






1.作者介绍
王子谦,男,西安工程大学电子信息学院,2024级研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:1523018430@qq.com
黄浩磊,男,西安工程大学电子信息学院,2023级研究生,张宏伟人工智能课题组
研究方向:智能视觉检测与工业自动化技术
电子邮件:hhl57303@163.com
2.算法介绍
YOLO算法是经典的目标检测算法,其特点:
- 为单阶段(One-stage)目标检测
- 可进行实时检测
在YOLOv5版本,作者做出了如下改进:
输入端
- Mosaic数据增强:通过随机缩放、随机裁减、随机排布的方式进行拼接,有利于提升小目标检测性能。
- 自适应锚框计算:初始设定长宽的锚框,输出预测框,与真实框groundtruth进行比对,再反向更新,迭代网络参数。
- 自适应图片缩放:对原始图像自适应的添加最少的黑边,计算缩放比例,计算缩放后的尺寸,计算黑边填充数值。
Backbone
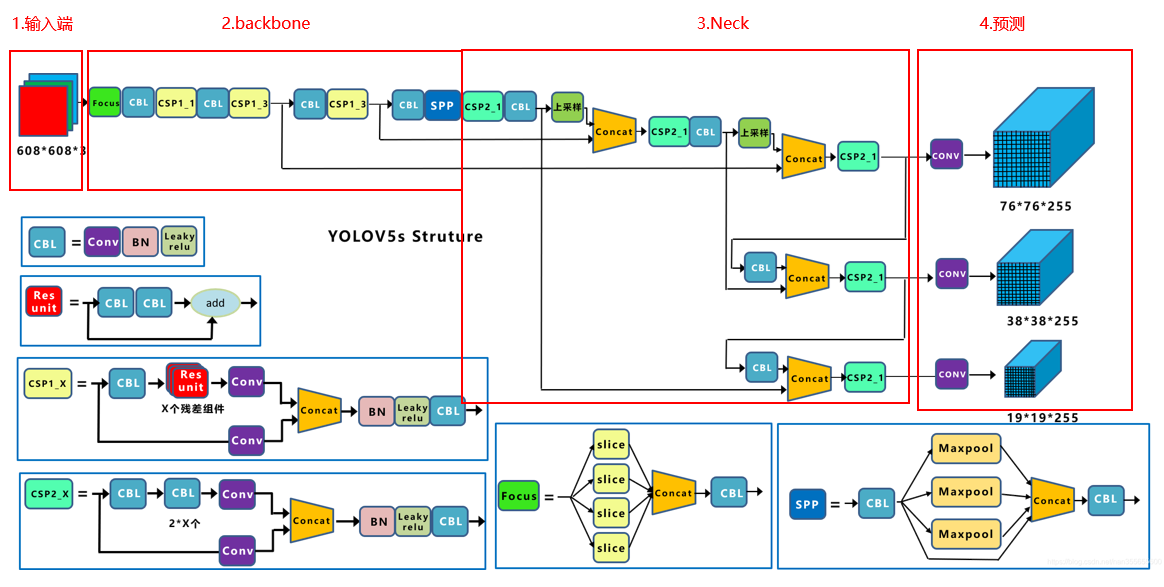
- Focus结构:对图片进行切片操作。Yolov5s的Focus结构最后使用了32个卷积核,其他版本的有所增加
- CSP结构:Yolov5中设计了两种CSP结构,以Yolov5s网络为例,CSP1_X 结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
Neck
Yolov4的Neck结构中,采用的都是普通的卷积操作。而Yolov5的Neck 结构中,采用借鉴CSPnet设计的CSP2结构,加强网络特征融合的能边。
输出端Head
- Bounding box损失函数:Yolov5中采用其中的CIOU Loss做Bounding box
的损失函数 - nms非极大值抑制:在同样的参数情况下,将nms中IOU修改成:DIOU_nms。对于一些遮挡重叠的目标,确实会有一些改进。
以下是YOLOv5的网络结构图,从结构上划分为四个部分
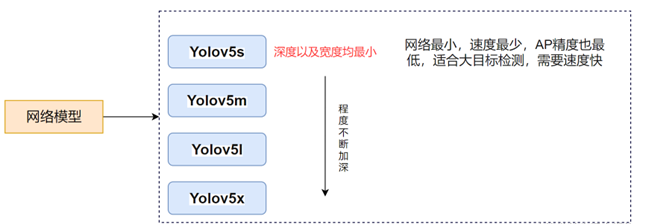
YOLOv5共推出了四个版本,分别是s、m、l、x版本,其中s版本网络深度最小,精度最低,适合大目标检测。本文中使用了YOLOv5模型。
3. 数据集介绍
该棉花成熟度检测数据集为个人标注的数据集,图片来源于农田实拍的棉花生长状况相片。
数据集标注类别分别有:‘缺陷开裂棉花-不可采摘’, ‘棉花花朵-不可采摘’, ‘完全裂开-可采摘’, '部分开裂-不可采摘’
数据集按照8:1:1比例划分为训练集、验证集、测试集。
train:4238张 val:529张 test:530张。

4.代码实现
项目结构
项目结构如图所示,YOLOv5项目高度功能化,相比于之前版本更适合个人进行研究学习。不同的文件和文件夹功能不一,下图中对重要文件进行说明

训练过程
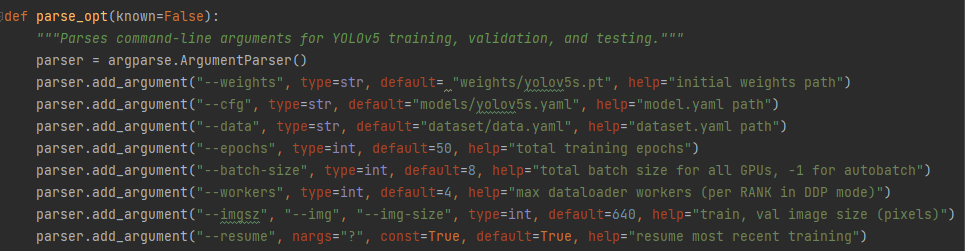
训练前需要在train.py中更改一些配置参数,在parse_opt中:
–weights :加载预训练权重,可以选择官方的s、m、l、x版本权重中选择,这里选择yolov5s.pt作为预训练权重
–cfg:加载网络构建的配置文件,同样选yolov5s的配置文件
–data:加载数据集配置文件,包含数据集地址,类别等参数
–epochs:训练的轮数,即模型将完整遍历数据集的次数
–batch-size:批次大小,即每次训练中处理的图片数量
–workers:数据装载时cpu所使用的线程数,一般选择2的n次方个
–imgsz:输入图像的尺寸,指定训练时图像的宽和高,默认为640×640
–resume:可更改以继续训练上次没训练完的进程
另外还有很多其他参数,但是大部分都不用修改。
训练结束后在run/train文件夹中生成训练结果,包括训练权重best.pt和last.pt,以及训练的配置和训练过程中的损失、精确率等值
检测过程
在detect.py中同样需要更改配置参数

选择权重为训练结果中的best.pt,数据为测试集的路径,图片大小为640×640
为了实现对棉花个数的识别,在detect.py中添加了 total_objects 变量来统计检测到的目标总数,在处理每个类别的检测结果时,累加目标数量到 total_objects。在处理完所有检测框后,使用 cv2.putText() 在图像左上角(10,30)位置添加显示目标总数的文本


检测结果
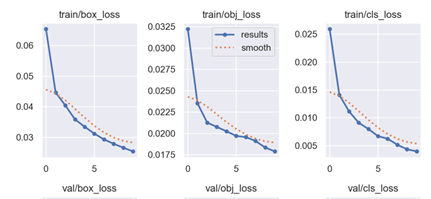
首先设置epochs为10进行一次训练
其训练时的损失函数如下,可以看到仍处于未收敛状态
训练结束后在验证集上进行测试,发现有一些缺陷的棉花并不能有效的检测出来

下图是采用此次训练权重在验证集上进行验证的统计结果,可以看出训练轮数低导致检测精确度并不高,对于缺陷棉花的检测更为明显。

设置epoch为50再次训练
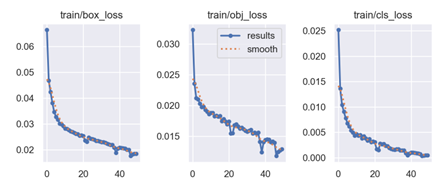
可以看出训练时的损失相比于之前更低了,而且也趋于收敛

在验证集上的检测效果也明显变好,对于不同类别的棉花可以识别出其状态

验证集检测精确度也有了一定提高,尤其对于难以检测的缺陷棉花,明显高于上次训练
下是进行推理测试时的部分结果


5. 问题与分析
问题一:torch.cuda.amp.autocast过时

torch从2.4及以后便不再支持torch.cuda.amp.autocast(args…),而环境中的版本是2.6.1、
解决方法:警告中说torch.cuda.amp.autocast(args...)该函数弃用了,用torch.amp.autocast(‘cuda’, args...)去替换,找到报错位置并替换。

问题二:opencv内存溢出


cv2.error: Caught error in DataLoader worker process 2.
cv2.error: OpenCV(4.7.0) D:\a\opencv-python\opencv-python\opencv\modules\core\src\alloc.cpp:73: error: (-4:Insufficient memory) Failed to allocate 12192768 bytes in function 'cv::OutOfMemoryError'
主要原因就是batchsize和worker设置的过大,原本batchsize为16,worker为8,分别更改为8和4后可正常运行,任务管理器显示内存和gpu资源占用也没有之前多了
项目源代码链接
通过网盘分享的文件:yolov5-master.rar
链接: https://pan.baidu.com/s/1v910uVfsASm8NvnsZzl9zg?pwd=yj3x 提取码: yj3x

















 922
922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









