






java解析xml分为两类,4种,分别为SAX解析,dom解析,jdom,dom4j.以下具体举例使用4种方式来实现对一个.xml文件进行解析:
有命名为dome.xml的文件,
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="1">
<name>java教程</name>
<price>89</price>
<language>英文</language>
<year>2005</year>
</book>
<book id="2">
<name>php教程</name>
<price>65</price>
<language>中文</language>
<year>2011</year>
</book>
<book id="3">
<name>c语言</name>
<price>33</price>
<language>中文</language>
<year>2015</year>
</book>
</books>
1.使用dom4j的方式来实现对dome.xml文件的解析:
DOM4J 是一个非常非常优秀的Java XML API,具有性能优异、功能强大和极端易用使用的特点,同时它也是一个开放源代码的软件。如今你可以看到越来越多的 Java 软件都在使用 DOM4J 来读写 XML,特别值得一提的是连 Sun 的 JAXM 也在用 DOM4J。
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.Iterator;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
public class dom4j_xml {
public static void main(String[] args) {
// TODO Auto-generated method stub
dom4j_xml a=new dom4j_xml();
a.DOM4J_xml();
}
public void DOM4J_xml() {
int book_index=0;
try {
SAXReader reader=new SAXReader();//创建解析对象
Document document=reader.read(new File("demo.xml"));//加载xml文档
Element book_root=document.getRootElement();//得到加载xml文档的根标签
Iterator iterator=book_root.elementIterator();//加载跟标签以下的所有标签,返回值是一个迭代器对象
while(iterator.hasNext()){//开始遍历,调用hasNext()的方法,判断是否有下一个
book_index++;
Element book=(Element)iterator.next();//获取根标签以下所有子节点,
List<Attribute> book_attr=book.attributes();//获取跟标签以下的子标签的属性值
for (Attribute attribute : book_attr) {//得到所有子标签的属性值进行遍历
System.out.println(attribute.getName()+":"+attribute.getValue());//得到属性名和对应的属性值,即key-value
}
Iterator book_node_iter=book.elementIterator();//获取根节点以下的子子节点,
while(book_node_iter.hasNext()){//遍历所有的子子节点
Element book_node=(Element)book_node_iter.next();//获取子子节点 Element
System.out.println(book_node.getName()+":"+book_node.getStringValue());
}//获取标签名和标签中的Text值
System.out.println("============第"+(book_index)+"本结束==========");
}
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
输出结果如下:
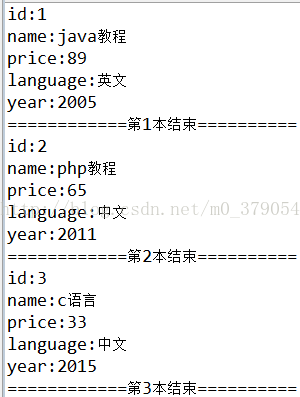
2.使用dom解析xml文件的方式:
为 XML 文档的已解析版本定义了一组接口。解析器读入整个文档,然后构建一个驻留内存的树结构,然后代码就可以使用 DOM 接口来操作这个树结构。优点:整个文档树在内存中,便于操作;支持删除、修改、重新排列等多种功能;缺点:将整个文档调入内存(包括无用的节点),浪费时间和空间;使用场合:一旦解析了文档还需多次访问这些数据;硬件资源充足(内存、CPU)。
import java.io.File;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class xml_dom {
public static void main(String[] args) {
xml_dom xml_dom1=new xml_dom();
xml_dom1.xml_dom_parse();
}
public void xml_dom_parse() {
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
try {
DocumentBuilder db=dbf.newDocumentBuilder();
Document docu=db.parse("demo.xml");
//获取所有的书籍节点
NodeList booklist=docu.getElementsByTagName("book");
for(int i =0;i<booklist.getLength();i++){
Node book_item=booklist.item(i);
System.out.println("第"+(i+1)+"本书");
NamedNodeMap node_att=book_item.getAttributes();//读取属性,并存在一个<span style="font-family: Arial, Helvetica, sans-serif;">NamedNodeMap中</span>
for(int j=0;j<node_att.getLength();j++){
Node node=node_att.item(j);
System.out.print(node.getNodeName()+":"+node.getNodeValue()+" ");
System.out.println();
}
NodeList book_child=book_item.getChildNodes();
for(int k=0;k<book_child.getLength();k++){
Node book_child_ele=book_child.item(k);
if(book_child_ele.getNodeType()==Node.ELEMENT_NODE){//如果没有会打印出很多空格,因为text也是一种节点类型,
//System.out.println(book_child_ele.getNodeName()+":"+book_child_ele.getFirstChild().getNodeValue());
这个就是采集到这个<name></name>中所有的所有的text
System.out.println(book_child_ele.getNodeName()+":"+book_child_ele.getTextContent());
}
}
System.out.println("以上就是第"+(i+1)+"本书");
}
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
输出结果如下:

3.使用jdom解析xml文件:
为减少DOM、SAX的编码量,出现了JDOM;优点:20-80原则,极大减少了代码量。使用场合:要实现的功能简单,如解析、创建等,但在底层,JDOM还是使用SAX(最常用)、DOM、Xanan文档。
import java.awt.print.Book;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.jdom.Attribute;
import org.jdom.CDATA;
import org.jdom.Document;
import org.jdom.Element;
import org.jdom.JDOMException;
import org.jdom.input.SAXBuilder;
import org.jdom.output.Format;
import org.jdom.output.XMLOutputter;
public class jdom_xml {
public static List<Books> books_list=new ArrayList<Books>();
public static void main(String[] args) {
new jdom_xml().JDOM();
}
public void JDOM() {
SAXBuilder builder=new SAXBuilder();
try {
Document document=builder.build(new FileInputStream("demo.xml"));
Element book_root=document.getRootElement();
//获去所有的书籍
List<Element> book_list=book_root.getChildren();
for (Element book : book_list) {
System.out.println("==========第"+(book_list.indexOf(book)+1)+"本书===========");
Books books=new Books();
List<Attribute> book_attr=book.getAttributes();
for (Attribute attr : book_attr) {
System.out.println(attr.getName()+":"+attr.getValue());
if(attr.getName().equals("id")){
books.setId(attr.getValue());
}
}
List<Element> book_children=book.getChildren();
for (Element element : book_children) {
System.out.println(element.getName()+":"+element.getValue());
if(element.getName().equals("year")){
books.setYear(element.getValue());
}else if(element.getName().equals("name")){
books.setName(element.getValue());
}else if(element.getName().equals("price")){
books.setPrice(element.getValue());
}else if(element.getName().equals("language")){
books.setLanguage(element.getValue());
}
}
books_list.add(books);
books=null;
System.out.println(books_list.size());
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (JDOMException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
运行结果如下:

4.使用SAX解析xml文件:
为解决DOM的问题,出现了SAX。SAX ,事件驱动。当解析器发现元素开始、元素结束、文本、文档的开始或结束等时,发送事件,程序员编写响应这些事件的代码,保存数据。优点:不用事先调入整个文档,占用资源少;SAX解析器代码比DOM解析器代码小,适于Applet,下载。缺点:不是持久的;事件过后,若没保存数据,那么数据就丢了;无状态性;从事件中只能得到文本,但不知该文本属于哪个元素;使用场合:Applet;只需XML文档的少量内容,很少回头访问;机器内存少;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.util.ArrayList;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SAXHandle extends DefaultHandler {
private int book_index=0;
public Books book;
String value;
ArrayList<Books> book_list=new ArrayList<Books>();
//标签开始时调用
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
// TODO Auto-generated method stub
super.startElement(uri, localName, qName, attributes);
if(qName.equals("book")){
book=new Books();
book_index++;
for(int i=0;i<attributes.getLength();i++){
//System.out.println(attributes.getQName(i)+":"+attributes.getValue(i));
if(attributes.getQName(i).equals("id")){
book.setId(attributes.getValue("id"));
}
}
}
}
//标签结束时调用
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
// TODO Auto-generated method stub
super.endElement(uri, localName, qName);
if(qName.equals("book")){
book_list.add(book);
book=null;
//System.out.println("---------"+(book_index)+"------结束------");
}else if (qName.equals("name")) {
book.setName(value);
}else if (qName.equals("language")) {
book.setLanguage(value);
}else if (qName.equals("year")) {
book.setYear(value);
}else if (qName.equals("price")) {
book.setPrice(value);
}
}
//读取标签内嵌内容
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
// TODO Auto-generated method stub
super.characters(ch, start, length);
value=new String(ch, start, length);
//if(!value.trim().equals(""))
//System.out.println(value);
}
}
在新建一个类SAX_xml生成SAXHandle的实例化对象
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.util.ArrayList;
import java.util.List;
import javax.swing.TransferHandler;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Result;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.sax.SAXTransformerFactory;
import javax.xml.transform.sax.TransformerHandler;
import javax.xml.transform.stream.StreamResult;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.AttributesImpl;
public class SAX_xml {
public void sax_xml(SAXHandle handler) {
SAXParserFactory factory= SAXParserFactory.newInstance();
try {
SAXParser parser=factory.newSAXParser();
parser.parse("demo.xml", handler);
List<Books> l = handler.book_list;
for (Books o : l) {
System.out.println(o);
}
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
SAX_xml sax=new SAX_xml();
SAXHandle handler=new SAXHandle();
sax.sax_xml(handler);
}
}
运行结果如下:

以上4种解析的实例各有优缺;














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









