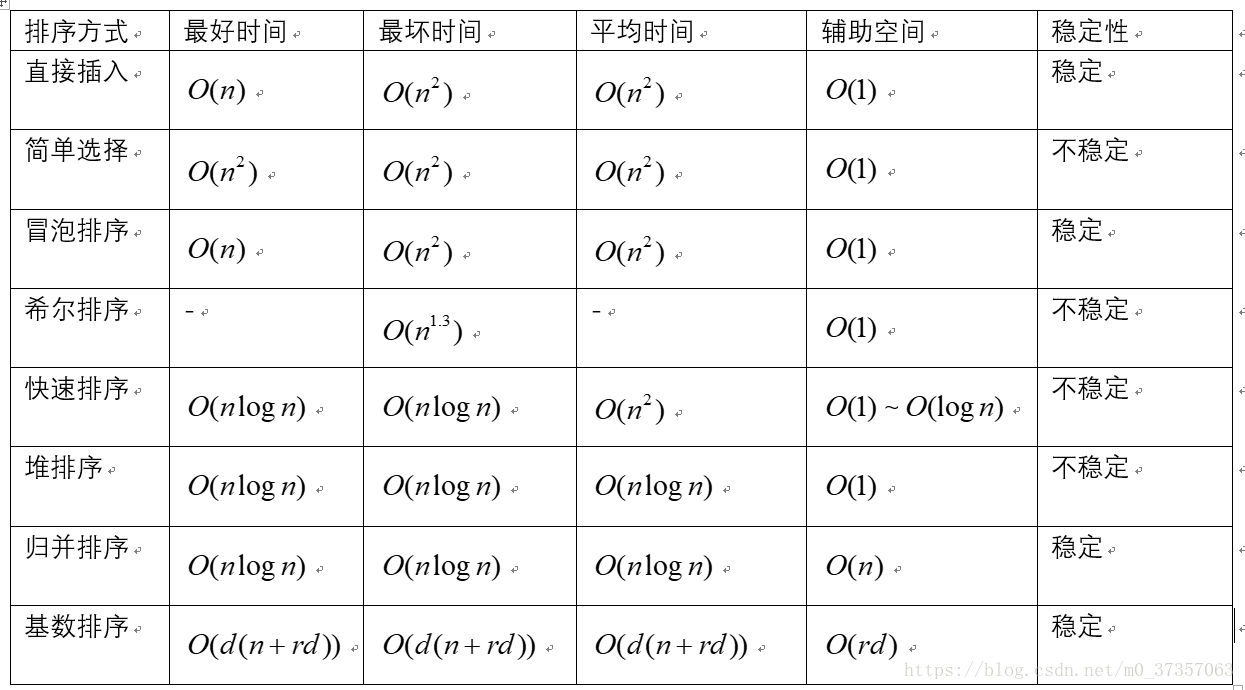
0.各种排序算法对比
1.冒泡排序
//冒泡排序,平均时间O(n^2),最好O(n),最坏O(n^2),空间复杂度O(1),不稳定
void BubbleSort(vector<int>& vec)
{
int temp;
int n = vec.size();
for (int i = 0; i < n - 1; i++)
{
for (int j = 0; j < n - i - 1; j++)
{
if (vec[j]>vec[j + 1])
{
swap(vec[j], vec[j + 1]);
}
}
}
}
2.选择排序
//选择排序,时间复杂度O(n^2),空间复杂度O(1),不稳定
void SelectSort(vector<int>& vec)
{
int temp, k;
int n = vec.size();
for (int i = 0; i < n - 1; i++)
{
k = i;
for (int j = i + 1; j < n; j++)
{//找出关键字最小的下标k
if (vec[j] < vec[k]) k = j;
}//for
if (k != i)
{
swap(vec[i], vec[k]);
}//if
}//for
}//SelectSort3.直接插入排序
//直接插入排序:最好时间复杂度O(n),平均时间复杂度O(n^2),最坏O(n^2),辅助空间O(1),稳定
//将一个记录插入到以及排好序的有序表中,从而得到一个新的,记录数增1的有序表
void InsertSort(vector<int>& L)
{//先将序列中的第一个记录看成有序子序列,然后从第二个记录起逐个进行插入,直至整个序列变成按关键字有序的非递减有序序列
if (L.size() < 2)
{
return;
}
int temp;
int j = 0;
for (int i = 1; i < L.size(); i++)
{
if (L[i] < L[i - 1])//需要将L[i]插入前面的有序子表L[0...i-1]中,L[0...i-1]已序
{
temp = L[i];//temp是哨兵,将L[i]暂时存下来
for (j = i - 1; j >= 0&&temp < L[j]; j--)
{
L[j + 1] = L[j];//记录后移
}
L[j + 1] = temp;//哨兵temp插入到正确的位置
}
}
}//InsertSort
/*
{ 49, 38, 65, 97, 76, 13, 27, 49 }; 0
{38,49,65, 97, 76, 13, 27, 49 }; 1 (整个排序过程为n-1趟插入)
{38,49,65, 97, 76, 13, 27, 49 }; 2
{38,49,65, 97, 76, 13, 27, 49 }; 3
{38,49,65,76,97,13,27,49}; 4
{13,38,49,65,76,97,27,49}; 5
{13,27,38,49,65,76,97,49}; 6
{13,27,38,49,49,65,76,97}; 7
*/
4.Shell排序(缩小增量插入排序)
//直接插入排序与希尔排序对比着看
//希尔排序,缩小增量排序,是对直接插入排序的改进,时间复杂度O(n^1.3),空间复杂度O(1),不稳定
void ShellSort(vector<int>& L)
{
int i, j, k, temp, dk;
int n = L.size();
k = L.size();//k=n元素个数
vector<int> delta;//增量序列数组
/*
从k=n开始,重复k=k/2运算,直到k等于1,所得k值的序列作为增量序列存入delta数组
*/
do{
k = k / 2;
delta.push_back(k);
} while (k >= 1);//最后一个增量必须是1!!
i = 0;
while ((dk = delta[i]) > 0)
{
for (k = delta[i]; k < n; k++)
{
if (L[k] < L[k - dk])//将L[k]插入到有序增量子表中
{
temp = L[k];//备份待插入元素,空出L[k]的位置!
for (j = k - dk; j >= 0 && temp < L[j]; j -= dk)
{
L[j + dk] = L[j];//寻找待插入位置的同时,将记录以dk为增量进行后移
}
L[j + dk] = temp;//找到待插入位置,插入temp
}//if
}
//每一次while循环排好一个增量的子序列!!
++i; //取下一个增量值
}//while
}//ShellSort5.归并排序
void Merge(int SR[], int TR[], int start, int mid, int end)
{//将有序的SR[start,m] 和 SR[m+1,end]合并成有序表TR[start..end]
int j, k;
for (j = mid + 1, k = start; start <= mid && j <= end; ++k)
{//将SR中的记录由小到大合并到TR中
if (SR[start] <= SR[j]) TR[k] = SR[start++];
else TR[k] = SR[j++];
}
if (start <= mid)
{//TR[k..end]=SR[start..mid] 将剩余的SR[start..mid]复制到TR
while (start <= mid)
{
TR[k++] = SR[start++];
}
}
if (j <= end)
{//TR[k..end]=SR[j..end] 将剩余的SR[j..end]复制到TR
while (j <= end)
{
TR[k++] = SR[j++];
}
}
}
void MSort(int data1[], int data2[], int start, int end)
{
int mid;
int *temp;
if (start == end) data2[start] = data1[start];
else
{
temp = new int[end - start + 1];//申请辅助空间
mid = (start + end) / 2; //将data1[start...end]均分为data1[start...mid] 和data1[mid+1...end]
MSort(data1, temp, start, mid);//递归地将data1[stard...mid]归并为有序的temp[start...mid]
MSort(data1, temp, mid + 1, end);//递归地将data1[mid+1...end]归并为有序的temp[mid+1...end]
Merge(temp, data2, start, mid, end);//将temp[start...mid]和temp[mod+1...end]归并到data2[start...end]
//delete temp; //有个bug :Heap block at 00F8D298 modified at 00F8D2CC past requested size of 2c
}
}//MSort
void MergeSort(int data[], int n)
{
MSort(data, data, 0, n - 1);
}//MergeSort
6.快速排序
/*对顺序表L的快速排序:*/
//一次划分,将枢轴记录放到最终有序表的正确的位置上!
int Partition(vector<int> &L, int low, int high)
{
int pivotkey = L[low];//设立枢轴记录,这里是这区间的第一个记录为枢轴记录。
/*枢轴记录的选择有三策略:1.选区间第一个元素;2.在区间中随机选一个元素;3.三者取中法(选区间
头尾和中间的三个元素中的中位数(中值)为枢轴记录,这样有利于应该关键字基本有序或已序的情况*/
while (low < high)
{//升序排序
while (low < high&&L[high] >= pivotkey)--high;
L[low] = L[high];
while (low < high&&L[low] <= pivotkey)++low;
L[high] = L[low];
}
L[low] = pivotkey;//枢轴记录归位
return low;//返回枢轴记录的位置
}
void QSort(vector<int>& L, int low, int high)
{//对顺序表L[low,...,high]的子序列做快速排序
int pivotLoc;
if (low < high) //长度大于1
{
pivotLoc = Partition(L, low, high);
QSort(L, low, pivotLoc - 1);
QSort(L, pivotLoc + 1, high);
}
}
void QuickSort(vector<int>& L)
{//对顺序表L做快速排序!
QSort(L, 0, L.size() - 1);
}
7.堆排序和优先队列
7.1堆排序
7.1.1初始建堆
初始序列{55,60,40,10,80,65,15,5,75}建立大根堆的过程如下图:
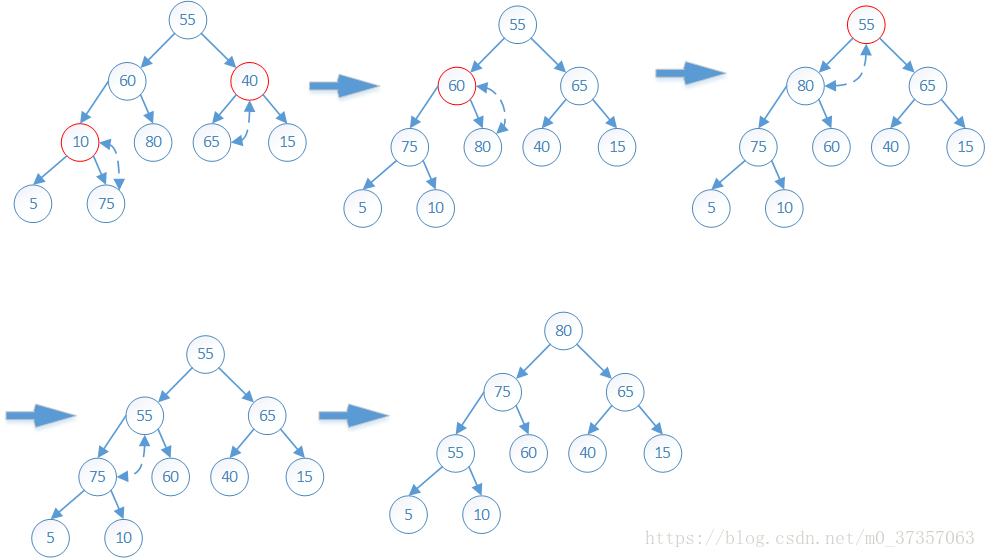
7.1.2 输出堆顶后调整为新堆
建好大顶堆,输出堆顶元素后,调整为新堆的过程:

/*
0
1 2
3 4 5 6
7
因为下标是从0开始的,所以:
i 号节点的左孩子节点编号2i+1 (如果存在的话)
i 号节点的右孩子节点编号2i+1+1(如果存在的话)
*/
/*
在对Ki为根的子树建堆的过程中,可能需要交换Ki和K2i(或K2i+1)的值,如此一来,
以K2i(K2i+1)为根的子树可能不再满足堆的定义,则应继续以K2i(或K2i+1)为根进行调整,
如此层层递推下去,可能会一直延伸到树叶为止,
这样就像过筛子一样,把最大的关键字一层一层地筛选出来,最后输出堆顶最大的元素!
*/
void HeapAdjust(HeapType& H, int s, int m)
{//本函数调整H[s]的关键字,使得H[s ... m]成为一个大顶堆(对其中记录的关键字而言)
int rc = H[s];
for (int j = 2 * s+1; j <=m; j*=2+1)//沿值较大的孩子结点向下筛选!
{//注意,H的下标从0计起,所以j是s的左子树根,j+1是s的右子树根
if (j < m && H[j] < H[j + 1]) ++j;//j为关键字较大的记录的下标,即j最终要指向s的值较大的孩子结点
if (!(rc < H[j])) break; //rc应插在位置s处,如果rc>=H[j],即s>=其左右孩子,则不需要作调整,跳出循环
H[s] = H[j];//如果s<(s的值较大的孩子j),则交换之,
s = j;//用s记录下待插入元素的下标
}
H[s] = rc; //将备份元素插入由s所指出的插入位置!
//这样写的巧妙就是将(s>=其左右孩子)和s<(s的值较大的孩子j) 这样两种情况都统一了起来
}//HeapAdjust
void HeapSort(HeapType& H)
{//对顺序表H进行堆排序,最后H升序有序
for (int i = H.size() / 2 - 1; i >= 0; --i)//把H[i,...H.size()-1]建成大顶堆
{//从最后一个非终端节点往回逐一调整,这个循环结束将建成一大顶堆!
HeapAdjust(H, i, H.size()-1);
}
for (int i = H.size() - 1; i > 0; i--)
{//将堆顶记录H[0]和当前未经排序的子序列H[1...i]中的最后一个记录交换
swap(H[0], H[i]);
HeapAdjust(H, 0, i - 1);//将H[0,i-1]重新调整为一大顶堆,即使得最大值放置于H[0]处
}
}//HeapSort
7.2利用建立堆实现一优先队列
typedef deque<int> HeapType;
//建立优先队列,key值大的优先级高:如key 1<2
/*这里存的是int型,按理来说应该存储自定义类的key-value对的,稍微改一下就行,
但基本要会写HeapAdjust()函数,和BuildHeap建堆的函数,以及稍微改一下BuildHeap成HeapSort()函数!
*/
class MyPriorityQueue{
private:
HeapType heap;
public:
void enQueue(int element)
{
heap.push_back(element);
//BuildHeap();//这里没必有进行排序,只需要再次建立堆即可
}
int deQueue()
{
if (heap.empty())
{
throw new std::invalid_argument("invalid_argument");
}
int ans= heap.front();
heap.pop_front();//这里为了方便从线性表的头部删除元素,使用了双端队列deque作容器
BuildHeap();
return ans;
}
void BuildHeap()
{
if (heap.empty())
{//空,不build
return;
}
else if (heap.size() == 1)
{//只有一个结点,也不build!
return;
}
else
{
for (int i = heap.size() / 2 - 1; i >= 0; --i)//把H[i,...H.size()-1]建成大顶堆
{//从最后一个非终端节点往回逐一调整,这个循环结束将建成一大顶堆!
HeapAdjust(heap, i, heap.size() - 1);
}
}
}
void HeapAdjust(HeapType& H, int s, int m)
{//本函数调整H[s]的关键字,使得H[s ... m]成为一个大顶堆(对其中记录的关键字而言)
int rc = H[s];
for (int j = 2 * s + 1; j <= m; j *= 2+1)
{//注意,H的下标从0计起,所以j是s的左子树根,j+1是s的右子树根
if (j < m && H[j] < H[j + 1]) ++j;//j为关键字较大的记录的下标,即j最终要指向s的值较大的孩子结点
if (!(rc < H[j])) break; //rc应插在位置s处,如果rc>=H[j],即s>=其左右孩子,则不需要作调整,跳出循环
H[s] = H[j];//如果s<(s的值较大的孩子j),则交换之,
s = j;
}
H[s] = rc; //这样写的巧妙就是将(s>=其左右孩子)和s<(s的值较大的孩子j) 这样两种情况都统一了起来,放在循环里面分情况写也是一样的!
}//HeapAdjust
void printEmelent()
{
for (auto ele : heap)
{
cout << ele << " ";
}
cout << endl;
}
};排序 内部排序 数据结构














 2059
2059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









