






一 简述
朴素贝叶斯分类法是基于贝叶斯定理和特征条件独立假设的分类方法,具体做法是:1)基于特征条件独立假设来学习输入/输出的联合概率分布;2)基于学习的模型,对给定的输入,利用贝叶斯定理求出后验概率最大的输出。它的思想很简单:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
二 原理
·基本方法
朴素贝叶斯法是典型的生成学习方法,先训练数据集学习联合概率分布P(X,Y)( 其中P(X,Y)=P(Y)P(X|Y) ),在求得后验概率分布P(Y|X)以判断分类。1)训练数据集学习联合概率分布P(X,Y)
若给定训练数据集
先验概率分布
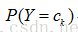
条件概率分布
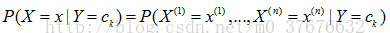
如果直接对条件概率分布估计的话,一个明显的问题就是指数级的参数估计。由此,朴素贝叶斯法对条件概率分布做了条件独立性的假设,认为用于分类的特征在类确定的情况下都是条件独立的,基于这一假设,模型包含的条件概率的数量大大减少,其学习与预测过程也大为简化。
条件独立性假设:
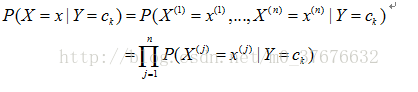
2)求得后验概率分布P(Y|X)以判断分类
在分类时,对于给定的输入x,由模型计算后验概率分布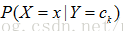
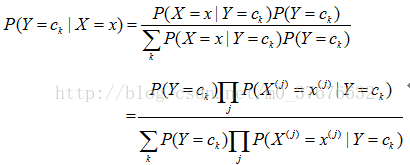
那么,朴素贝叶斯分类器可以表示为:
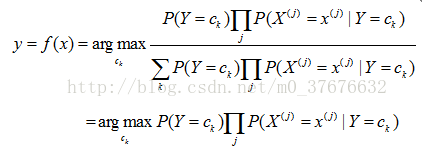
·参数估计
在训练数据集学习联合概率分布的阶段,即是估计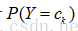
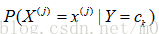
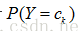 的极大似然估计
是:
的极大似然估计
是:

条件概率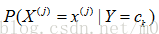
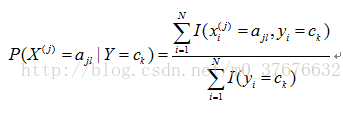
其中,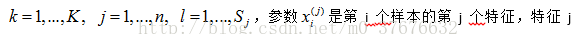
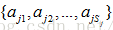
·参数估计中的问题
1)连续值问题
计算条件概率是朴素贝叶斯分类的关键性步骤,当特征属性为离散值时,可以统计训练样本中各个划分在每个类别中出现的频率来估计条件概率,但当特征属性是连续值的时,通常假定其值服从高斯分布(也称正态分布)。即:
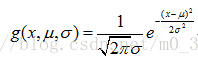
那么,
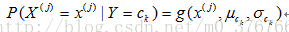
只要计算出训练样本中各个类别中此特征项划分的各均值和标准差,代入公式即可得到需要的估计值。
2)估计概率值为零问题
用极大似然估计时可能出现估计的概率值为零的情况,这时要采用 贝叶斯估计。 先验概率的贝叶斯估计是

条件概率的贝叶斯估计是
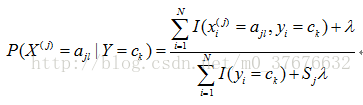
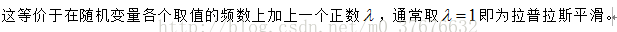
·朴素贝叶斯估计过程图
在博客http://www.cnblogs.com/leoo2sk/archive/2010/09/17/naive-bayesian-classifier.html中看到一个关于朴素贝叶斯分类器过程图及其各个过程,讲述的很清楚,特地转过来说明一下:

第一阶段——准备工作阶段,这一阶段的输入是所有待分类数据,输出是特征属性和训练样本,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段——分类器训练阶段,这个阶段的输入是特征属性和训练样本,输出是分类器,主要任务是生成分类器,即计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并记录结果。
第三阶段——应用阶段。这个阶段的输入是分类器和待分类项,输出是待分类项与类别的映射关系,主要任务是使用分类器对待分类项进行分类。
三 理解与应用
朴素贝叶斯分类时使用后验概率最大,这等价于0-1损失函数时的期望风险最小化。
0-1损失函数为:
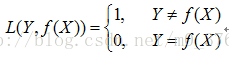
这时期望风险函数为(期望是对联合分布取的,由此取条件期望):

为使期望风险最小化,需要对X=x 逐个极小化,即:

也就是说,期望风险最小化准则等价于后验概率最大化准则。
朴素贝叶斯分类器在文本分类等问题上有着广泛应用,如在博客中https://zhuanlan.zhihu.com/p/22944688关于邮件分类的例子。
参 考:
李航 《统计学习方法》
https://zhuanlan.zhihu.com/p/22944688
http://www.cnblogs.com/leoo2sk/archive/2010/09/17/naive-bayesian-classifier.html
https://www.zhihu.com/question/20138060














 3557
3557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









